

NVIDIA英伟达 800G InfiniBand
和以太网连接人工智能布线指南
目录
1.7.每个场景的收发器选项
和端口拆分连接
要阅读以下表格,请遵循示例:
示例1:在场景2,用例B中,使用表8,图中左侧的800G-2xDR4、MMS4X00-NS通过2个MPO-8/12 APC连接,可以连接到两个OSFP光模块MMS4X00-NS400,从而在右侧形成两个独立的400G连接。
示例2:在场景4,用例B中,使用表9,图中左侧的800G-2xDR4、MMS4X00-NS通过2个MPO-8/12 APC连接,可以利用Y型线束连接到四个200G-DR4、QSFP112、MMS1X00-NS400,从而在右侧形成四个独立的 200G连接。
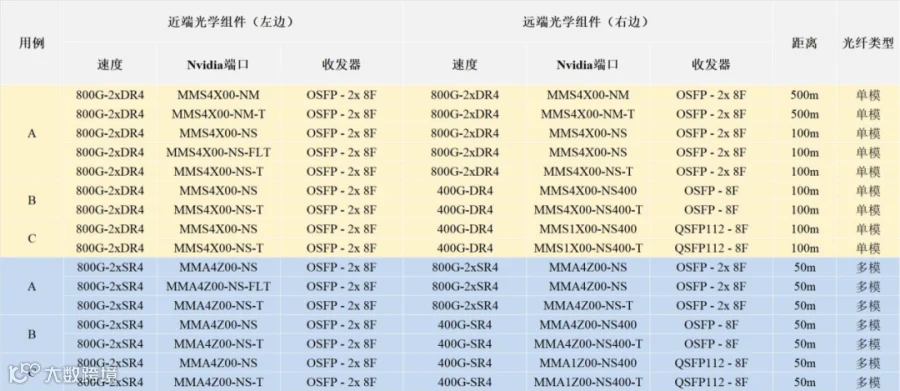
表8. 场景1和2中用例A到C适用的收发器
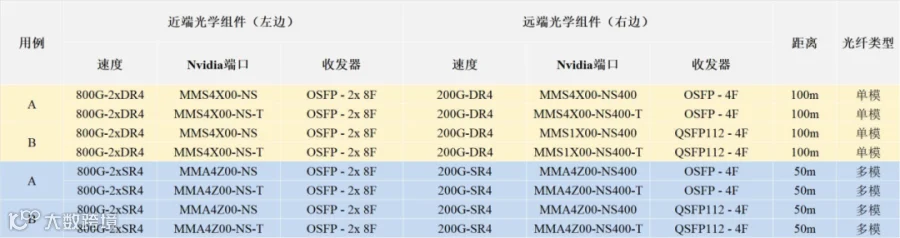
表9. 场景3和4中用例A到C适用的收发器

