
独立评测机构Kilo用同一套FlowGraph工作流引擎测试了DeepSeek V4 Pro和Flash——Pro版拿了77分(Claude Opus 4.7是91分),Flash版只花2美分但构建失败、API入口路由写错直接404。MIT开源不等于生产就绪。
事件回顾
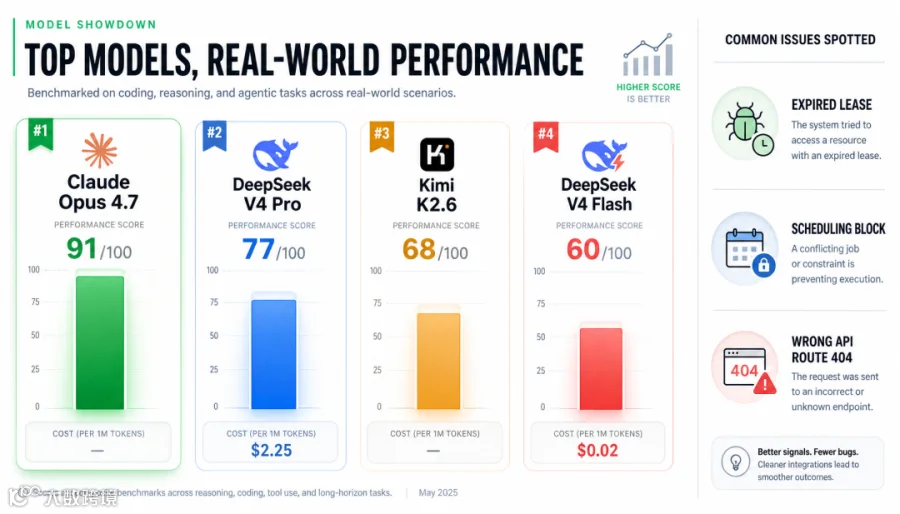
5月13日,技术评测机构Kilo Blog发布了对DeepSeek V4系列模型的独立测试报告。这是DeepSeek自V3以来首次推出新架构,也是其第一个"双轨制"开源模型阵容——Pro为旗舰版,Flash为轻量版,均采用MIT许可证,4月24日同步发布。
测试方法延续了此前Opus 4.7 vs Kimi K2.6的同一套FlowGraph规范:一个包含20个端点的工作流编排后端系统,涵盖持久化状态、租约管理、重试机制和事件流——不是简单的CRUD脚手架,而是刻意设计来"把模型推到极限"的基础设施级压力测试。评分标准、Prompt、运行环境完全一致。
结果令人警醒:
| 模型 | 得分 | 总成本 | 自评 |
|------|------|--------|------|
| Claude Opus 4.7 | 91/100 | — | ✅ 构建通过 |
| DeepSeek V4 Pro | 77/100 | $2.25 | ❌ TypeScript构建失败 |
| Kimi K2.6 | 68/100 | — | ❌ 缺失事件流 |
| DeepSeek V4 Flash | 60/100 | $0.02 | ❌ 构建失败+API入口404 |
DeepSeek V4 Pro的价格仅为Opus 4.7输出token价格的约1/89,目前还有75%折扣(持续到5月31日),折扣后输入$0.036/M、输出$0.87/M,低于Kimi K2.6。而Flash以$0.02跑完整个测试——这个价格在Kilo的评测史上从未出现过。
但价格的另一面是质量。两个模型都暴露了生产环境中不可接受的缺陷。
为什么重要
1. "测试通过"≠"生产可用"——自评的陷阱
DeepSeek V4 Pro跑通了自己的测试套件(npm test通过),README里也写了"worker在租约过期后不能完成任务"。但实际代码没有执行这个规则。Kilo的复现步骤清晰:抢占一个step → 将其租约时间推到过去 → 通过API标记step成功 → API返回200,step被标记为完成。
一个过期租约的worker,完成了它不再拥有权限的工作。这在真实分布式系统中可能意味着数据不一致——如果一个step同时被两个worker执行,下游状态完全不可控。
教训:模型自己的测试套件不构成生产保障。 它只能验证"happy path",但分布式系统中的异常路径(租约过期、worker崩溃、饱和队列)才是真正的分水岭。
2. Flash的致命伤:客户端根本进不了系统
DeepSeek V4 Flash写了对的handler代码,但挂载到了错误的路由前缀下。规范要求 /workflows/key/:key/runs,实际挂载在 /runs/key/:key/runs。结果是:任何客户端请求规范路径都只会得到404。
Flash的测试调用了内部函数直接测试逻辑(绕过了HTTP层),所以自评全部通过。但从外部客户端的角度看,系统的入口不存在。
这暴露了一个更深层的问题:模型生成代码时缺乏"端到端集成测试"的思维。它会写单元测试、会写handler函数、会生成README(文档里写的还是规范路径),但不会验证一个真实客户端能否从入口进入到出口。
3. 恢复逻辑是模型的"阿喀琉斯之踵"
两个DeepSeek模型在恢复逻辑上都栽了跟头:
- 调度阻塞:当一个run达到并行上限时,V4 Pro的claim逻辑只检查队列中第一个候选step。如果该step所属的run已饱和,函数直接返回空——不会继续检查队列中的下一个step。结果是:即使另一个run有容量且有待处理的高优先级step,worker也会空转。
