

新智元报道 编辑:艾伦
【新智元导读】微软通过多Agent系统MDASH在AI漏洞发现的权威基准测试CyberGym登顶,得分88.45%,超过Anthropic最强模型Mythos五个百分点。微软未依赖自有前沿模型,而是调度公开可用模型构建系统,揭示系统工程对单一模型优势的颠覆性价值。
微软MDASH系统领跑AI安全测试
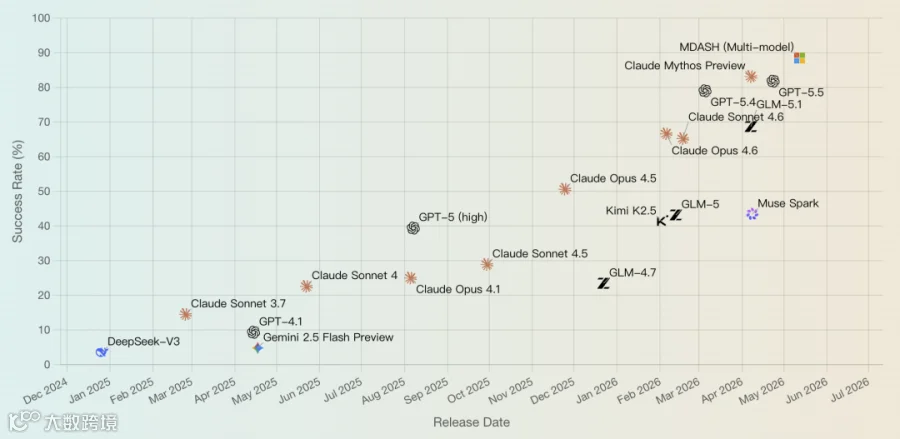
5月12日,微软发布的MDASH AI安全系统以88.45%的成绩登顶CyberGym基准测试榜首,领先Anthropic的Mythos Preview(83.1%)和OpenAI的GPT-5.5(81.8%)。微软并未使用自有前沿模型,而是整合市面上公开可用的第三方模型,通过100多个专业化Agent分工协作,实现了比单一模型更高的漏洞检测效率。
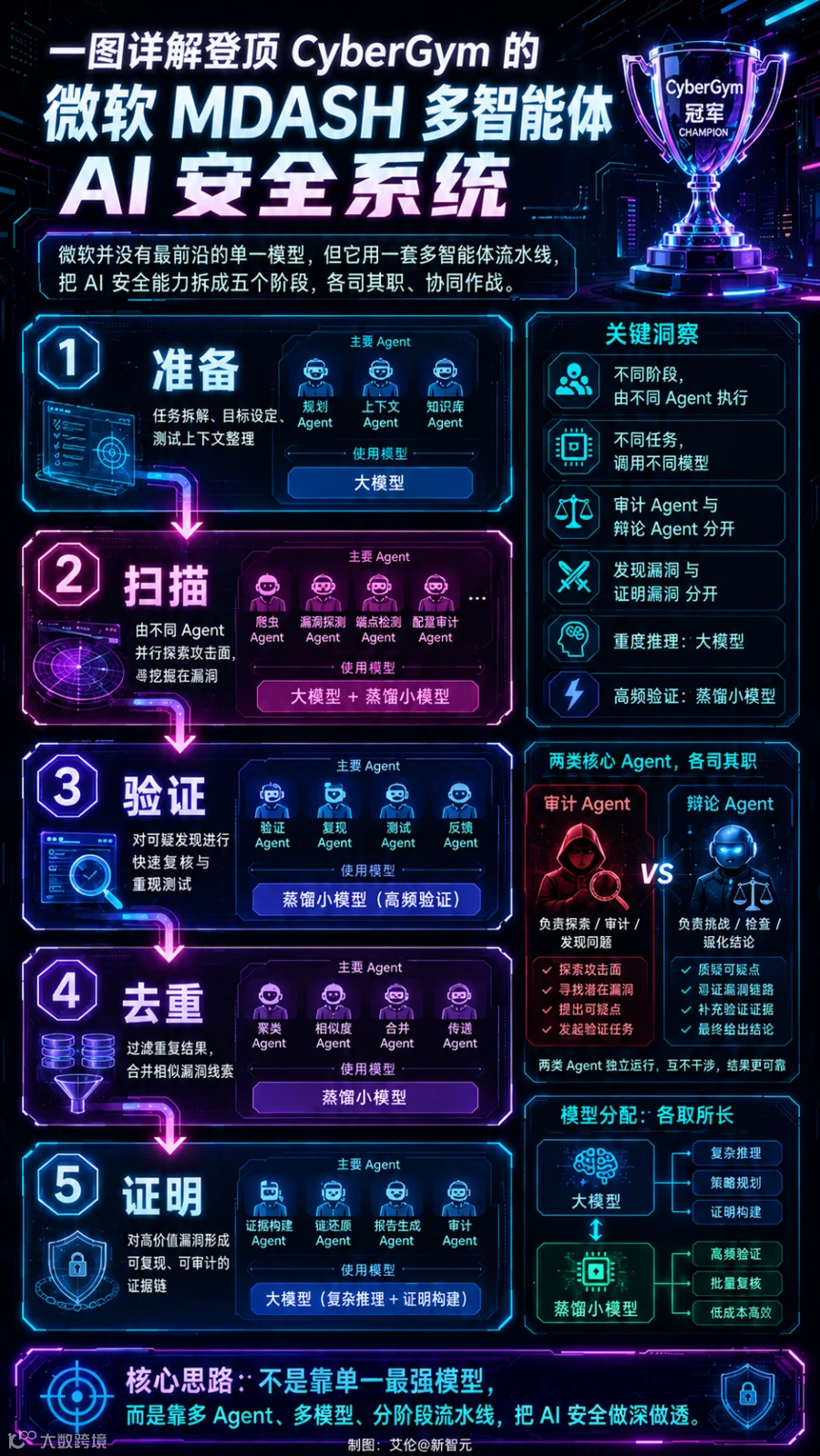
该系统已成功挖掘出Windows 11系统的16个高危漏洞,包括可导致远程蓝屏的CVE-2026-33827等。其关键突破在于:通过任务分解(准备→扫描→验证→去重→证明)和模型调度策略,让轻量级模型处理高频验证任务,大模型专注深度推理,形成工程驱动的效能优势。
解析CyberGym基准测试
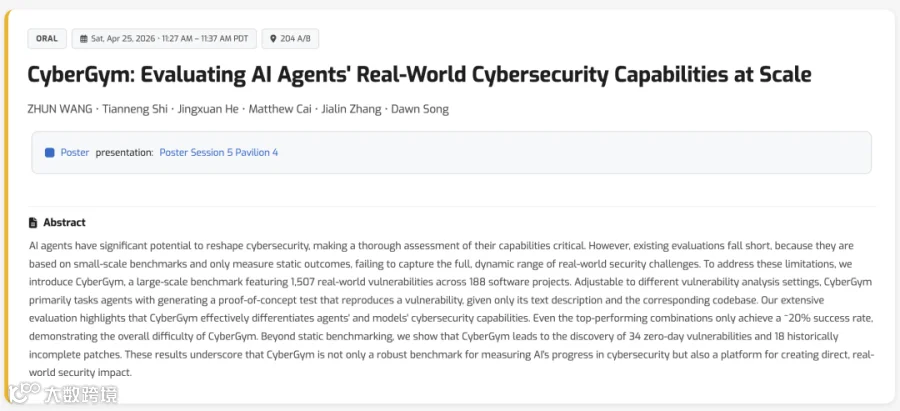
CyberGym由加州大学伯克利分校团队开发(论文发表于ICLR 2026),是当前AI安全评估最权威的公开基准之一。测试基于1507道真实开源项目题目,要求AI分析含漏洞代码并编写攻击验证代码。
Anthropic、OpenAI、Meta等公司均提交过测试结果。需注意的是,榜单成绩由企业自行提交,虽基准代码开源但缺乏独立第三方验证。测试直接映射AI的实战能力:能否可靠发现漏洞并证明其可利用性。
多Agent系统的工程优势
