

1. 引言
传统谱系学研究已实践了几个世纪,利用文献记录和口述历史追溯家族历史。直到最近,这些仍是联系远亲的唯一方法,但随着直接面向消费者的基因检测(direct-to-consumer genetic testing) 的出现,现在可以通过共享的DNA找到亲属。这使得成千上万因收养、遗弃、匿名配子捐赠、父母身份误认等原因失去生物学身份的个人得以寻回其遗传传承。最近,这些相同的工具已被用于在三十多起执法案件中识别犯罪嫌疑人的DNA,其中仅有一部分已公开宣布。
2. 数据生成
传统的法医DNA分析使用常染色体短串联重复序列(short tandem repeat,STR) 从约20个位点生成身份图谱,而遗传谱系学则使用分布在常染色体上的数十万个单核苷酸多态性(single nucleotide polymorphism,SNP)。参与遗传谱系学的个体已通过直接面向消费者的基因检测公司(如23andMe或AncestryDNA)进行了DNA测试,这些公司使用微阵列对多达约100万个SNP进行基因分型。直接面向消费者公司从唾液收集盒或口腔拭子获取DNA,因此始终有大量高质量的单源DNA可供使用。而法医DNA样本通常只含有少量降解的DNA,并且可能与一个或多个其他个体的DNA混合。先前的研究已表明微阵列基因分型对法医样本有效且准确,Parabon自2015年起已将其用于案件工作,即使对于低至1纳克DNA的法医样本也能获得高基因分型检出率(表2)。Parabon还发现,只要目标个体至少占混合物的40%,并且有第二个贡献者的单源参考样本,就可以准确地从两人混合物中解卷积微阵列数据。
表2. Parabon用于遗传谱系案件工作的超过250个法医DNA样本及其微阵列基因分型检出率的总结。
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Parabon目前的案件工作使用Illumina CytoSNP-850K芯片,这是一种现成的芯片,包含Ancestry.com、FamilyTreeDNA和MyHeritage使用的OmniExpress芯片上超过98%的SNP。23andMe以前也基于OmniExpress设计芯片,但后来转向较小的定制芯片,与其他直接面向消费者公司的芯片重叠较少。对于执法案件,提取的DNA样本在CLIA认证的实验室进行处理,数据安全地上传到Parabon。
3. 从DNA确定亲缘关系
只要有足够的SNP,就有可能确定两个人之间的亲缘关系程度,这是由预期的共享DNA量定义的,而不是减数分裂的次数(图1)。
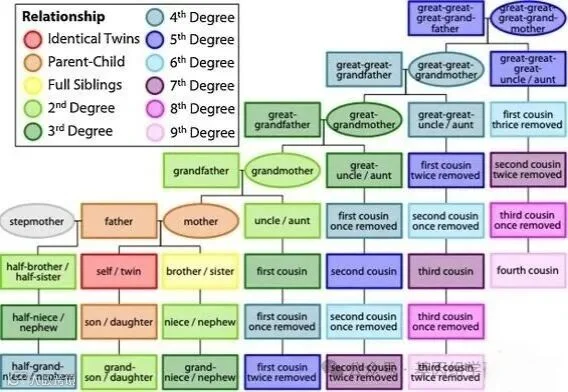
图1. 显示亲缘关系程度的谱系图,由预期的共享DNA量定义。 每种关系都是相对于红色的“自身/双胞胎”框来定义的。(关于本图例中对颜色的引用,读者可参考本文的网络版)。
虽然之前已经提出了几种关系推断方法,但23andMe是首家引入一种准确、可扩展方法的直接面向消费者公司,用于从常染色体SNP推断两个DNA样本的大致亲缘关系。每个人有22条常染色体(“常染色体”)各两份拷贝,一份遗传自母亲,一份遗传自父亲。常染色体并非完整地从每个亲代遗传;相反,每个亲代自身的成对染色体会随机重组为一条新的染色体传递给子女。虽然重组是随机发生的,但染色体上彼此更接近的核苷酸更可能一起遗传,而相距较远的核苷酸则更可能被重组分开。两个核苷酸之间发生重组的概率被量化为它们的遗传距离,以厘摩(cM)为单位测量,1厘摩等同于1%的重组概率。
