

NVIDIA NVL72 GB200/GB300系统:
InfiniBand和以太网连接解决方案(五)
目录
2.7.NVL72 GB300 集群
到目前为止,我们探讨并了解了GB200集群的架构和部署。现在,让我们探究下GB300集群的关键方面,重点介绍它们与GB200系统的区别及它们的构建。
主要区别在于GPU连通性和数据速率:
· GB200集群采用NVIDIA Grace-Blackwell GPU,具备400G NDR连通性,专为单平面拓扑进行了优化。
· GB300集群采用最新的NVIDIA Grace-Blackwell GPU,具备800G XDR连通性,支持双平面和四平面拓扑,可实现更高的可扩展性和带宽。
本节将从较高层次探究实现GB300集群部署所需的关键功能、网络设计和模块化可扩展单元(SU)。有关以太网和InfiniBand实现的详细信息,请分别参阅第2.7.1节和第 2.7.2节。

2.7.1.NVL72 GB300 以太网
GB300以太网计算网络旨在为NVIDIA NVL72系统中的GPU提供高性能连接,采用Spectrum-4以太网交换机实现可扩展性、低延迟无阻塞通信。以下是部署此架构时需要考虑的各个事项:
· 模块化可扩展单元(SU)
- 每个可扩展单元(SU)由两个GB300 NVL72机架组成,每个机架含72个GPU(见图33)。
- 可扩展单元(SU)旨在实现快速部署和无缝扩展,以适应需要更多资源的大型系统部署需求。
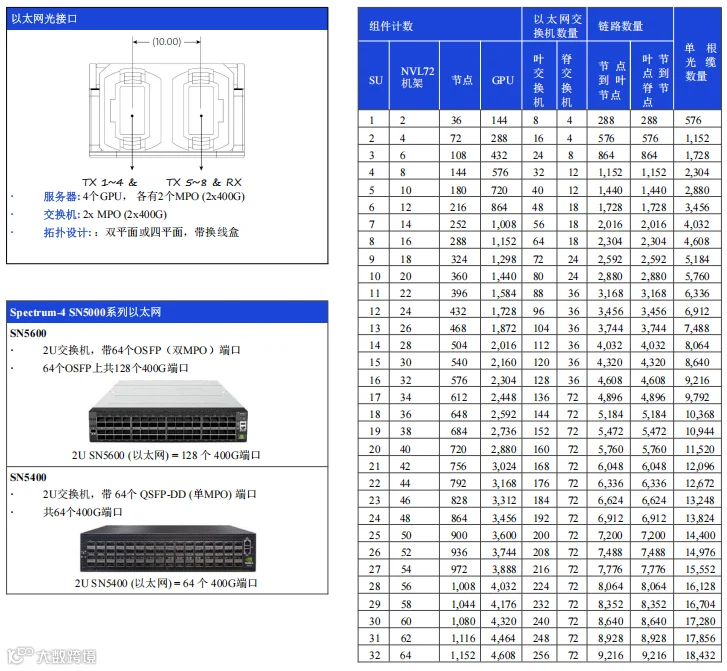
图33. GB300以太网集群尺寸和组件计数详情 - 两层双平面设计
· 双平面或四平面网络架构设计
· 双平面拓扑:
- 每个GPU连接到两个独立的平面,以实现负载均衡和冗余。
- 基于部署的GPU数量,可以实现两层(叶-脊)或三层(叶-脊-超级脊)架构。参见图34和图35。
· 四平面拓扑(三层架构的替代方案,可实现更高的可扩展性):
- 将网络架构扁平化为两层设计(删除超级脊),展示出三层架构的替代方案。该方案引入了额外的平面来进一步增加带宽,减少拥塞。
- 四平面架构将网络划分为4个200G平面,将交换机基数加倍(从128个400G端口增加到256个200G端口),可容纳更多的可扩展单元和更高的GPU密度,GPU仍与四平面设置无关,因为它可继续在集群内支持800G通信接口。