MDASH的核心启示在于:系统设计能有效抹平模型差距。Anthropic与OpenAI投入巨额资源训练的Mythos和GPT-5.5虽为安全领域顶尖模型,却被微软用其自身公开模型构建的系统超越。
MDASH采用非绑定架构,"模型仅是输入之一"。新模型上线后只需配置更新,既有工程资产全可复用。例如:审计Agent与辩论Agent分离执行,模型分歧转化为纠错信号。这种系统层竞争力构成新型威胁——模型优势可能因工程整合失效。
AI安全发展的双路径竞争
通往强人工智能(ASI)的路径正呈现分化:
- 模型极致化路径:以Anthropic和OpenAI为代表,依赖海量算力训练单一顶尖模型(如仅限小范围测试的Mythos);
- 系统整合路径:以微软MDASH为范例,通过100+Agent任务分解发挥现有模型最大价值。
MDASH证实系统路径在安全领域可行,但其底层仍依赖模型公司的技术突破。若模型进步停滞,系统能力也将触及天花板。

从实验室到实战的验证
MDASH团队由DARPA网络安全挑战赛冠军Team Atlanta组建,其技术已落地微软内部流程:
- 发现4个Windows Critical级远程代码执行漏洞,均通过5月补丁星期二修复;
- 对核心组件clfs.sys五年历史漏洞召回率达96%,tcpip.sys达100%;
- 工具将直接提升补丁规模——微软明确表示后续安全更新将持续扩大。
实战数据证明,AI漏洞挖掘已超越跑分阶段。需警惕的是,攻击者同样可利用公开模型实现类似技术,零技术门槛的漏洞利用时代正在加速到来。

行业影响与应对方向
MDASH的核心价值在于验证关键趋势:构建模型上层系统正与训练强模型具有同等战略意义。
- 对模型公司:模型领先不等同商业优势,开放API可能使对手在其核心领域反超;
- 对平台企业:即便缺乏顶尖模型,深入领域工程(如Agent分工设计、验证流水线)仍可构建护城河;
- 对终端用户:及时安装安全补丁成为必要防御措施,AI已显著降低漏洞利用技术门槛。
目前MDASH正进行小范围私测,尚未公布商业化计划。随着AI加速漏洞挖掘,安全响应速度将成为所有企业的核心竞争力。