遗传谱系学并非简单地查看共享SNP的总数,而是利用了这样一个事实:重组会随着世代更替打破长段的共享DNA,因此亲缘关系更近的人会共享更长的同源血统(identical-by-descent,IBD)DNA片段(“片段”)(图2)。发生的重组事件越多,共享的IBD片段就越短,因此以厘摩为单位的IBD片段数量和长度可用于近似估计亲缘关系程度。
图2. 单个染色体上DNA片段的遗传。 所有22条常染色体上共享片段(阴影框)的长度相加,得出共享DNA总量。
为了检测IBD片段,遗传谱系算法在基因组中搜索两个个体在每个SNP上至少共享一个等位基因的区域。要计入统计,这些片段必须包含最少数量的SNP(通常约500个)并且超过一定长度(通常5-7厘摩),这可以筛除大部分因偶然性而非共同血统而共享的片段。当对所有常染色体求和时,IBD共享的DNA量与两个个体之间的亲缘关系程度高度相关,因此更远的亲属往往共享更少的DNA(表3)。然而,由于重组的随机性,相同亲缘关系程度的亲属共享的DNA量可能存在很大差异,并且这种变异随着重组事件的增加而增加,以至于约10%的三代表亲(third cousin)和约50%的四代表亲共享不到可检测的IBD片段。
表3. 具有每种关系的个体对所共享的DNA范围。 虽然给定关系中的大多数个体对落在更窄的范围内,但这些值代表已观察到的全部范围。
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4. 遗传谱系数据库与遗传隐私
直接面向消费者基因检测公司的私有数据库规模激增,目前AncestryDNA拥有近1500万人,23andMe拥有近1000万人,MyHeritage和FamilyTreeDNA合计约350万人。AncestryDNA和23andMe独立维护其数据库,执法机构无法访问,因为提交样本的唯一途径是通过口腔拭子或唾液收集盒。MyHeritage和FTDNA都允许上传来自其他来源生成的数据,但执法机构使用任一数据库都需要获得公司的书面许可,以及MyHeritage的法庭命令或FTDNA的“所需法律文件”。
另一方面,GEDmatch并非直接面向消费者公司。它由Curtis Rogers和John Olson于2010年创建,作为一个公共数据库,来自不同测试公司的个体可以通过从直接面向消费者公司的网站下载原始数据并上传到公共数据库来比较他们的DNA。在金州杀手嫌疑人通过秘密使用GEDmatch被识别后,该网站的管理员决定明确允许执法机构使用。他们在网站首页发布了通知(图3),并更新了服务条款,声明执法机构可以且正在使用GEDmatch来识别暴力犯罪(定义为凶杀或性侵)的遗骸和犯罪者。新用户和现有用户在使用网站前都必须查看这些新条款并决定是否接受。遗传谱系学的批评者认为,许多在此更新前加入网站的人可能没有考虑到,他们寻找亲属的愿望可能导致发现自己是与犯罪DNA相关者的亲属,并导致该亲属被捕。确实,他们中的一些人可能仍不知道新的警告,而由他人上传数据或在该网站不活跃的个人可能没有查看新条款以决定是否同意。然而,即使在实施这些新条款之前,GEDmatch的条款也已明确指出,设置为“公开”的任何数据集都可被任何人搜索。法律通常允许将向公众开放的信息用于刑事调查。用户可以轻松地将数据设置为“私有”,使其对所有搜索查询隐藏,或完全删除。因此,像GEDmatch这样的公共数据库中的DNA数据文件来自于那些主动从私人DNA检测公司网站下载其数据、将信息上传到公共网站、审阅了允许执法机构使用的服务条款,并选择同意将其数据用于公开比较的个人。
图3. GEDmatch在金州杀手调查中被公开使用后在其主页发布的通知。
