
虹识微刊 · 论文速读 第17期
扩散模型 · 合成数据 · 虹膜识别
虹膜识别研究有一道长期绕不开的门槛:数据。
不像人脸识别——随便爬几十万张社交网络图片就能起步——虹膜数据的采集每一步都困难重重。被试必须到场配合,要签知情同意书,要经过 IRB(机构伦理审查委员会)审批,采集完之后还要妥善存储、严格授权。一旦泄露,虹膜不像密码可以重置。
结果就是:虹膜识别领域至今没有一个像 ImageNet 那样规模的公开大型数据集。学术界常用的 CASIA-IrisV4、UBIRIS.v2、ND-IRIS 等数据集,规模都在数百至数千人量级,相比人脸领域动辄百万级的训练集,差距悬殊。
这个先天不足,深刻制约了深度学习方法
在虹膜识别领域的发挥空间。
2026年3月,arXiv 上出现了一篇值得关注的论文:《Generating a Biometrically Unique and Realistic Iris Database》(arXiv:2503.11930)。作者团队用扩散模型(Diffusion Model)从零生成了一个生物特征唯一且视觉真实的虹膜图像数据库,并已完整开源至 HuggingFace。

· · ·
❶ 问题的核心:合成数据能"骗过"识别系统吗?
合成虹膜数据的研究并不新鲜。早在 GAN 全盛时期,就有研究者用生成对抗网络生成虹膜图像,试图扩充训练集。但那些工作大多只验证了视觉真实性(看起来像),却没有严格验证生物特征唯一性(每张图对应唯一的"人")。
如果合成数据只是在训练集上"复刻"了已有虹膜纹理的变体,那它对模型训练毫无意义,甚至有害——相当于用高度相关的样本反复训练,导致过拟合。更严重的安全隐患是:如果合成虹膜和真实用户的虹膜特征太接近,生成的"假人"可能意外通过真实系统的身份认证。
好的合成虹膜数据集必须同时满足两个条件:
条件 01
视觉真实性
视觉上足以以假乱真,通过人眼和图像质量审核,覆盖完整的色素分布(浅蓝到深棕)
条件 02
生物特征唯一性
与任何真实用户保持足够的 Hamming Distance,通过识别系统的"陌生人"判定
· · ·
❷ 为什么选扩散模型,而不是 GAN?
GAN 的问题在于训练不稳定,且容易出现"模式崩塌"(mode collapse)——生成器学会了用少数几种高分辨率纹理应付判别器,导致生成多样性不足。对于需要覆盖不同肤色、色素分布、纹理密度的虹膜数据集来说,多样性是硬性要求。
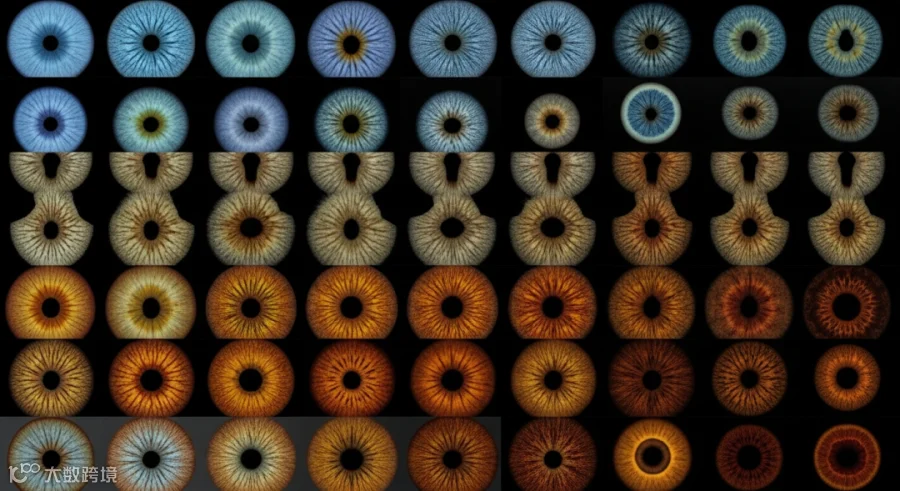
扩散模型通过迭代去噪过程学习真实数据分布,生成的样本多样性高、分布覆盖完整。作者在开源扩散框架上,以现有公开虹膜数据集为训练数据,训练了专门生成彩色虹膜纹理的模型,关键流程包括:
📌 训练数据预处理:对虹膜图像进行归一化和 rubber-sheet 展开,统一输入格式
📌 生成后处理:将展开的纹理重新映射回圆形区域,叠加真实瞳孔和边缘结构
