

NVIDIA NVL72 GB200/GB300系统:
InfiniBand和以太网连接解决方案(三)
目录
2.4. 在NVIDIA NVL72集群中
实现布线场景
为了便于识别构建AI/ML集群时使用的不同布线组件,康宁在本指南中使用三个级别的连接。这些级别和交换机数量均基于16可扩展单元集群的示例:
·A级-服务器到叶节点的布线;
·B级-叶节点到脊节点的布线;
·C级-脊节点到核心层的布线。

2.4.1. A级-服务器到叶节点的布线
一个可扩展单元可以通过节点(服务器)和叶交换机之间的点对点连接来布线(见图1),其中至少有两种布线产品选项可供选择(见图12)。在一些特定的定制设计中,也可以在可扩展单元级别实施结构化布线(见图2)。
第一种布线产品选项是使用传统的单根8芯MPO跳线来建立从各NVL72机架到各叶交换机的连接以及SU内从叶交换机到脊交换机的连接。选择不同布线供应商时,单根跳线线缆直径可能大些,这可能会影响机架内外的线缆管理和路由。从脊交换机到核心交换机也可采用点对点连接;然而,出于对布线密度和交换机间距离的考量,结构化布线解决方案可能是首选。
第二种布线产品选项是组合使用144芯和128芯CORE主干光缆建立连接。CORE主干光缆是一种用于点对点架构的多芯光纤解决方案,它将8芯MPO-8/12 APC连接整合到一个带阻燃护套的多芯光纤单元中。使用CORE主干光缆也可以实现从脊交换机到核心交换机的点对点连接;然而,出于对布线密度和交换机间距离的考量,可能首选组合使用CORE主干光缆和结构化布线。
无论哪种情况,产品的选择都取决于客户设计的具体要求。
图12展示了可扩展单元中所需的组件或部件的数量,具体取决于是选用单根跳线还是CORE主干光缆进行布线。