此外,在遗传谱系搜索过程中,不会向执法机构披露敏感的遗传信息,因为无法访问GEDmatch用户的原始遗传数据。原始遗传数据可能包含与健康相关的敏感信息,这类私人遗传信息应受保护。遵循这一原则,GEDmatch不显示或提供原始基因型的下载。GEDmatch仅对样本进行比较,返回共享DNA片段的长度和染色体位置,这些信息用于确定个体之间的大致关系。同样,从犯罪现场遗弃DNA获得并用于遗传谱系学的数据不会暴露给其他用户,并且可以防止出现在搜索结果中(此选项对所有用户可用)。在Parabon,遗传数据保存在只有授权员工才能访问的加密服务器上,公司的GEDmatch账户只能由生物信息学团队和首席遗传谱系学家CeCe Moore访问。这些事实缓解了许多围绕遗传谱系学的隐私担忧,因为个人可以控制其数据是否被用作执法调查的一部分,且敏感的原始数据不会被访问。
与执法数据库的家族搜索不同,法律不要求任何人必须向遗传谱系数据库贡献数据,且样本不由政府机构持有。为GEDmatch做出贡献的个人被明确警告,刑事调查员以及谱系爱好者都能够对其数据进行比对。如果他们选择参与,就没有理由认为执法机构不能使用这些信息。这些与家族搜索的重要区别,反对将家族搜索政策(例如将分析限制在调查末期)自动应用于遗传谱系学。这两种技术完全独立;在一些遗传谱系学案件中曾进行过家族搜索,而在其他案件中则没有。公众强烈支持使用遗传谱系学调查暴力犯罪:在金州杀手被捕后,GEDmatch的参与者数量显著增加,最近的一项调查也显示出压倒性的公众支持。
5. 数据库搜索
GEDmatch的一对多查询将目标DNA与数据库中所有公开数据进行比较,返回一个共享最多常染色体DNA的个体列表。每个“匹配项”包括该个体的姓名或别名、与其GEDmatch账户关联的电子邮件地址,以及他们选择共享的任何单倍群或族谱信息(图4)。
图4. 来自GEDmatch一对多比较的前五个结果, 已移除潜在的身份识别信息(试剂盒编号、姓名和电子邮件地址)。
然后,可以对每个匹配项运行一对一的比较,使用更精确的算法查看共享片段的长度和染色体位置。将共享DNA量与参考数据进行比较,可以得出未知个体与匹配项之间的关系属于每种亲缘关系程度的概率。例如,共享100厘摩的匹配项可能属于第5度到大于第8度之间的任何关系,最可能是第6度。
然而,还存在额外的复杂性。首先,除了多种可能的亲缘关系程度外,每个程度还包含许多必须考虑的关系类型(例如,年龄相近的第5度亲属可能是第二代堂表亲、第一代两隔代表亲或半第一代隔代表亲)。其次,每种关系共享的DNA量在不同人群中存在差异。由少数个体建立的群体可能具有较低的遗传多样性和较高的背景亲缘关系或内婚制。在此类群体中,具有给定关系的个体将共享比其他群体显著更多的DNA,以至于即使是非常远的表亲也能共享大量DNA。内婚制表现为大量匹配项,每个匹配项共享许多小片段,表明这些片段实际上是从远祖遗传而来。另一个挑战是谱系塌陷,即相同的家族在历史上多次联姻,这可能会夸大其后代之间共享的DNA量。
6. 案件匹配结果
Parabon超过250起执法案件样本中,超过80%在三代表亲水平或更近(大于60厘摩)内有匹配项,具有欧洲血统的个体由于在遗传谱系数据库中占比过高,成功率更高(图5A)。欧洲血统通过Snapshot DNA表型预测进行评估,该方法从七个大陆群体(非洲、中东、欧洲、中亚/南亚、东亚、大洋洲和美洲原住民)推断个体的遗传混合。在此分析中,如果样本至少具有80%的欧洲血统,则被视为“欧洲”样本。请注意,提交给Parabon的执法案件主要来自北美机构,来自其他地区的样本由于参与直接面向消费者基因检测和使用GEDmatch的比例较低,匹配概率可能较低。