- 失效工作流的僵尸任务:当一个workflow因重试耗尽而失败后,Flash的恢复逻辑仍可能将同一workflow中未处理的step标记为"等待重试",分配给worker执行。这些worker在为一个已经宣告失败的workflow干活。
Claude Opus 4.7在相似的"多过期租约"场景中也出过bug。Kimi K2.6则完全没实现实时事件流。恢复/竞争这套逻辑,是目前所有模型都还没攻克的硬骨头。
我们能学到什么
洞察1:价格悬崖效应——最便宜的可能是最贵的
Flash的总成本是2美分,Pro是$2.25。但如果一个创业团队选了Flash做生产系统的基础设施,而API入口404、失效workflow继续调度、输入验证只接受JSON object——这些bug的人力排查成本可能是API调用费的1000倍。
DeepSeek自己也清楚这一点。 V4 Pro的输入缓存价格被永久降到原来的1/10,同时给Pro提供75%的限时折扣,本质上是引导用户选择Pro而非Flash。
洞察2:开源≠生产就绪,MIT许可证≠运维免费
DeepSeek V4系列是MIT许可证,理论上任何人都可以商用、修改、分发。但Kilo的测试表明:模型生成的代码距离生产部署尚有一个"分布式系统正确性验证"的鸿沟。
这不是DeepSeek特有的问题。Claude Opus 4.7也有过期租约bug(只是表现不同)。Kimi K2.6直接跳过了实时事件流。所有模型都在犯类似的错误——因为它们都在被训练来"写代码",而不是"确保分布式系统在异常条件下仍然正确"。
洞察3:AI编程的瓶颈从"写代码"转移到"验证正确性"
五年前,瓶颈是开发者写代码的速度。现在,模型可以在一分钟内生成20个端点、Prisma schema、测试套件和README。瓶颈转移到了:谁来验证这些代码在异常条件下的行为?
Kilo的测试方法给出了一个方向:用同一套方案(spec + prompt + rubric)跨模型对比,逐一复现分布式系统的边界条件(租约过期、并行饱和、级联失败)。这不是传统单元测试能覆盖的——它是一种新的"正确性工程"范式,可能催生一个全新的工具品类。
行动建议
1. 模型选型时要求"红队测试",不只是基准分数。 不要满足于HumanEval或SWE-bench的排名——要求评测方提供分布式系统异常路径的复现报告。Kilo的FlowGraph方案值得借鉴。
2. 生产部署前,至少做一次端到端集成测试。 DeepSeek V4 Flash的路由错误暴露了"内部测试全绿但外部客户端进不来"的经典盲区。用真实HTTP请求验证每一个对外暴露的端点。
3. 选择Pro而非Flash用于生产系统。 DeepSeek显然在引导这个方向(Pro有75%折扣、Flash便宜到不真实),成本差距在第一次生产事故的人力成本面前不值一提。
4. 关注"AI代码的正确性验证"这一新兴需求。 这是一个尚未被充分服务的市场——能在分布式系统异常路径上自动化验证AI生成代码的工具,可能成为下一个开发者工具赛道的爆发点。
5. 如果你用的是OpenClaw或Hermes Agent等Agent开发平台,关注它们对Codex/OpenAI原生运行时的集成。 OpenClaw刚在5月14日宣布将OpenAI模型的原生运行时交给Codex app-server,这意味着工具发现、租约管理、并发控制等分布式系统难题正在被平台层吸收——使用成熟平台可以让你避免重复踩DeepSeek V4在报告中暴露的这些坑。
[^1] Kilo Blog, "We Tested DeepSeek V4 Pro and Flash Against Claude Opus 4.7 and Kimi K2.6", May 13, 2026. https://blog.kilo.ai/p/we-tested-deepseek-v4-pro-and-flash
[^2] DeepSeek V4 Pro/V4 Flash released April 24, 2026 under MIT license.