无论选择哪种方法,我们都将在SU内建立1152个到叶交换机的MPO-8/12 APC连接和1152个到脊交换机的连接,并再建立1152个到核心交换机的连接,将SU连接到核心交换机。
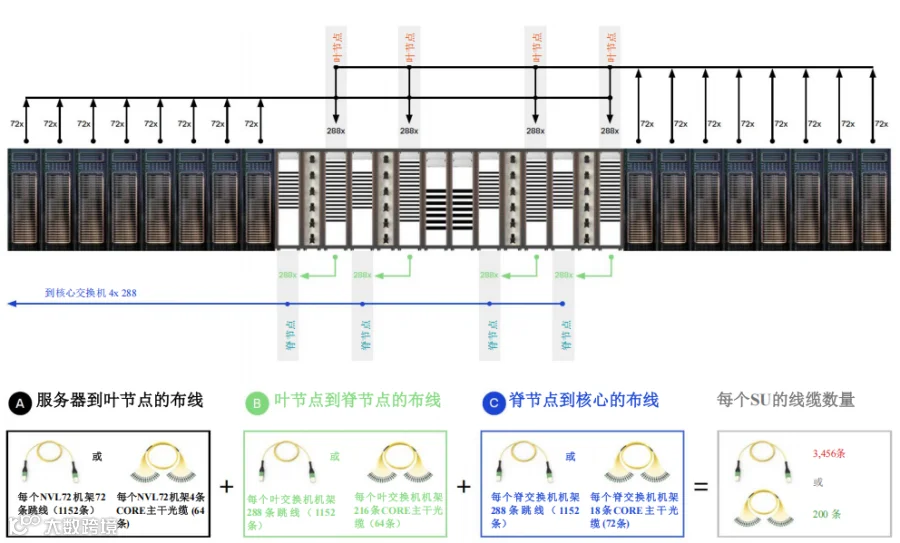
图12.两种产品方案中可扩展单元适用的连接数量
上文我们提及计算网络经过了轨道优化,总共有4个轨道。这些轨道对应的是引自每台服务器的MPO-8/12 APC连接。在以下示例中,我们将用颜色标记各轨道连接,如图13所示。
对于A级布线,我们将使用CORE主干光缆来展示从NVL72机架到可扩展单元内InfiniBand叶交换机机架的连接,因为使用它们可以简化高密度GPU集群中的布线。如果选择使用单根跳线,则可以按照轨道映射进行布线。
在图13的左侧,我们可以看到一个包含18台服务器的NVL72机架,NVL72机架内的每个托盘对应其各自的轨道。在右侧,是轨道1的叶交换机机架,内含16台叶交换机,与可扩展单元内各个NVL72机架一一对应。众所周知,Quantum-2交换机支持32个双MPO-8/12 APC端口,这意味着每台交换机可以支持多达64个独立连接。
每个含16个NVL72机架的可扩展单元(SU)共需要1152条到叶交换机的MPO-8/12 APC 8芯连接(每台服务器4条 – 每个机架72条)

图13. A级 -使用CORE主干光缆,采用点对点连接进行服务器到叶节点的布线 - 基于16可扩展单元(SU)集群的示例