图5. 对于Parabon超过250个执法样本,(A)GEDmatch一对多匹配项中最高匹配项处于每种亲缘关系程度的频率,以及(B)样本获得每种评估等级的频率。 报告了欧洲样本、非欧洲样本和所有样本的结果,以及迄今为止已侦破(即已确认身份)的案件的结果。亲缘关系程度仅基于共享DNA量,而非通过谱系确定的真实关系:父母-子女(大于3300厘摩)、全同胞(2200-3300厘摩)、第2度(1300-2200厘摩)、第3度(650-1300厘摩)、第4度(340-650厘摩)、第5度(200-340厘摩)、第6度(90-200厘摩)、第7度(60-90厘摩)、第8度(30-60厘摩)、大于第8度(小于30厘摩)。
最高匹配项的亲密度并非是决定遗传谱系学可行性的唯一变量。全面的评估必须不仅考虑最接近的匹配项,还要考虑支持性匹配项的质量以及关于每个匹配项的可用信息量。例如,如果最高匹配项的父母身份未知和/或来自记录不可用的国家,进展可能会很困难。Parabon按照主观等级评估每个样本:(1)身份识别的可能性非常高(例如,父母-子女匹配),(2)身份识别的可能性高,(3)身份识别的可能性中等,(4)身份识别的可能性低但可能生成可操作信息,(5)不太可能生成可操作信息。评估并不保证特定结果,而是旨在帮助机构决定如何进行。迄今为止,约80%的欧洲样本和约60%的非欧洲样本被评估为可行(评估等级1-4)(图5B)。
重要的是,一个样本今天没有足够有希望的匹配数据,并不意味着它永远不会有。每天都有数百名新个体将数据上传到GEDmatch,随着数据库的增长,具有近亲匹配的样本比例将会增加。因此,Parabon每周监测所有未侦破案件的新匹配项。
7. 谱系学研究
虽然围绕遗传谱系学的大多数讨论集中在数据库匹配上,但绝大部分遗传谱系学工作发生在生成匹配列表之后。美国的许多记录对公众开放,并已被编入可通过订阅访问的可搜索数据库。例如,Ancestry.com提供了一种访问大量记录集合的机制,例如截至1940年的人口普查、许多州的重要记录(出生、结婚、死亡)、社会保障死亡索引以及Newspapers.com。一些Ancestry.com用户也创建并共享公共族谱,但这些可能包含错误,因此必须审慎检查。人员搜索数据库和公共社交媒体也可用于帮助确定家庭结构。在某些情况下,执法机构可能会被请求协助此项研究,利用其更大的记录访问权限。
先前对MyHeritage直接面向消费者数据库的分析表明,约60%的北欧血统个体会在100厘摩或更近距离内有一个匹配项。通过模拟,研究者表明,如果知道未知个体的性别、100英里内的地理位置以及5年内的年龄,通常可以从单个三代表亲水平的匹配项中识别出未知个体。然而,除了执法案件中通常无法获得如此详细的人口统计信息外,这还假设给定一个三代表亲匹配项,可以直截了当地获得该匹配项在该距离上的所有亲属的完整列表(研究者确定此数量约为850人,不包括半血亲)。实际上,将一个匹配项扩展为一个亲属列表需要大量的工作。
首要任务是明确识别每个匹配项,这本身就相当困难。尽管GEDmatch显示与每个匹配试剂盒关联的姓名和电子邮件地址,但用户可以选择使用别名或匿名电子邮件地址,并且试剂盒有时由匹配者本人以外的人管理。此外,即使用户关联了真实姓名,也可能是常见的(例如John Smith),这会增加识别难度。因此,匹配项的初步识别既关键又具有挑战性,通常需要相当的遗传谱系学技能和创造性解决问题的办法,例如破译姓名首字母、从其他可识别的匹配项推断身份、以及当试剂盒由他人管理时推断DNA来自谁。尽管通过给定的电子邮件地址联系匹配项可能有助于识别甚至产生族谱信息,但Parabon很少直接联系匹配项,以尽量减少调查涉及的人数并降低惊动嫌疑人的风险。比三代表亲更近的匹配项只有在获得调查机构许可后才会联系,并且机构可以选择自行联系。任何联系都会说明问题与执法调查有关(不提供案件细节),并告知个人他们可以自由选择参与与否。如果个人要求不参与,则不再联系。