- 需要配备换线盒来管理四平面设计中的布线复杂性,从而能够采用两层(叶-脊)架构部署大量GPU(见图36)。换线盒可以放置在服务器和叶交换机之间,也可以放置在叶交换机和脊交换机之间。
4,608 GPU集群 — 2x 400G, 连通轨道, 断开平面
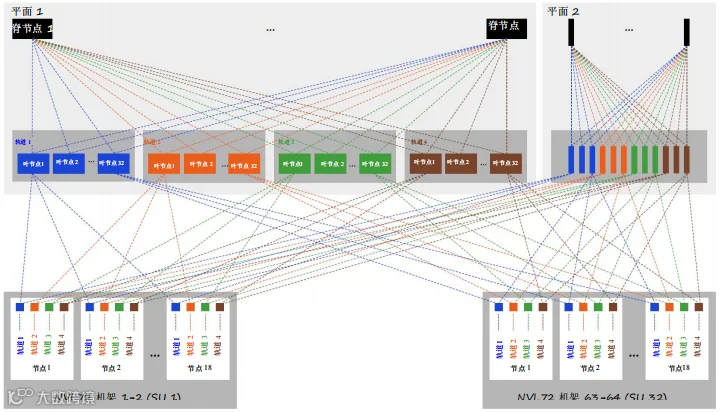
图34. 4608 GPU计算网络示例 — 两层架构GB300以太网双平面拓扑
36864 GPU集群 — 2x 400G, 连通轨道, 断开平面
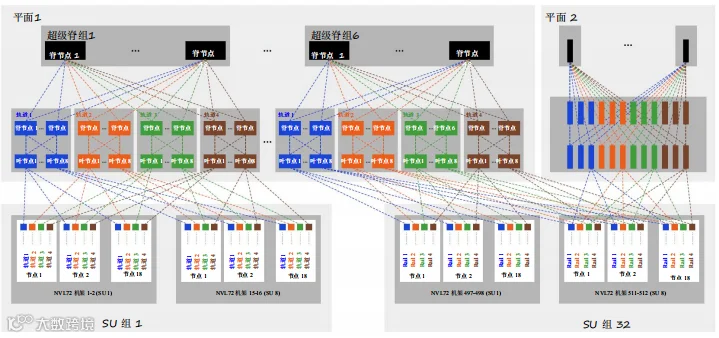
图35. 36864 GPU计算网络示例 — 三层架构GB300以太网双平面拓扑
18432 GPU 集群 — 4x 400G, 连通轨道, 断开平面
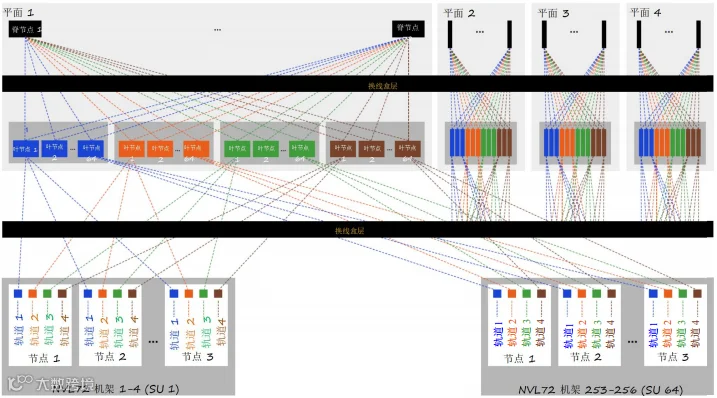
图36. 18432 GPU计算网络示例 — 带换线盒,两层架构GB300以太网四平面拓扑
· 轨道优化的连接
· 4轨道架构作为GB300以太网的固定架构保留不变。
· 然而,在GB200中,每个节点配备4个GPU,每个GPU在物理上以1个MPO-8/12表示,GB300与之不同,虽然每个服务器 (节点)同样是配备4个GPU,但每个GPU在物理上是以2个400G OSFP MPO-8/12表示的(见图33)。
· 这相当于从单个NVL72机架中输出144个MPO-8/12计算/后端连接。
· 网络组件
· 叶交换机:
- Spectrum-X SN5600交换机可支持64个OSFP双MPO-8/12 APC端口(128x 400G链路)。
- 负责将GPU连接到脊层。
· 脊交换机:
- 聚合来自多个叶交换机的流量。
- SN5600交换机用于双平面或四平面架构设计中的脊层。
· 超级脊层 (三层架构的大规模部署适用):
- 超级脊层特定用于大规模部署中采用的三层计算网络设计。它充当架构中的第三层,将多个脊-叶组连接在一起,以实现跨数千个GPU或机架的可扩展性。
· 布线要求:
· GPU、叶交换机、脊交换机和超级脊交换机(如适用)之间的连接采用400G MPO-8/12 APC光缆。
· 多模收发器(SR4)适用于短距离传输(最长50米)。
· 单模收发器(DR4)适用于长距离传输(长达500米)。
· 布线方案集包括用于点对点布线的康宁CORE主干光缆、传统单根MPO跳线以及使用EDGE8®系统的结构化布线方案。这些布线组件可以应用于任何GB300拓扑,力求跨部署的灵活性和兼容性。