表10. 场景5和6中用例A到C适用的收发器

2.NVIDIA DGX SuperPOD
布线架构参考指南
在本节中,我们将回顾如何连接NVIDIA DGX SuperPOD。虽然本指南使用NVIDIA DGX H100作为参考,但重要的是要注意,类似的布线组件和基础设施也可用于涉及DGX B200和DGX GB200的应用。每个 POD的具体考虑将取决于个别客户的设计需求。
DGX SuperPOD由一定数量的可扩展单元(SU)组成,每个SU包含一定数量的节点(服务器)。此配置决定每个POD的GPU总数。SU是SuperPOD的构建模块。
POD也可以被称为集群,这取决于每个客户的偏好。了解POD或集群的大小将决定InfiniBand叶交换机、 InfiniBand骨干交换机和InfiniBand核心交换机所需的数量,这一点至关重要。基于该配置,我们可以计算所需的光缆或连接数量。
在图7中,如果我们以一个包含32个可扩展单元的中型集群或POD为例,这相当于1,024个节点或服务器,等同于8,192个GPU。这个设置将需要一个POD中有256个IB叶交换机、256个IB主干交换机和128个 IB核心交换机。我们将在整个文档中以这个POD大小作为参考。请注意,小型、中型或大型的分类并不是由NVIDIA定义的,但我们将在本指南中将其作为参考。
“光缆数量”这一列显示了连接系统所需的单个MPO-8/12 APC连接的数量。例如,要将每个节点(服务 器)连接到IB叶交换机,我们将需要8,192个MPO-8/12 APC连接。要将IB叶交换机连接到IB主干交换机,我们将需要额外的8,192个MPO-8/12 APC连接。最后,要将IB主干交换机连接到IB核心交换机,我们还需要另外8,192个MPO-8/12 APC连接,总共在整个POD中需要24,576个MPO-8/12 APC连接。
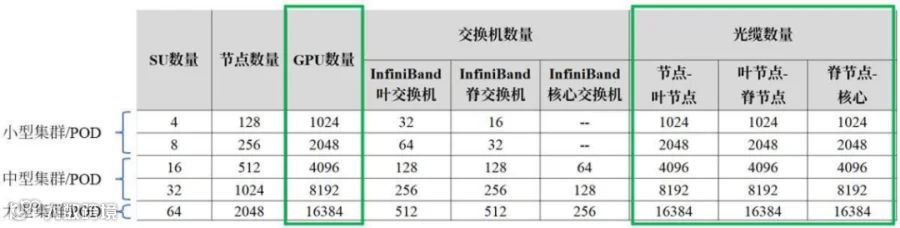
图 7. SuperPOD组件计数

2.1. 了解DGX-H100节点 (服务器 )
的计算网络连接
NVIDIA DGX-H100节 点 具 有 InfiniBand计算网络、InfiniBand存储网络、带内管理网络和带外管理网络的连接接口。
本架构指南的重点将集中在InfiniBand计算结构上。这种结构允许在每个节点上连接 4个双端口OSFP,总计8个400G连接。这些连接使用单模或多模 MPO-8/12 APC连接器 进行连接,如图 8所示。
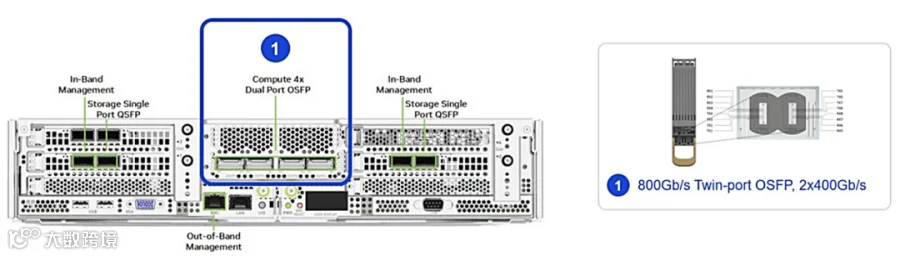
图8. DGX H100 CPU托盘的背面及其连接方式

