


怎么办呢?这个时候就要借助AI了,也就是机器学习,让计算机通过学习足够数量的样本,根据数据中的特征构建模型,并利用此模型对新的情境给出判断和预测。

你可能会觉得有点意思了!更加有意思的是,你也可以通过机器学习的方法,利用Python里强大的scikit-learn包中的聚类学习工具,来迅速判定海量新闻的真假(而Atlas OS的云主机的使用能让整个过程轻松便捷)。
下面跟着视频或图文介绍来试试看!
一
数据和代码准备
二
环境搭建
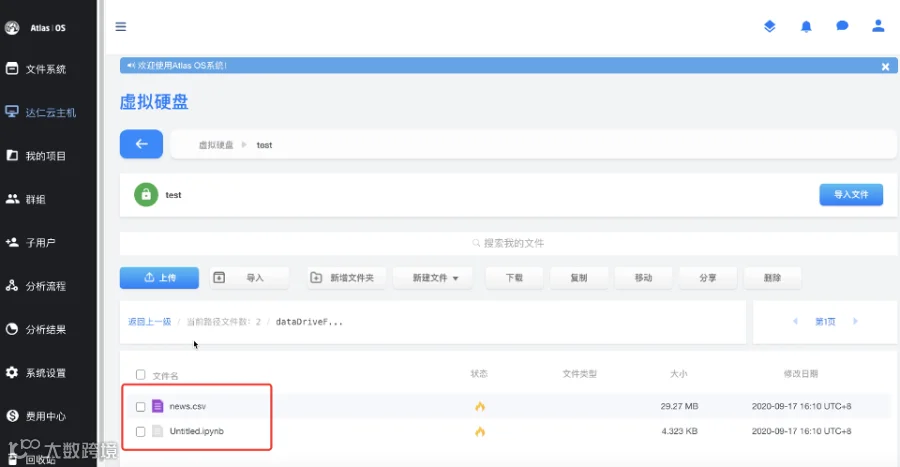
2,选择达仁云主机,新建一个虚拟硬盘,并上传新闻数据集文件news.csv,这是一个逗号分隔的纯文本文档,可以用任何文本编辑器打开查看;
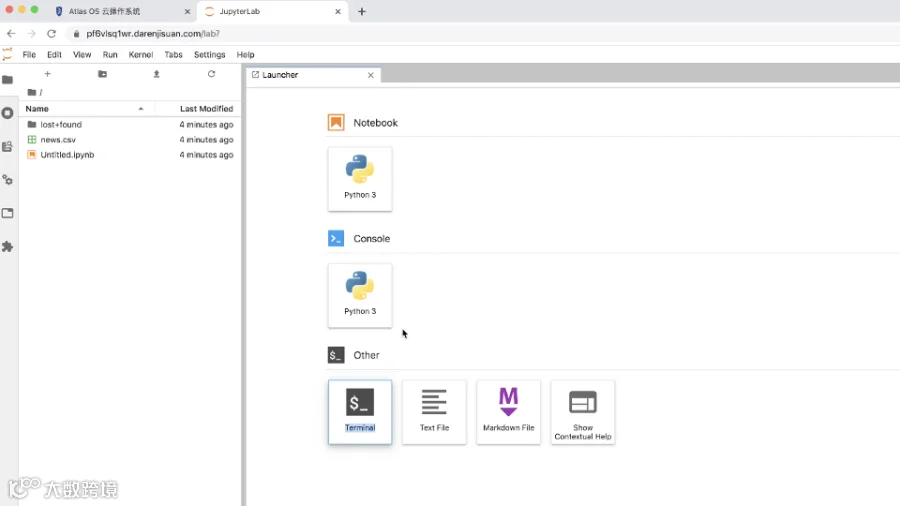
三
开始机器学习:真假新闻识别
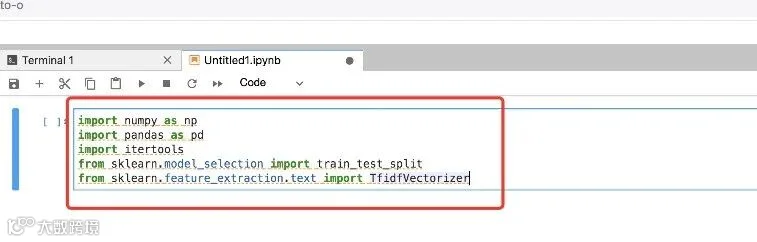