2.7.2.NVL72 GB300 InfiniBand
GB300 InfiniBand计算网络旨在为NVIDIA NVL72系统中的GPU提供高性能连接,采用Quantum-3 InfiniBand交换机实现可扩展性、低延迟无阻塞通信。以下是部署此架构时需要考虑的各个事项:
· 模块化可扩展单元(SU)
· 与GB200 InfiniBand一样,每个可扩展单元(SU)由16个GB300 NVL72机架组成,每个机架含72个GPU(见图37)。
· 双平面拓扑
· 每个GPU连接到两个独立的平面,以实现负载均衡和冗余。
· 基于部署的GPU数量,可以实现两层(叶-脊)或三层(叶-脊-超级脊)架构。
· 轨道优化的连接
· 4轨道架构作为GB300 InfinBand的固定架构保留不变。
· 每个节点(服务器)配备4个GPU,每个GPU在物理上以1个800G XDR OSFP MPO-8/12表示。
· 这相当于从单个NVL72机架中输出72个MPO-8/12计算/后端连接。
· 网络组件
· 叶交换机:
- Quantum-X Q3200-RA交换机是一款2U交换机,在单个机箱内有两个独立的配备18个OSFP(双MPO)端口的交换机,这两个交换机之间没有通信。
- 每个2U机箱通过2´18个OSFP端口共支持2x 36个MPO端口(800G XDR)。
- 负责将GPU连接到脊层。
· 脊交换机:
- 聚合来自多个叶交换机的流量。
- Quantum-X Q3400-RA交换机是一款4U交换机,在单个机箱内配备了72个OSFP(双MPO)端口。
- 通过72个OSFP端口共支持144个MPO端口(800G XDR)。
· 核心交换机:
- Q3400-RA交换机在大规模部署中用作核心交换机,确保可扩展性和高带宽连接。
· 布线要求
· GPU、叶交换机、脊交换机和核心交换机之间的连接采用800G MPO-8/12 APC光缆。
· 单模收发器(DR4)适用于长距离传输(长达500米)。
· 布线方案集包括用于点对点布线的康宁CORE主干光缆、传统单根MPO跳线以及使用EDGE8®系统的结构化布线方案。这些布线组件可以应用于任何GB300拓扑,力求跨部署的灵活性和兼容性。
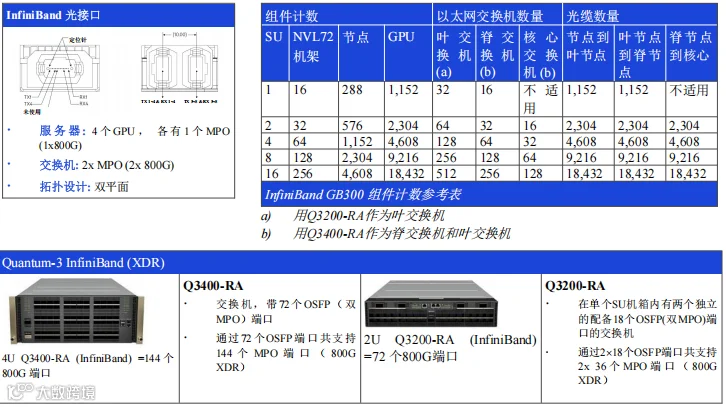
图 37. GB300 InfiniBand集群尺寸和组件计数 - 双平面设计

