
GitHub一开发者以极简单文件形式完整复现LeCun团队提出的JEPA系列模型,仅用160-278行代码实现I-JEPA、V-JEPA等五个核心变体,仅依赖PyTorch和torchvision,可在普通笔记本运行。该教学项目旨在清晰呈现JEPA的核心机制。

代码完整拆解了掩码块嵌入预测、3D管状掩码等关键技术,同时保留EMA目标编码器、smooth-L1损失函数等核心模块。五个模型实现概览:
- iJEPA(图像)
160行处理CIFAR-10,采用掩码块嵌入预测策略,通过可见区域预测被遮盖区域特征。 - V-JEPA(视频)
188行适配Moving MNIST,扩展二维patch为3D管块,实现时空特征预测。 - V-JEPA 2
278行支持动作条件预测,采用两阶段预训练与预测逻辑。 - C-JEPA(物体轨迹)
174行聚焦物体级轨迹掩码,基于双向Transformer进行轨迹预测。 - LeWorldModel
233行实现端到端训练,去除EMA与masking机制,联合优化编码器与预测器。
技术实现要点
项目通过三方面轻量化设计降低使用门槛:模型规模从ViT-Huge精简至ViT-Tiny;数据集替换为CIFAR-10等轻量级资源;精准保留掩码策略、损失函数及EMA更新等核心机制。
以160行的ijepa.py为例,完整包含patch embedding、ViT encoder、目标编码器、masking策略等组件。在CIFAR-10上训练100个epoch,线性探测准确率达52.7%。项目提供特征降维可视化,直观展示类别特征从混杂到分离的训练过程。

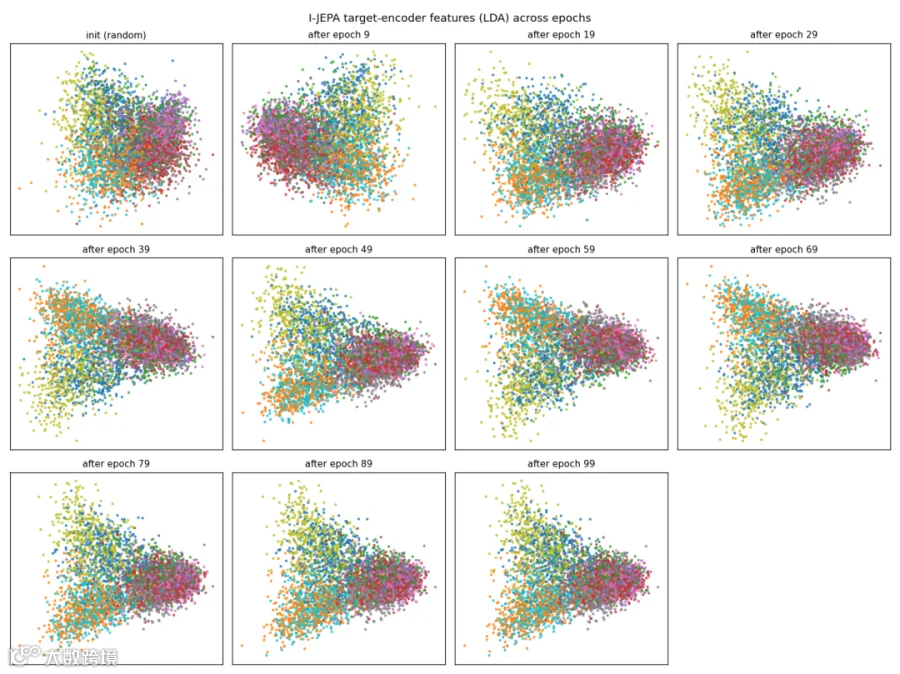
每个模型文件均附带xxx_extras.py脚本,自动生成掩码动画、损失曲线及t-SNE降维图,直观反映模型学习进展。实操步骤简单:
git clone git@github.com:keon/jepa.git && cd jepa
python -m venv .venv && source .venv/bin/activate
pip install -r requirements.txt
五大变体实现独立,仅需执行对应脚本:
python ijepa.py # 核心训练
python ijepa_extras.py # 含可视化功能
从论文到可执行算法的本质还原
相比Meta官方仓库的分布式训练架构与复杂数据管道,本项目将JEPA压缩至算法本体。每个实现文件仅保留Encoder、Predictor、mask采样等核心模块,代码与论文符号(f_theta、g_phi)直接对应。
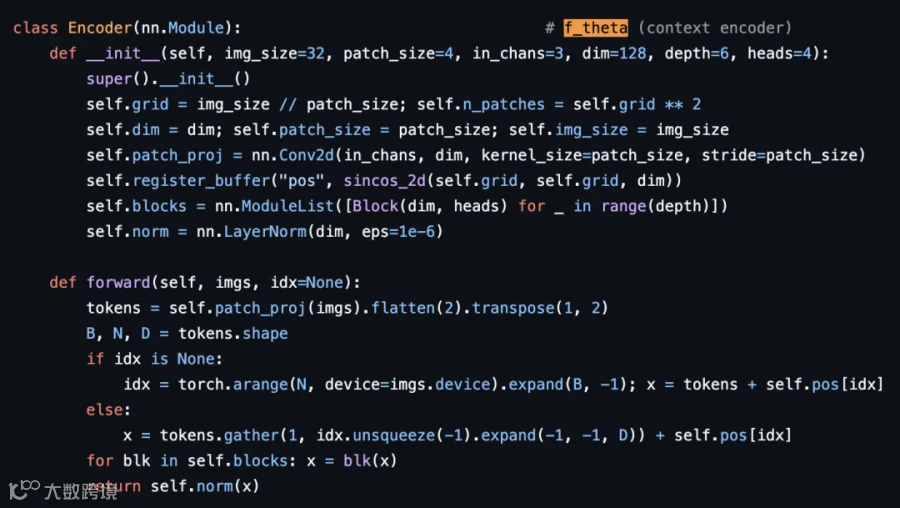
虽因模型规模与数据集简化,性能与原论文存在差距(如I-JEPA的52.7% vs ImageNet结果),但项目明确标注了实现偏差。其核心价值在于提取算法的数学本质,为理解JEPA机制提供理想起点。
项目地址:https://github.com/keon/jepa