一旦匹配项被识别,必须将他们的族谱构建到与未知个体可能存在的共同祖先集合。回溯到感兴趣的共同祖先的世代数由匹配项关系距离决定,但由于估计通常不针对单一关系,族谱往往需要构建到比这些程度所暗示的更久远。回溯构建族谱需要传统的谱系研究:梳理公共记录以确定每一代父母的的身份。
然而,记录并非总是可用——并非所有美国州都维护准确且公开的出生索引,许多家族可以追溯到来自其他国家的移民,而那里的记录不易获取,等等。此外,生物学族谱通常与文献记录的族谱不匹配,原因包括父亲身份误认、未记录的收养、父母身份未知等,处于这些情况的个体在遗传谱系数据库中的比例过高。姓氏和拼写在世代更替中也经常发生变化,进一步使分析复杂化。
8. 后裔研究
一旦确定了可能的共同祖先,就必须将族谱向前构建(“后裔研究”或“逆向谱系学”)以阐明未知个体的可能身份(图6)。
图6. 遗传谱系研究产生的假设族谱。 给定GEDmatch中的一个匹配项(橙色星),族谱向后构建到可能的共同祖先(橙色),然后向前构建(蓝色)以确定未知个体的可能身份(本例中,从“第二代堂表亲”中确定)。(关于本图例中对颜色的引用,读者可参考本文的网络版)。
未知个体所源自的可能祖先有时可以通过基因组血统来缩小范围(例如,如果族谱是北欧的,但未知个体有25%来自另一群体的血统,遗传谱系学家可以在可能的祖父母中寻找与来自该祖先群体的人结婚的一位)。X染色体上的共享DNA也可以缩小匹配项之间可能路径的范围,因为男性仅从其母亲继承X-DNA。因此,如果一名未知男性与一个匹配项共享X-DNA,他们必须通过他的母亲相关,并且他们之间的路径不能连续经过两名男性。当可用时,Y染色体和线粒体单倍群也可以缩小可能性范围,因为它们分别直接从父亲传给儿子和从母亲传给子女。因此,个体与其母系共享一个线粒体单倍群,而男性与其父系共享一个Y单倍群。
匹配项之间的DNA共享也可以用于缩小未知个体在族谱中的位置。如果匹配项彼此之间不共享任何DNA,他们很可能与该个体的不同家庭分支相关,遗传谱系学家随后可以寻找两个匹配项家族之间的交汇点(“三角定位”),形式可以是结婚生子或非婚生育(图7)。虽然对于一个单一匹配项可能有数百或数千名第二代或第三代表亲,但通常只有少数个体是与多个匹配项在恰当距离上具有表亲关系的人。
图7. 两个假设族谱之间的三角定位。 给定GEDmatch中两个彼此无关的匹配项(橙色星),为每个构建族谱,然后寻找交汇点(绿色),形式为婚姻或非婚生育。此交汇点的子女与两个匹配项都相关,而族谱中的所有其他个体只与一个匹配项相关。(关于本图例中对颜色的引用,读者可参考本文的网络版)。
9. 缩小可能身份范围
一旦候选个体被识别,遗传谱系学家可以使用多种因素来纳入或排除他们,此外还有传统的调查信息,例如与犯罪现场或受害者的关联。性别可从DNA得知,一些年龄信息可能可用——对于身份不明的遗骸,可以估算年龄;对于犯罪者,至少他们必须活着并且身体有能力实施犯罪。该个体也必须在特定时间处于特定地点,这可能意味着他或她住在附近。虽然GEDmatch匹配项可能分布在美国各地甚至全世界,但有时可以专注于迁移到相关地点附近的特定家庭分支。
Parabon的遗传谱系学家也使用Snapshot DNA表型预测在个体中进行优先排序,并确认或排除假设。个体的眼睛颜色、头发颜色和皮肤颜色通常可以从入案照片、年鉴照片或社交媒体中确定,并与预测进行比较。全同胞无法使用遗传谱系学区分,因为他们与匹配项具有所有相同的谱系关系。然而,如果他们在表型上存在差异,这可用于在他们之间进行优先排序。同样,如果谱系研究指向一个表型与预测不符的个体,这可能促使继续研究,而高度相似性则有助于证实身份识别。