2.8.结论
总之,了解每个级别(A、B和C)的详细布线要求对于NVL72 GB200 或 GB300 GPU集群的有效部署至关重要。此外,在可能的情况下实施CORE主干光缆布线或结构化布线可以简化线缆管理、提高效率,特别是在大规模部署中。
在设计阶段与康宁工程团队合作,确保布线策略与特定的数据中心需求及客户要求保持一致。

附件1 – 高密度配线架
EDGE8®高密度配线架安装在19英寸机架或机柜中,与EDGE8模块、面板、线束、中继器和跳线结合使用时,可提供业界领先的超高密度连接。
由于每个客户和项目都有特定的需求,请在BOM中添加最适合您需求的配线架:
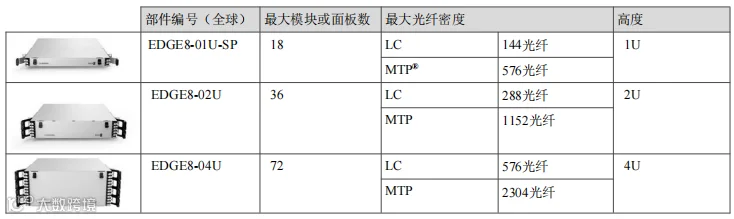
表11-高密度配线架

附件2 – 极性图纸
极性图,通常被称为光纤极性图,在使用光纤布线设计和实施数据中心链路时是必不可少的。它们在确保不同网络组件之间的适当连接、信号完整性和兼容性方面发挥着至关重要的作用。
本节将介绍适用于前面描述的每种场景的特定极性图。

场景 1 – 1600G、800G 和 400G –
服务器到交换机应用
采用点对点布线连接MPO-8/12 APC到MPO-8/12 APC
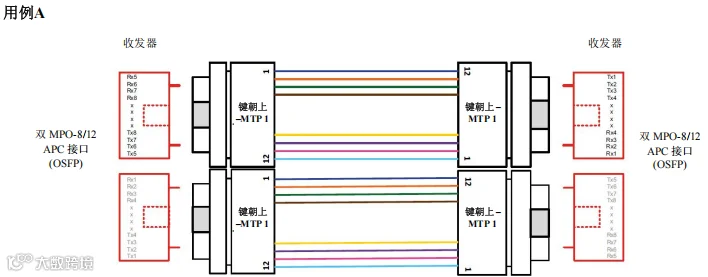
图 38. 场景1 – 1600G、800G 和 400G – 交换机到本地服务器– 用例 A
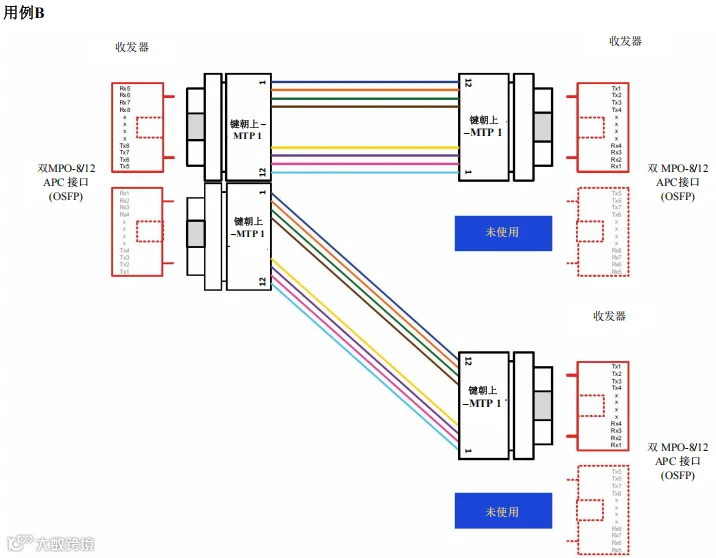
图39. 场景1 – 1600G、800G 和 400G – 交换机到本地服务器 – 用例 B
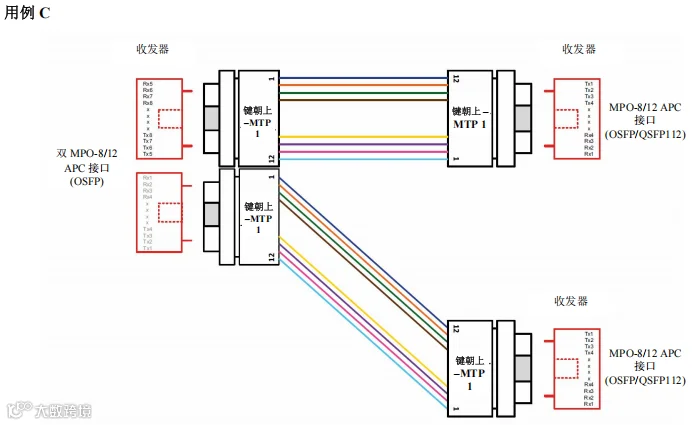
图40. 场景1 – 1600G、800G 和 400G – 交换机到本地服务器– 用例 C