各NVL72机架的每个轨道用一条CORE主干光缆布线,将每台服务器以同一颜色标记的所有轨道连接到其各自对应的叶交换机。例如,NVL72机架1的轨道1(蓝色轨道)需连接到叶节点-01交换机端口1-18;NVL72机架2的轨道1(蓝色轨道)需连接到叶节点-02交换机端口1-18;依此类推。在内含16个NVL72机架的可扩展单元中,轨道1完成每台叶交换机前18个端口的连接(共64个),如图14和图15所示。此外,每台叶交换机还有18个上行链路连接到脊交换机。对所有NVL72机架的每个轨道重复此过程,确保完全映射并完成可扩展单元内所有连接。
将NVL72机架连接到叶交换机机架时,无论是采用结构化布线还是有改进映射和线缆管理的需求,都可选择将配线面板添加到可扩展单元中。可安装配线面板的位置如图14所示。

图14. A级 – CORE主干光缆路由示例
同样的布线和映射概念也适用于轨道2、轨道3和轨道4。在图15中,我们可以看到该布局下有4个叶交换机机架,每个轨道各一个,每个机架包含其各自的18个叶交换机。基于SU配置,如果在SU布局内采用结构化布线,则可以添加配线面板。
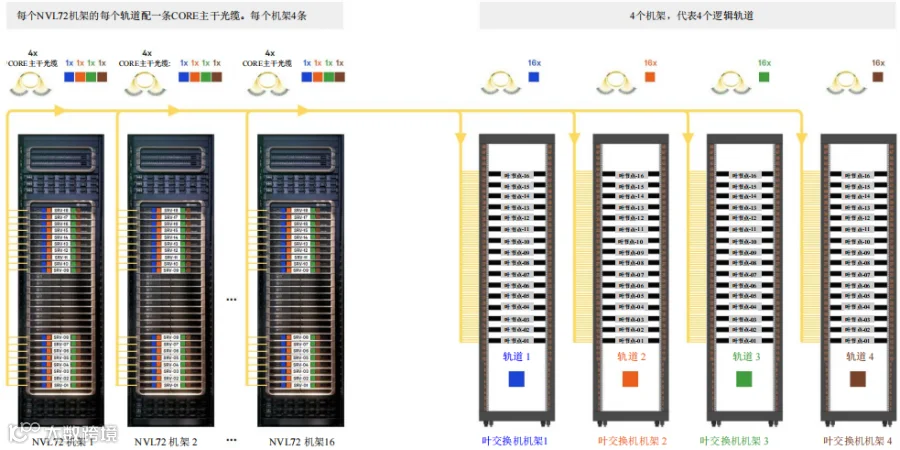
图 15. A级 – CORE主干光缆到叶交换机的路由

2.4.2. B级 - 叶节点到脊节点的布线
由于叶交换机和脊交换机物理上位于同一个可扩展单元内,因此,可使用上文提及的产品选项(单根跳线或CORE主干光缆)将叶交换机连接到脊交换机,也可以采用点对点布线或结构化布线进行连接。
在图16中,左侧,我们可以看到叶交换机机架,内含轨道1的全部叶交换机,共计16个;右侧,我们可以看到脊交换机机架,内含轨道1的9个脊交换机(Quantum-2,32个双MPO-8/12 APC端口),可扩展单元内的每个NVL72机架各一个。
从叶交换机机架到脊交换机机架,共需288个连接。一个SU共需1152个叶节点到脊节点的MPO-8/12 APC 8芯连接。