未知个体身份可被缩小范围的程度因案件而异。在最佳情况下,可以通过与多个家庭分支的匹配项,自信地识别出单个个体或一组同胞。更常见的是,存在多个符合现有信息的表亲(特定共同祖先集合的后代)。然后可以通过进一步研究、传统调查和/或针对性的亲属成员亲缘关系测试来跟进这些线索,以更精确地将未知个体定位在族谱中。Parabon的Snapshot亲缘关系推断工具使用全基因组SNP数据来预测个体之间的精确亲缘关系程度,直至第6度亲属。使用基于数千个已知关系参考对象构建的机器学习模型(machine learning model),Snapshot预测一对个体属于每种亲缘关系程度的概率。置信度使用最可能程度的概率以及在交叉验证中为该程度计算的精确度来计算。
10. 执法线索
在长达数十年的悬案调查中,可能在找到犯罪者之前调查了成百上千人。遗传谱系学提供了一种有效缩小调查范围的手段,通常能缩小到仅少数个体。包含在遗传谱系分析中的可能亲属数量取决于匹配项的数量和距离。即使匹配项都是远亲,并且由于共同祖先在许多代之前而必须构建庞大的族谱,经验丰富的遗传谱系学家也可以在匹配项之间进行三角定位,以确定最有希望的家庭分支,并限制不必要的族谱构建工作。只要有足够的三角定位和时间,线索数量可以缩减为一对夫妇的后代。
然而,无论识别多么有把握,仅靠遗传谱系学无法以100%的确定性证明身份。总是存在微小的可能性,即未知个体可能曾被收养或遗弃,其存在可能不为家庭所知,也未通过官方记录揭示。因此,遗传谱系学线索必须通过对目标人物的STR图谱与犯罪现场样本的STR图谱进行直接DNA比较来验证。正是这种传统的法医DNA匹配被用于起诉。
11. 案例研究
以下案例研究展示了遗传谱系学如何协助调查人员识别悬案调查中的嫌疑人。仅包含调查机构批准公开发布的信息,因此一些案件细节(例如DNA样本来源、确切的GEDmatch匹配信息)已被模糊处理。
11.1. 案例研究#1:华盛顿州斯诺霍米什县;31年悬案(双尸案)
本案例研究展示了理想的遗传谱系学案件,其中有近亲匹配项和清晰的家族关联指向唯一的结论。然而,即使是看似简单的案件也需要大量的研究和专业知识来识别并应对混淆因素,例如父母身份未知和误认。
11.1.1. 犯罪
1987年,一对年轻的加拿大情侣Jay Cook(20岁)和Tanya Van Cuylenborg(18岁)乘坐一辆面包车从加拿大不列颠哥伦比亚省前往美国华盛顿州。在购买了一张前往西雅图的渡轮票后,他们再无音讯。几天后,Tanya的尸体在树林的沟渠中被发现,又过了几天,Jay的尸体和面包车在两个不同的地点被找到。获得了未知嫌疑人(“对象”)的DNA证据。
11.1.2. GEDmatch
有两个大约在第5度亲属水平的匹配项,外加更多更远的匹配项。前两个匹配项之间没有共享DNA,这意味着他们很可能与对象的不同家庭分支相关。
11.1.3. 族谱
使用人口普查记录、重要记录、报纸档案、公共“人员搜索”数据库、公共社交媒体数据和公共族谱,为两个关键匹配项构建了回到其曾祖父母及更早的族谱。接下来,进行了后裔研究,追溯每组祖先的后代,以确定是否能找到他们之间的交汇点。
在匹配项#2的曾祖父母的一个孙女与匹配项#1的曾祖母的一个儿子之间找到了一个三角定位的婚姻。广泛的研究揭示,这个儿子采用了他的继父的姓氏,最初掩盖了他与匹配项#1的真实关系。因此,这段婚姻的子女是匹配项#1的半第一代隔代表亲,同时也是匹配项#2的第二代堂表亲。虽然这两种关系都是第5度,但考虑所有可能的关系类型至关重要,因为半血亲关系相当普遍。在这些祖先的后代中没有发现其他婚姻。这段婚姻只有一个儿子,William Earl Talbott II,因此他是已知的唯一可能携带来自两个匹配项家族这种混合DNA的男性(图8)。