场景2 – 1600G、800G和400G –
交换机到交换机应用
使用结构化布线,通过主干光缆在数据中心内连接MPO-8/12 APC到MPO-8/12 APC
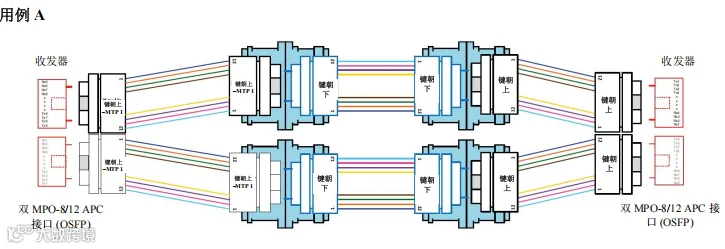
图41. 场景2 – 1600G、800G 和 400G – 交换机到交换机通过主干光缆跨数据中心连接 – 用例 A
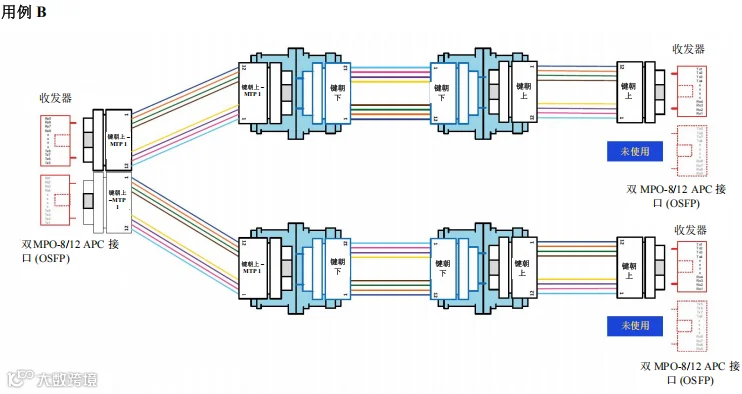
图 42. 场景2 – 1600G、800G 和 400G – 交换机到交换机通过主干光缆跨数据中心连接 – 用例 B
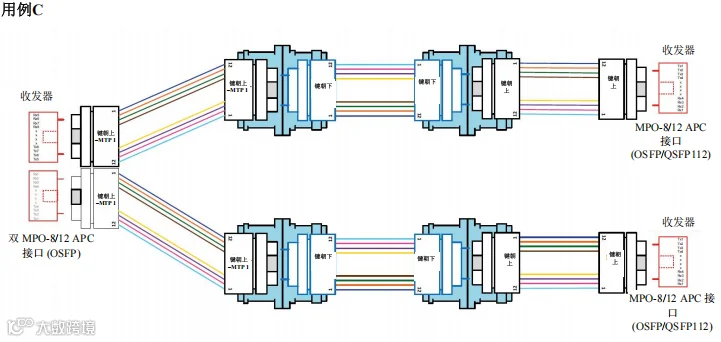
图 43. 场景2 – 1600G、800G 和 400G – 交换机到交换机通过主干光缆跨数据中心连接 – 用例 C