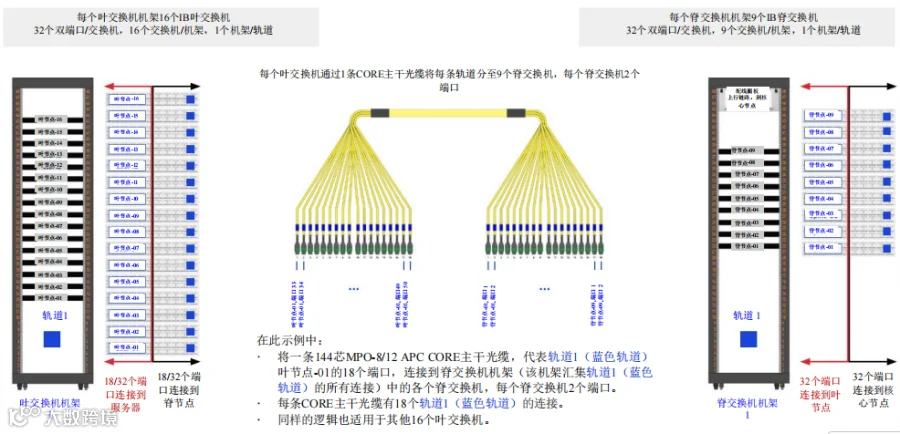
图16. B级 – 使用CORE主干光缆,采用点对点连接进行叶节点到脊节点的布线 – 基于16可扩展单元(SU)集群的示例。
使用CORE主干光缆时,单根144芯主干光缆可将轨道1(蓝色轨道)叶节点-01的18个端口路由到脊交换机机架内的各个脊交换机,每个脊交换机2个端口,如图17所示。
每条CORE主干光缆的设计都适于处理轨道1(蓝色轨道)的18个连接,简化布线的同时降低复杂性。同样的原理也适用于轨道1(蓝色轨道)内其他16个叶交换机,每个叶交换机都采用相同的CORE主干光缆配置来建立与脊交换机机架的连接。
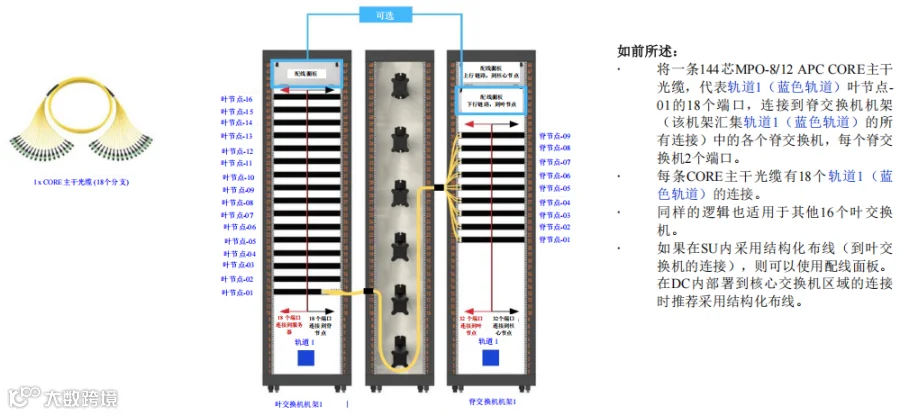
图17. B级 – CORE主干光缆路由示例
为改进线缆管理,在可扩展单元(SU)内进行结构化布线时可以使用配线面板。配线面板可为叶交换机的连接提供有组织、可扩展的解决方案。在将连接路由到数据中心(DC)内的集中式核心交换机区域时,强烈推荐使用结构化布线,因为这种布线方式可简化线缆路由,增强系统组织架构,便于排除故障。
同样的布线和映射概念也适用于轨道2、轨道3和轨道4。在图18中,我们可以看到该布局下有4个叶交换机机架,每个轨道各一个。另外还有四个脊交换机机架,也是每个轨道各一个。
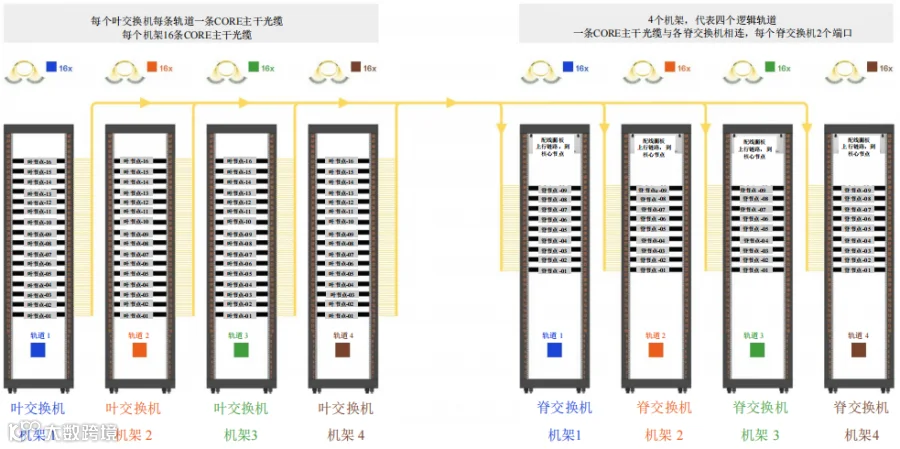
图 18. B级 – CORE主干光缆到脊交换机的路由

2.4.3. C级 – 脊节点到核心的布线
脊节点到核心交换机的布线可以通过结构化布线实现。在一些特定的定制设计中,也可以在脊节点到核心连接级别实施结构化布线,这取决于核心交换机相对于脊节点的物理位置。