图8. 斯诺霍米什县治安部门在宣布逮捕William Earl Talbott II时发布的匿名族谱。 该树显示了Talbott先生(嫌疑人)和两个用于确定其身份的GEDmatch匹配项(表亲)的位置。
Talbott先生从未因需要向数据库提交DNA的犯罪而被捕。他与受害者没有已知关联,也没有理由被列入调查人员的关注范围。他的表型与Snapshot的预测相符,但在没有其他信息将其与犯罪联系起来的情况下,这不足以将其识别为嫌疑人。
11.1.4. 解决
基于遗传谱系学提供的线索,侦探们能够从Talbott先生丢弃的杯子中收集DNA,使用传统的STR分析显示,该DNA与犯罪现场的DNA匹配。他被逮捕,目前正在等待审判。
11.2. 案例研究#2:华盛顿州塔科马;32年悬案(凶杀案)
使用文献资料在匹配项之间进行三角定位有时是不可能的。除了能够坚持不懈地研究记录和细致地构建族谱外,本案例研究还展示了遗传谱系学家必须如何创造性地思考可能的假设来解释现有数据。
11.2.1. 犯罪
12岁的Michella Welch于1986年3月26日失踪。她带着两个妹妹去了华盛顿州塔科马的Puget公园,然后骑自行车回家做午餐,而她的妹妹们在附近玩耍。当妹妹们回到公园时,发现了一个装着她们午餐的棕色纸袋,但Michella不见了。到下午3点10分,警官们到达公园并开始搜寻失踪的女孩。一只追踪犬在晚上11点30分左右找到了她的尸体。她遭到殴打和性侵,死于颈部割伤。
11.2.2. DNA
另一名塔科马年轻女孩Jennifer Bastian大约在同一时间也被杀害,调查人员长期以来认为是一个人犯下了这两起罪行。仅在1986年,两起案件就投入了超过10000小时的调查时间。最近的DNA测试显示,犯罪是由不同的男子实施的,但两个DNA图谱均未在CODIS中匹配。
11.2.3. 遗传血统
预测对象主要为北欧血统,同时具有少量但显著的北美原住民混合(约10%)。
11.2.4. GEDmatch
两个最高匹配项不共享DNA,表明他们很可能与对象的不同家庭分支相关。
11.2.5. 族谱
为两个最高匹配项构建了回到其曾曾祖父母及更早的族谱,并进行了广泛的后裔研究,但未发现两个家族之间有文献记载的交汇点。分析人员识别出一对兄弟,他们是匹配项#1的表亲,1986年时居住在距离犯罪现场几英里范围内,并且在他们的家族树的不同分支上有两位北美原住民曾曾祖父母,这与对象的预测血统一致。然而,对象与匹配项#1共享的DNA量仅为预期的表亲关系的一半左右,并且应该存在一个连接这些表亲与两个匹配项的家族交汇点。
当家族通过DNA连接但在文献上没有交汇点时(例如通过结婚证或出生证明),解释可能是父亲身份误认:来自每个家族的一对个体育有一个孩子,但真实的生物学父亲未被记录。通过人口普查记录研究,发现两个匹配项的亲属在其中一个表亲的祖先受孕时住在同一个小镇上。这是发现的这些家族之间唯一的地理交汇点。基于共享的DNA量,假设匹配项#2的亲属是该表亲祖先未被记录的生父(图9)。在此假设下,这些表亲实际上将是匹配项#1的半表亲,这与共享DNA量相符。他们与匹配项#2的亲缘关系也在恰当的遗传距离上。
图9. 在塔科马案件中被确定为相关人员的一对匹配项#1的表亲的谱系图, 显示了匹配项#1的亲属与匹配项#2的亲属之间明显的父亲身份误认。
11.2.6. 解决