场景3 – 1600G、800G、400G和200G -
服务器到交换机应用交换机到交换机应用
使用点对点布线连接MPO-8/12 APC到MPO-8/12 APC
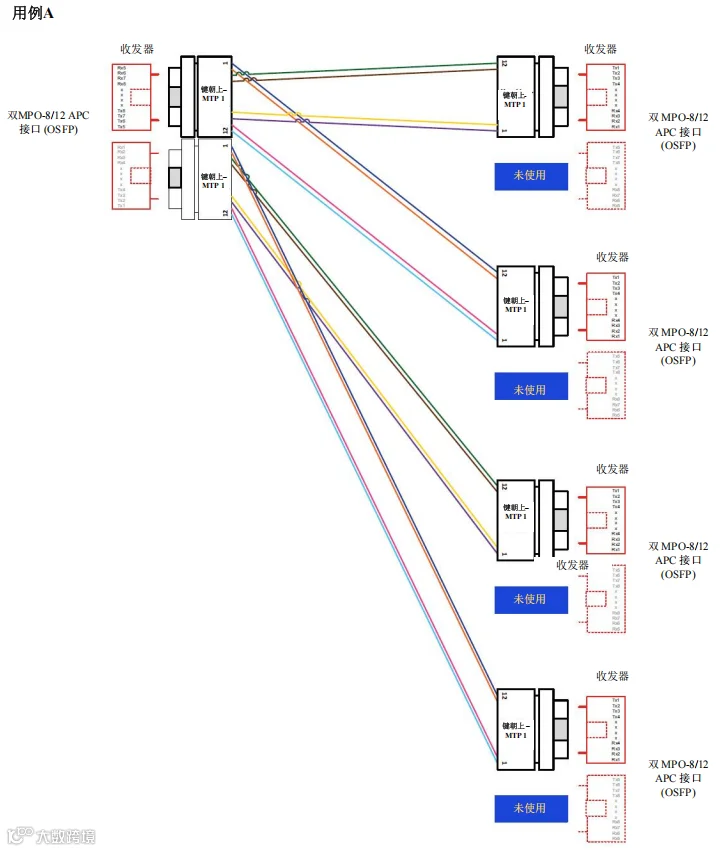
图 44. 场景3 – 1600G、800G、400G 和 200G – 交换机到本地服务器 – 用例A
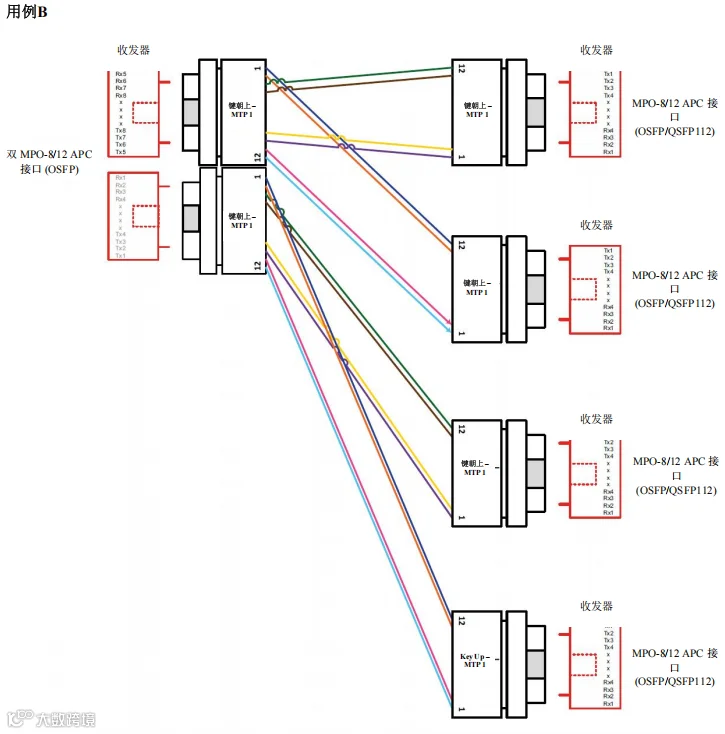
图 45. 场景3 – 1600G、800G、400G 和 200G – 交换机到本地服务器 – 用例B