一个机器学习的项目里,我们需要将数据的一部分作为模型训练使用,一部分用来测试。这个例子里面我们可以看到test_size=0.001,也就是随机使用千分之一的数据用来测试,剩下的千分之九百九十九的其他数据用来训练模型。这个test_size参数可以根据需要调整。
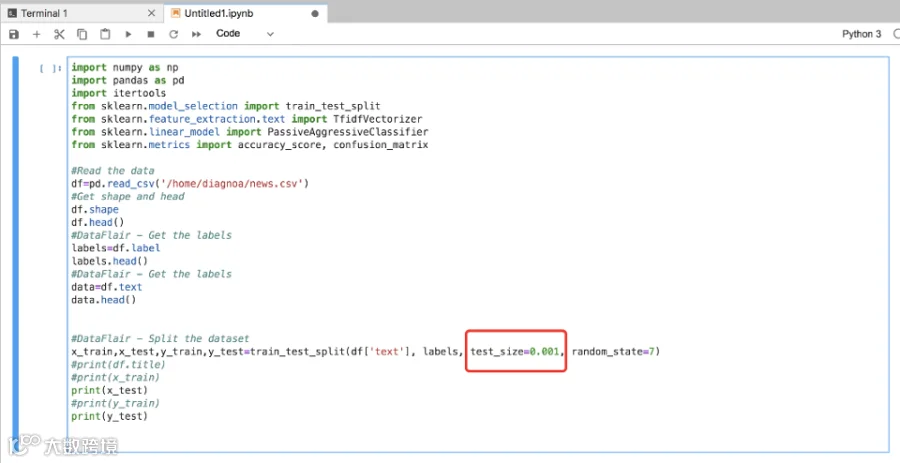
我们使用sklearnTfidfVectorizer函数,用TF-IDF词频-逆向文件频率方法进行文本特征提取,使用sklearn fit_transform 函数根据输入的训练数据,统计词汇词典并返回数据对象,生成文档稀疏矩阵,建立模型。
最后,我们使用sklearnPassiveAggressiveClassifier来做学习,这是一种增量学习算法(PA算法),即被动感知算法对测试数据进行预测,并统计结果。
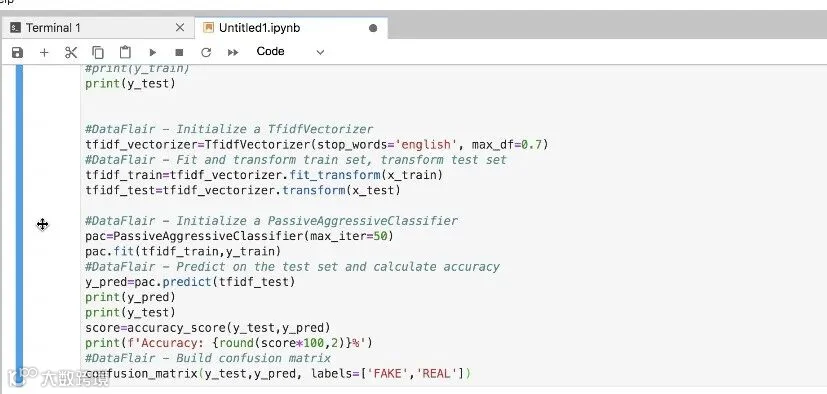
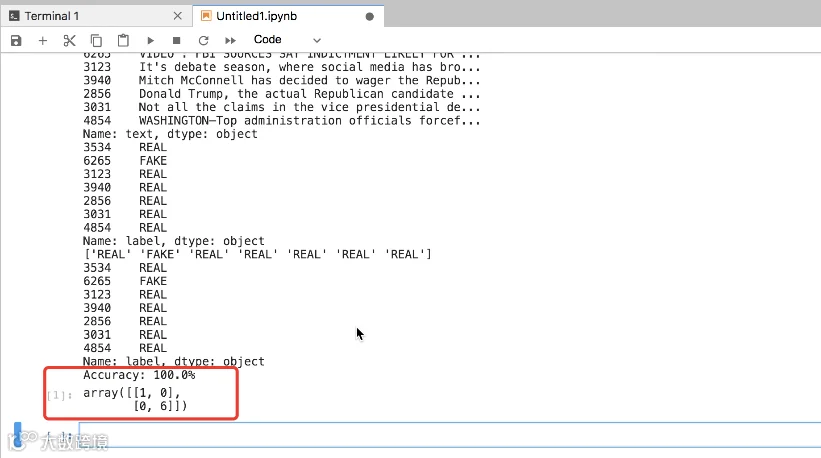