遗传谱系分析识别出一对可能是对象的兄弟,两人都从未因需要提交DNA到数据库的犯罪而被捕。警官们最终得以跟踪其中一位兄弟,Gary Charles Hartman,进入一家餐厅,在那里获取了他使用并丢弃的餐巾纸。传统的STR分析显示,餐巾纸上的DNA与犯罪现场发现的DNA匹配。在Michella Welch被发现死于华盛顿州公园三十多年后,调查人员宣布他们已逮捕了她谋杀案的嫌疑人。Hartman目前正在等待审判。
11.3. 案例研究#3:近40年悬案(凶杀案)
当GEDmatch中没有足够强的匹配项来完全缩小大型族谱的可能分支时,案件不能总是仅靠遗传谱系学有效解决。如果找不到匹配项家族之间的交汇点,对象的可能身份数量可能非常庞大。然而,正如本案例研究所展示的,如果匹配项的家族成员愿意合作,针对性的亲缘关系测试可以快速纳入或排除家族树的不同分支,从而得出少量被纳入的个体。由于在本调查中最终找到了嫌疑人的近亲,为保护其隐私,未包含此案的细节。
11.3.1. GEDmatch
对象的两个最高匹配项都在第6-8度亲属范围内,并且彼此之间没有共享DNA,这意味着他们很可能与对象的不同家庭分支相关。此外还有一些更远的匹配项。
11.3.2. 族谱
为两个最高匹配项构建了回到其曾曾祖父母的族谱,但未发现两个家族之间有交汇点。对象很可能是匹配项#1的某对曾曾祖父母的曾孙或曾曾孙,但没有三角定位,无法进一步缩小其身份范围。Parabon建议进行更多研究,以识别可能迁移到犯罪地区附近的家族分支,以及对最高匹配项家族成员进行针对性的亲缘关系测试。
11.3.3. 亲缘关系测试
调查机构从匹配项#1父系一方的一位表亲那里获得了自愿的口腔拭子样本,从中提取DNA,进行基因分型,并与对象进行比较。Snapshot亲缘关系推断预测此人与对象无关,因此匹配项#1的父系家族很可能可以被排除(假设文献记录的家族关系是正确的)。然后,调查机构从匹配项#1母系一方的一位表亲那里获得了自愿的口腔拭子样本,预测该表亲以94.2%的置信度为对象的第3度亲属(第一代堂表亲或遗传等效关系)。
11.3.4. 针对性族谱
分析人员为亲缘关系测试者的每位母系姑姨和叔伯的配偶构建了回到其曾曾曾祖父母的族谱。确定其中一位叔伯的妻子是对象许多更远匹配项的远亲。这种三角定位意味着这对夫妇的一个男性子女最有可能是对象,因为他会与两个匹配项家族相关——匹配项#1的第二代隔代表亲(第6度亲属)以及远匹配项#1-7的远亲(范围从第三代隔代表亲到第五代隔代表亲)(图10)。

图10. 在通过针对性亲缘关系测试及随后与远匹配项的三角定位缩小了可能指向对象的分支后,为匹配项#1的家族构建的谱系图。
重要的是,除非这些家族树之间存在额外的独立交汇点,否则识别出的相关人员是唯一与这两个家族都相关的个体。这些子女在案发时年龄也合适,住在附近,并且所有人的表型似乎都与Snapshot预测一致。
11.3.5. 解决
遗传谱系分析识别出一组可能是对象的兄弟,他们中没有人曾因需要提交DNA到数据库的犯罪而被捕。警官们最终将调查范围缩小到其中一位兄弟,并使用传统的STR分析将其DNA与犯罪现场DNA匹配。他已被逮捕并正在等待审判。
12. 结论
遗传谱系学被称为“2018年对犯罪科学的最大贡献”,并正在迅速改变悬案调查的面貌。即使对于完全未受关注或早已死去的犯罪者,只要有犯罪现场的DNA,就可能通过遗传谱系学识别他们。重要的是,遗传谱系学在现行案件中与在悬案中一样具有产生线索的强大能力。事实上,它最近被用于识别一起仅发生在三个月前的性侵案的犯罪者,并且他已认罪。调查人员现在可以获得创新的法医DNA技术,能够产生重要的新线索并防止案件悬而未决,而不是等待多年过去且所有其他线索都已穷尽。展望未来,遗传谱系学有潜力显著减少北美未侦破悬案的数量,同时降低案件悬而未决的比率。
本文转载自 基因组学研究前沿 衷心感谢本篇文章的原创者,让知识得以广泛传播。谢谢您的付出!