场景4 – 1600G、800G、400G和200G –
交换机到交换机应用
使用结构化布线,通过主干光缆在数据中心内连接MPO-8/12 APC到MPO-8/12 APC

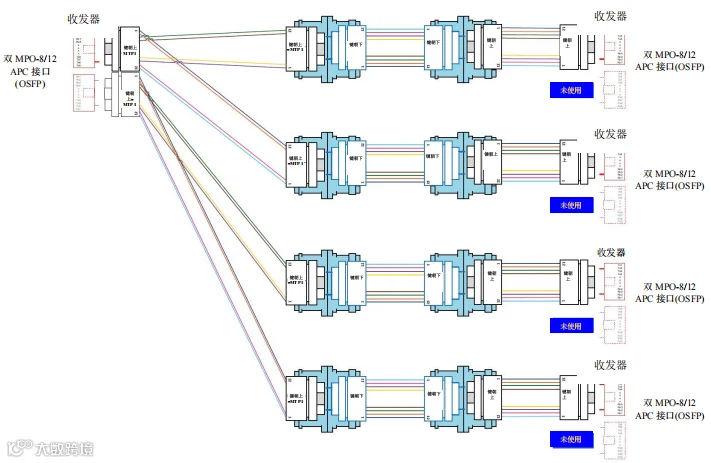
图46. 场景 4 – 1600G、 800G、 400G 和 200G – 交换机到交换机通过主干光缆跨数据中心连接 - 用例A
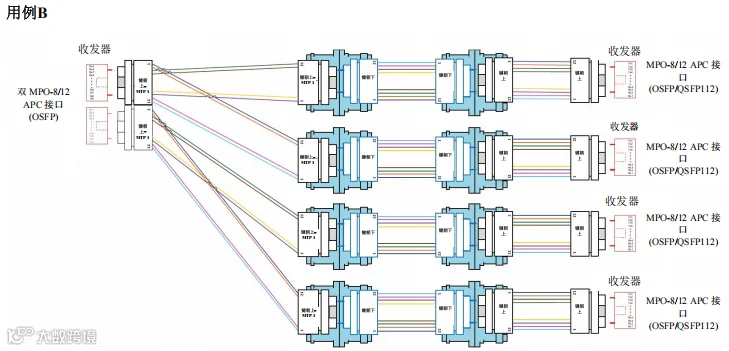
图 47. 场景 4 – 1600G、 800G、400G 和 200G – 交换机到交换机通过主干光缆跨数据中心连接 - 用例B

场景5 – 800G 和 400G -
交换机到交换机应用
使用点对点布线连接LC双工到LC双工
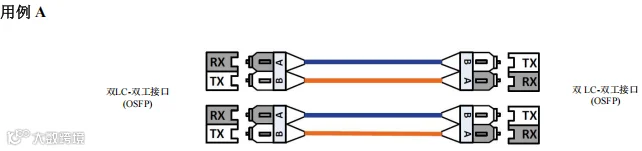
图48. 场景 5 – 800G 和 400G – 交换机到本地交换机 – 用例A