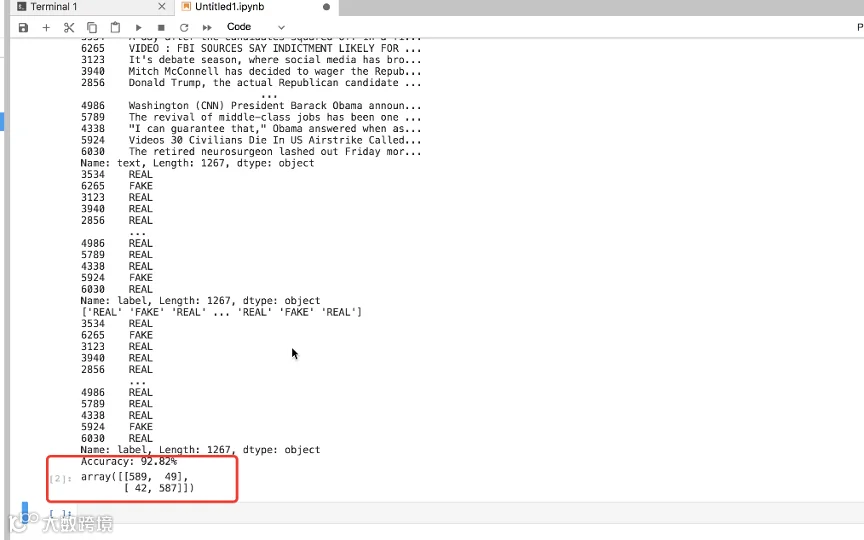
可以看到,在达仁云主机中开启环境,可以快速学习和实践Python的机器学习功能。我们通过这个简单的scikit-learn聚类学习项目,我们可以判断出90%以上的假新闻。那么在这个广告和假新闻满天飞的年代,也许我们后续可以逐步按这个方式过滤假新闻。
你学会了吗?想要马上练习!赶快登陆atlas.daren.io一键启用你的云主机吧,不仅是JupyterLab,达仁云主机还提供RStudio、Eclipse等多种主流开发环境,可选配置多达百余种,可选CPU涵盖1~96核,可选内存涵盖0.5~3TB,可选硬盘涵盖1-16TB,费用低至0.03元每小时起,浏览器中即开即用,这下再也不用为各种学习、开发、测试环境而苦恼了。
想了解更多新鲜实用的云计算和云数据分析工具,欢迎关注“Atlas OS”微信公众号,或联系达仁基算团队ddeng@daren.io。
长按二维码关注我们

微信公众号:Atlas OS
新浪微博:@达仁基算