在图19中,脊节点到核心的布线是通过结构化布线实现的:CORE主干光缆连接有源设备,EDGE8®主干光缆用作主干布线。在一个16可扩展单元集群中,有9个核心组,分布于18个核心机架上,每个核心机架容纳16个核心交换机,因此每个核心组有32个核心交换机。
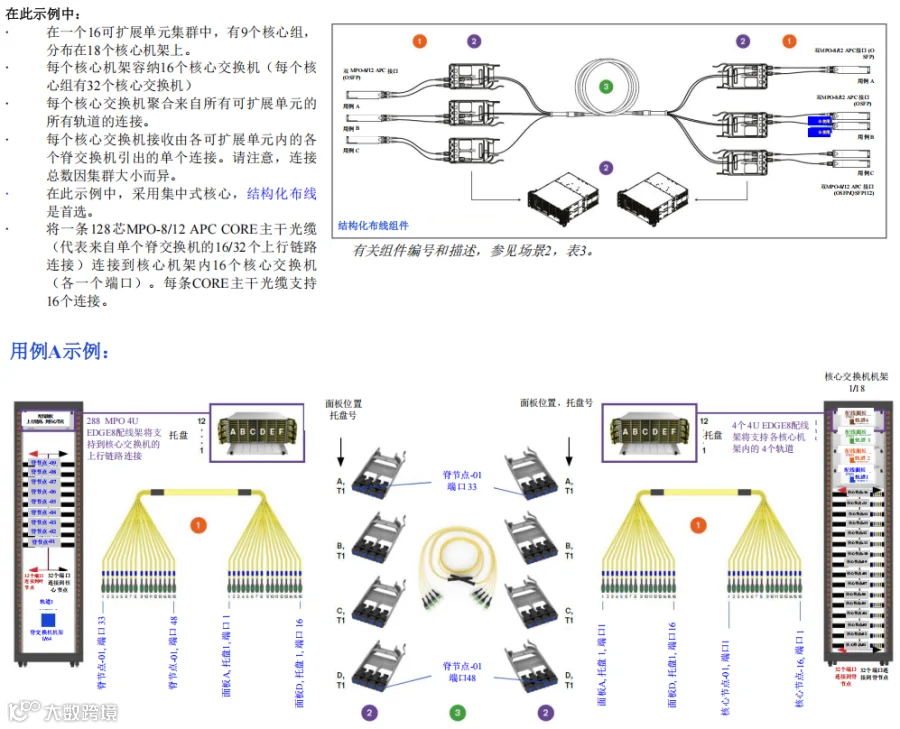
图19. C级 – 采用结构化布线连接脊节点到核心节点,用CORE主干光缆连接有源设备,EDGE8®主干光缆用作主干布线-基于16可扩展单元集群的示例
图20展示了聚合过程,其中每个核心交换机聚合来自所有可扩展单元的所有轨道的连接,并接收由各可扩展单元内的各个脊交换机引出的单个连接。连接总数因集群大小而异。
在此配置中,采用集中式核心,结构化布线是首选。单条128芯MPO-8/12 APC CORE主干光缆可从脊交换机引出16或32个上行链路连接,连接到核心机架内的16个核心交换机(各一个端口)。每个CORE主干光缆最多可支持16个连接。
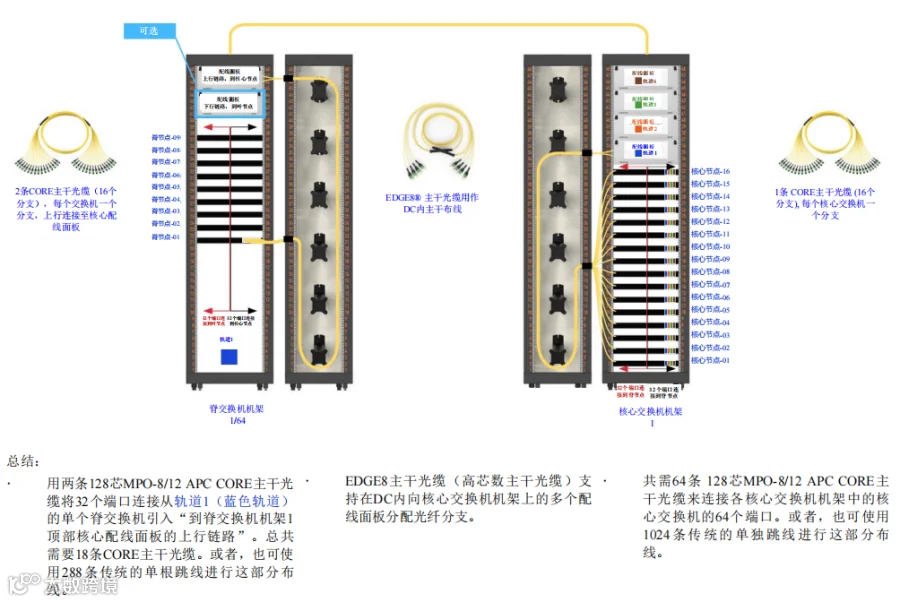
图20. C级 – CORE主干光缆和EDGE8主干光缆路由示例
图21是各POD中CORE主干光缆和EDGE8主干光缆的总体布局,展示了它们在结构化布线框架内到集中式脊交换机机架的路由。
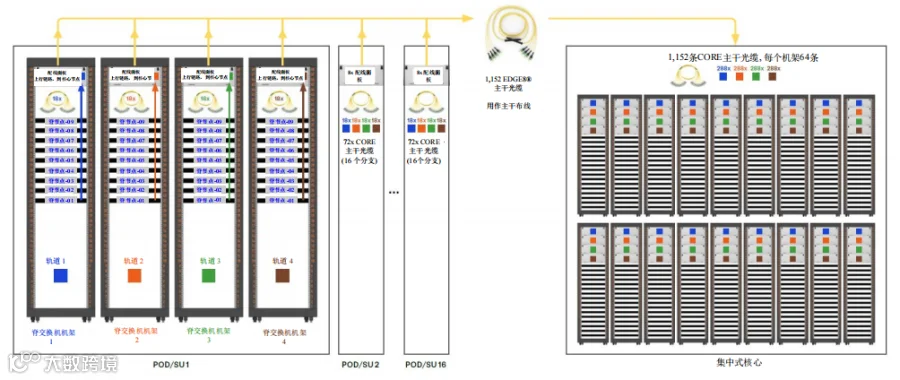
图21. C级 – 结构化布线布局中CORE主干光缆和EDGE8主干光缆被路由到脊交换机

2.5.多模vs单模
在网络中使用多模光纤还是单模光纤的选择将取决于具体的设计要求。多模光纤的传输距离最多为50米,因此,其主要适用于可扩展单元内的连接,如服务器到叶节点和叶节点到脊节点的连接。然而,由于脊交换机和核心交换机在物理位置上通常并不近,因此建议在这部分设计中推荐使用单模光纤,因为单模光纤能够有效地支持更长的传输距离,最远可达500米。