2.2. 了解Quantum-2 9700
NDR IB交换机
Quantum-2交换机支持32个OSFP双MPO-8/12 APC端口。这意味着每台交换机最多可以提供64个 400Gbps的单端口。
图9展示了交换机级别端口映射的示例,用户可以在整个文档中将其作为参考。请注意,这只是客户进行端口映射的一种方法。
由于Quantum-2交换机将在网络中作为叶节点、脊节点或核心节点等不同角色进行部署,端口分配可以按照图9中建议的方法进行交换机间的连接。
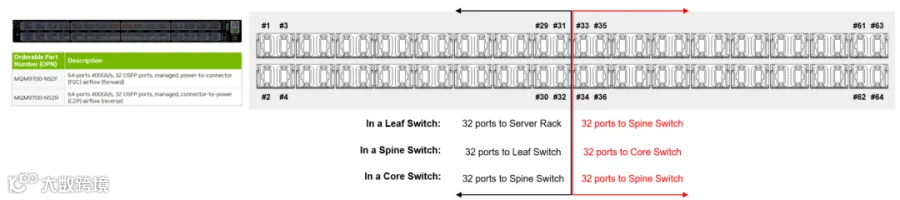
图9. Quantum-2交换机端口映射示例
需要注意的是,位于Quantum-2交换机底部端口的OSFP光模块将会倒置,从而使端口连接方向相反,如图10所示。在这个示例中,我们可以看到,双端口1提供了连接X和Y,而倒置的双端口2则提供了连接Y和X。区分这一点的物理方法是观察两个光模块的散热片,它们将呈相对的方向。
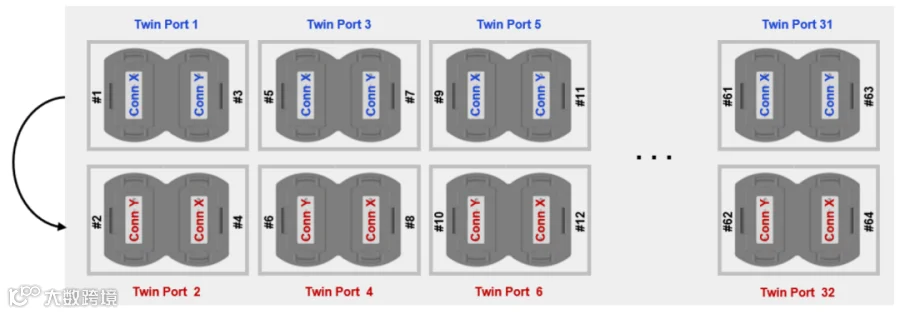
图 10. 双光模块端口考虑

2.3. 了解SuperPOD的构建块——
可扩展单元的概念
该系统建立在可扩展单元(SU)的构建块上,每个单元包含32个DGX H100系统,允许快速部署各种大小的系统。
每个SU包含256个GPU,分布在8个机架中的32个DGX H100系统上。每个可扩展单元(SU)有8个叶交换机。
该网络架构经过轨道优化,即来自每个节点的具有相同端口号的主机通道适配器(HCA)连接到同一个叶节点交换机。这意味着所有服务器的端口号1连接到叶节点交换机1,端口号2连接到叶节点交换机2,以此类推。
网络架构使用了Quantum-2 9700 InfiniBand交换机和800Gbps双OSFP光模块构建。
图11展示了基于以上信息的中间机架布局及其相关的计算网络组件。需要注意的是,还可以实现其他类型的布局。因此,在设计阶段与Corning工程团队保持密切联系至关重要,以验证您的设计选择的最佳布线方案。
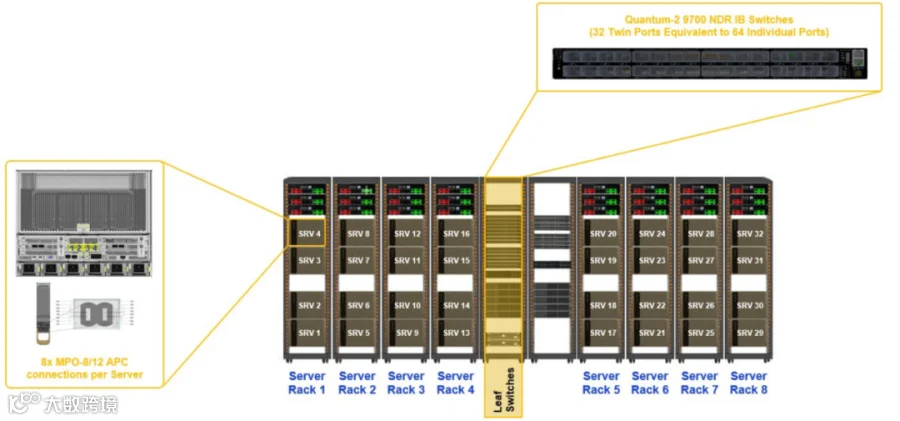
图11. 可扩展单元内的计算结构组件

2.4. 在NVIDIA DGX SuperPOD
中实现布线场景
为了便于识别构建AI/ML集群时使用的不同布线组件,康宁将在本指南中使用三个级别的连接。这些级别和交换机数量是基于32可扩展单元集群或POD的示例:
A级-服务器到叶节点的布线;
B级-叶节点到脊节点的布线;C级-脊节点到核心层的布线。