📌 色素分布校正:在生成过程中施加约束,确保输出涵盖完整虹膜色素分布
· · ·
❸ 最严格的验证:让真实识别系统来判断
论文最核心的贡献,是设计了严格的双重验证实验:
验证一:与训练数据的生物特征距离
将所有生成的虹膜图像,与训练集中所有真实虹膜样本进行 1:1 比对,计算 Hamming Distance。结果:生成样本与所有真实训练样本的 HD 均值 > 0.45,超过虹膜识别领域公认的"不同人"阈值(通常为 0.32–0.38)。对识别系统来说,合成虹膜就是陌生人。
验证二:色素分布的完整覆盖
使用色彩直方图分析生成图像的虹膜色素分布,与真实数据集进行比对。生成数据集覆盖了从浅灰蓝(欧美高频)到深棕黑(亚非高频)的完整分布,且分布形态与真实数据集高度吻合,不存在明显的颜色偏置。
生物特征唯一 + 视觉真实 + 分布完整
三个条件同时满足,这是以前做不到的。

· · ·
❹ 三个应用方向
方向 01
低资源场景下的算法训练
对没有大规模采集体系的研究机构和初创公司,合成数据可作为预训练数据源,让模型在上实际采集数据前先建立基础特征提取能力。
方向 02
PAD 攻击样本生成
活体检测研究的瓶颈之一是获取高质量攻击样本困难。合成虹膜数据可系统性生成各类"假虹膜"样本,用于训练和评估 PAD 模型的开放集鲁棒性。
方向 03
公平性与偏差研究
现有真实数据集在人群覆盖上存在明显偏差。合成数据可按需生成特定色素分布的样本,为跨人群公平性研究提供受控的测试床。
· · ·
❺ 局限性:不要过度解读
📌 硬件噪声不可复现——真实图像中包含传感器噪声、镜头畸变等真实采集特性,域差(domain gap)在真实硬件上可能导致性能下降
📌 唯一性是统计保证——HD > 0.45 的均值不代表每张图绝对安全,极端情况下个别样本可能碰巧接近真实用户,安全敏感场景慎用
📌 当前仅支持静态图像——不包含视频序列,对多帧融合、运动补偿等视频相关研究支持有限
· · ·
合成数据在虹膜识别领域的应用,本质上是在回应一个长期存在的资源不对等问题:数据不够,不是因为算法不好,而是因为门槛太高。
扩散模型提供了一条可行路径——不是绕过这个问题,而是用技术手段降低它的成本。严格的生物特征唯一性验证,让这种路径从"可能可行"变成了"有据可查"。
下一个关键问题:合成与真实数据
以多大比例混合,模型性能才会下降?
这个数字,将决定它的工业价值上限。
📄 原论文:arXiv:2503.11930
🗃️ 开源数据集:HuggingFace — fatdove/Iris_Database
推荐阅读
《2026虹膜识别行业深度研究报告》
18000字 · 11章 · 覆盖全球虹膜识别技术现状、市场格局、核心玩家、应用场景与未来趋势
回复关键词 深度报告 获取购买链接
觉得有价值,欢迎转发给同行 🔬
ABOUT
虹识微刊
虹膜识别技术前沿媒体。每周一、四更新,面向工程师与研究者。