2.6.整体概览
现在我们已经了解了不同的集群尺寸,以及如何在计算网络的有源设备之间进行布线,让我们通过图示总结一下可以使用的组件。这些组件将取决于具体的设计,但主要基于我们在本文中回顾的不同产品和部件编号。以下示例基于Quantum-2 InfiniBand交换机,但在使用Quantum-3 InfiniBand或Spectrum-4以太网交换机的布线中也可将其作为设计参考。

2.6.1.连接1可扩展单元集群的布线

如前所述,可扩展单元(SU)是GPU集群的基础构建块。对于1可扩展单元集群,可以考虑两种不同的方法,如图22所示。通过应用我们已探讨的不同布线层级,可以总结出以下配置:
1. 非可扩展集群:此配置(见图23)包括64个叶交换机和18个脊交换机,但它缺乏可扩展性,仍局限于两层设计:
· 节点到叶节点(A级)的1152个MPO连接:这些连接可以使用点对点布线来实现,布线布局含64条CORE主干光缆(每条144芯)或1152条单根8芯跳线。
· 叶节点到脊节点(B级)的1152个MPO连接:这些连接也可以使用点对点布线来实现,布线布局含64条CORE主干光缆(每条144芯)或1152条单根8芯跳线。
2. 可扩展集群:此配置(见图24)中,1个SU由64个叶交换机和36个脊交换机组成,可通过合并核心交换机层将SU数量扩展到2个或以上,过渡到三层设计:
· 节点到叶节点(A级)的1152个MPO连接:这些连接可以使用点对点布线来实现,布线布局含64条CORE主干光缆(每条144芯)或1152条单根8芯跳线。