2.4.1 A级 -服务器到叶
节点的布线
一个可扩展单元可以通过节点(服务器)和叶节点交换机之间的点对点连接来布线(见图1),其中至少有两种布线产品选项可供选择(见图12)。在一些特定的定制设计中,也可以在可扩展单元级别实施结构化布线(见图2)。
第一种方法是使用256根独立的8芯跳线来创建每个光模块的连接。第二种方法是使用8束跳线。束状跳线由一组8芯MPO-8/12 APC跳线组成,作为一个256芯的单元,并包裹有阻燃网套,选择哪种方法将取决于客户设计的具体要求。无论选择哪种方法,我们将总共连接256个MPO-8/12 APC端口到叶节点交换机。
在本例中,交换机采用中间机架布局(见图12)。先前,我们描述了计算网络架构为轨道优化设计,共有 8条轨道。这些轨道对应于每台服务器的8个MPO-8/12 APC连接。在接下来的示例中,我们将使用图12和图13中所示的颜色标记来指示每条轨道连接。
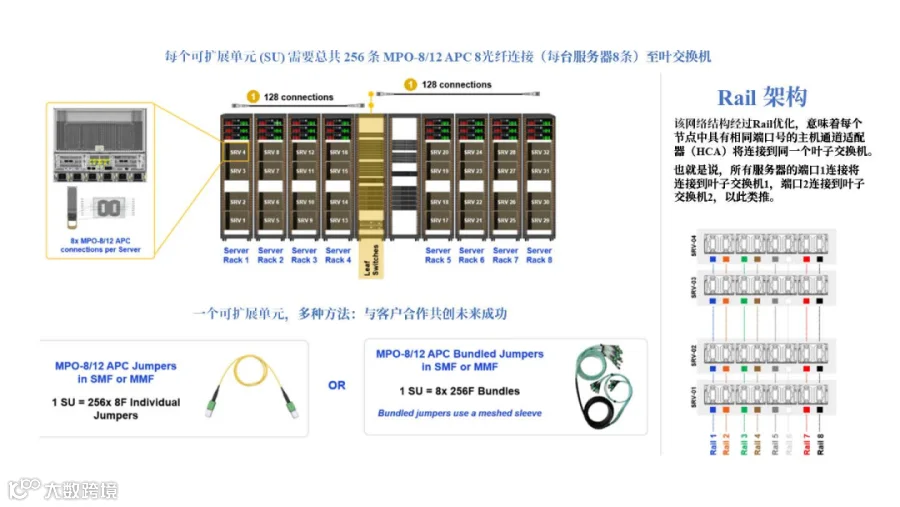
图12. A级 - 服务器到叶节点布线,描述连接数量和两种产品方案
对于A级布线,我们将使用束状跳线展示从服务器机架到位于可扩展单元中间机架(MOR)的InfiniBand叶节点交换机的连接。如果选择使用单根跳线,则可以按照轨道映射进行布线。
在图13的左侧,我们可以看到一个包含4台服务器的服务器机架,每台服务器对应其各自的轨道。在右侧,是叶节点交换机机架,内含8台叶节点交换机,每个交换机对应一个轨道。众所周知,这些Quantum-2交换机支持32个双MPO-8/12 APC端口,这意味着每台交换机可以支持多达64个独立连接。

图13. A级 - 服务器到叶节点布线,使用束状跳线的点对点连接,基于32个可扩展单元群/POD的示例
布线通过每个服务器机架的一条束状跳线来执行,将每台服务器中相同颜色的所有轨道连接到相应颜色的叶节点交换机。在此示例中,每台服务器的轨道8(黑色轨道)被分配到叶节点08交换机的端口1至4。在一个可扩展单元中共有8个服务器机架,轨道8将按照图9所示的映射完成叶节点08的前32个端口连接,而剩余的32个端口连接将被路由到脊节点交换机。这个过程会对每个服务器机架和轨道重复,直到可扩展单元内的所有连接完成。

后台留言联系我们,获取更多详细信息
未完待续![]()
相关阅读