图49. 场景 5 – 800G 和 400G – 交换机到本地交换机– 用例B

场景 6 – 800G 和 400G -
交换机到交换机应用
使用结构化布线,通过主干光缆在数据中心内连接LC双工UPC到LC双工UPC
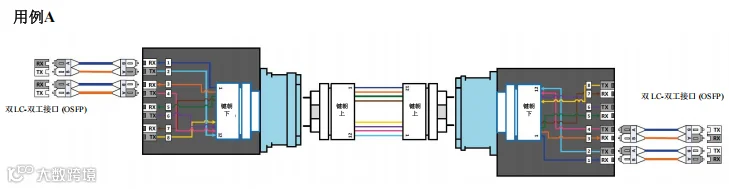
图 50. 场景 6 – 800G 和 400G – 交换机到交换机通过主干光缆跨数据中心连接 – 用例A
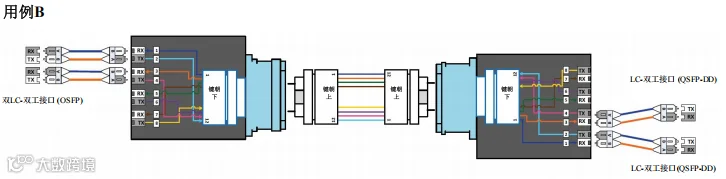
图 51. 场景 6 – 800G 和 400G – 交换机到交换机通过主干光缆跨数据中心连接 – 用例B

附件3 – 参考和联系信息
本节包含NVIDIA概述白皮书的部分参考列表。有关NVIDIA产品的更多详细信息,请访问www.docs.nvidia.com
收发器:
· 200G光通道(XDR)
- MMS4A00 1600 Gbps 双端口 OSFP 2x800Gb/s 单模 2 x DR4,500m
www.docs.nvidia.com/networking/display/9iahx00xmosfptcvr1600
- MS4A20-XM800 800Gbps 单端口 OSFP 1x800Gb/s 单模 DR4, 500m
www.docs.nvidia.com/networking/display/9iat0mosfp800sprhs
· 100G光通道(NDR)
- MMS4X00-NM 800Gbps 双端口 OSFP 2x400Gb/s 单模 2 x DR4, 500 m
www.docs.nvidia.com/networking/display/mms4x00nm800g500m/application+overview
- MMS4X00-NS 800Gbps 双端口 OSFP 2x400Gb/s 单模 2xDR4, 100 m
www.docs.nvidia.com/networking/display/800gmms4x00ns/overview
- MMA4Z00-NS 800Gb/s 双端口 OSFP, 2x400Gb/s 多模 2xSR4, 50 m
www.docs.nvidia.com/networking/display/800gmma4z00ns/overview
- MMS4X50-NM 800Gb/s 双端口 OSFP, 2x400Gb/s 单模 2xFR4, 2 km
www.docs.nvidia.com/networking/display/mms4x50nm800g2kmpub
- MMS1X00-NS400 400Gb/s 单端口 QSFP112, 1x400Gb/s 单模 DR4, 100 m
www.docs.nvidia.com/networking/display/mms1x00ns400/overview
- MMA1Z00-NS400 400Gb/s 单端口 QSFP112, 1x400Gb/s 多模 SR4, 50 m
www.docs.nvidia.com/networking/display/mms1z00ns400sr4
英伟达光缆:
· MFP7E30-Nxxx, 单模直交叉光纤线缆
www.docs.nvidia.com/networking/display/mfp7e30nxxxpub/specifications
· MFP7E40-Nxxx, 单模分路交叉光纤线缆
www.docs.nvidia.com/networking/display/mfp7e40nxxxpub/specifications
· MFP7E10-Nxxx, 多模直交叉光纤线缆
www.docs.nvidia.com/networking/display/mfp7e10nxxx/specifications
· MFP7E20-Nxxx, 多模分路交叉光纤线缆
www.docs.nvidia.com/networking/display/mfp7e20nxxx/specifications
NVIDIA 英伟达架构和参考页面:
· NVL72 GB200
www.nvidia.com/en-us/data-center/gb200-nvl72/
· NVL72 GB300
www.nvidia.com/en-us/data-center/gb300-nvl72/
· DGX H100
www.docs.nvidia.com/dgx-superpod/reference-architecture-scalable-infrastructure-h100/latest/dgx-superpod-architecture
· DGX B200
www.docs.nvidia.com/dgx-superpod/reference-architecture-scalable-infrastructure-b200/latest/dgx-superpod-architecture
· DGX B300
www.docs.nvidia.com/dgx-superpod/reference-architecture/scalable-infrastructure-b300/latest/abstract
· DGX GB200
www.docs.nvidia.com/dgx-superpod/reference-architecture-scalable-infrastructure-gb200/latest/dgx-superpod-components

往期回顾