· 叶节点到脊节点(B级)的1152个MPO连接:这些连接也可以使用点对点布线来实现,布线布局含64条CORE主干光缆(每条144芯)或1152条单根8芯跳线。
· 核心连接(C级):引入核心交换机层时,需要额外部署1152个MPO连接。有关如何实现到集中式核心交换机区域的连接,详见图25至图32。
每个可扩展单元从GPU到脊节点的布线,可使用128条(144芯)CORE主干光缆(从服务器到叶节点的64条+从叶节点到脊节点的64条)来实现,而不用2304条(8芯)单根跳线(从服务器到叶节点需1152条+从叶节点到脊节点需1152条),从而管理可扩展单元内的复杂性。
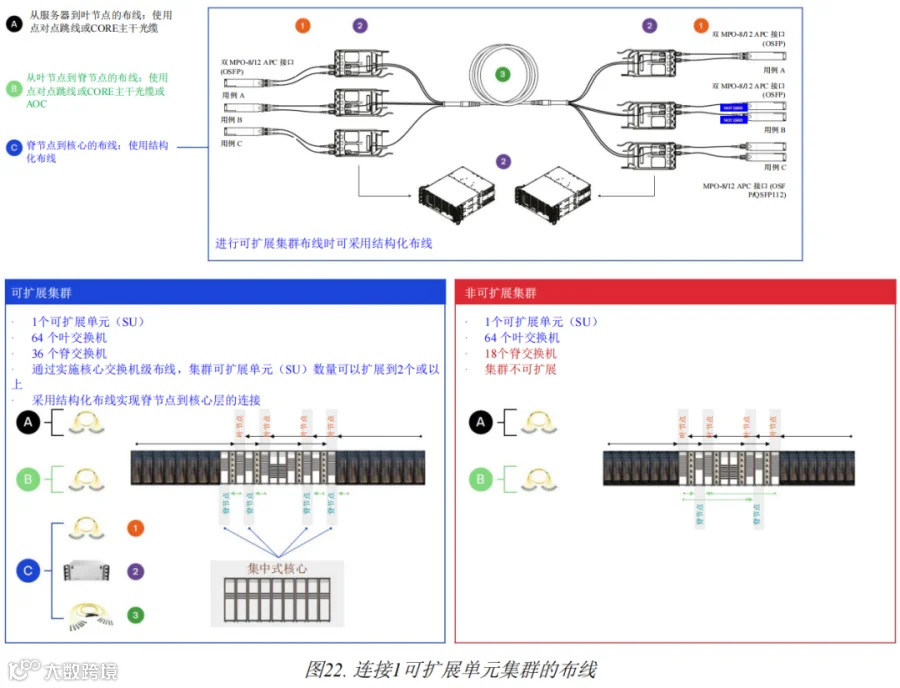
图22. 连接1可扩展单元集群的布线
在非可扩展集群中,每个叶交换机接收18个引自服务器的MPO连接,每个脊交换机接收引自各叶节点的单个MPO连接。因此,每个脊节点总共有64个MPO连接(如图23所示)。
1152 GPU集群,采用两层设计,有18个脊交换机
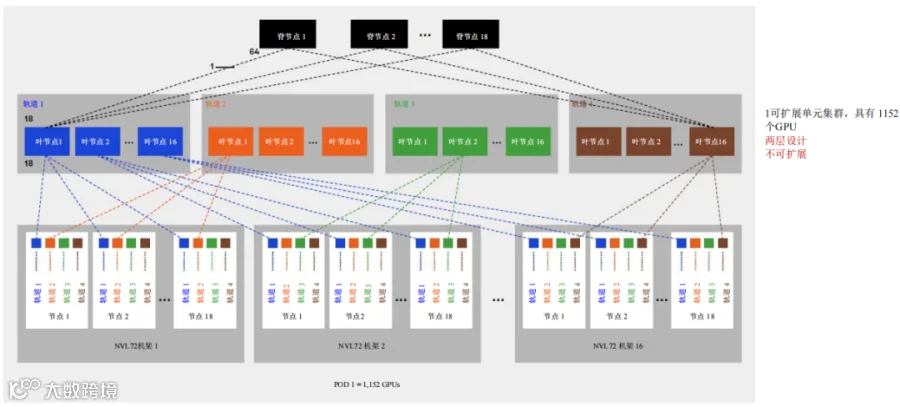
图 23. 1可扩展单元集群(两层设计,不可扩展)计算网络
在可扩展集群中,每个叶交换机接收18个引自服务器的MPO连接,每个脊交换机接收从同一轨道内各叶节点引出的MPO连接(每个叶节点两个MPO连接),因此,每个脊节点共计32个MPO连接。之后,各脊节点根据集群的大小向核心交换机转发一定数量的连接,如图24所示。
1152GPU集群,采用两层设计,有36个脊交换机
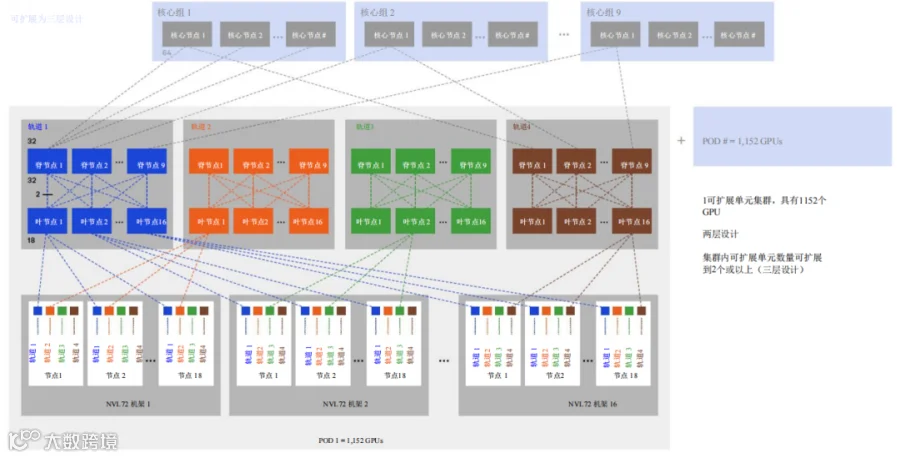
图24. 1可扩展单元集群(可扩展)计算网络

未完待续![]()
往期回顾
