
虹识微刊
技术洞察 · 第 20260325 期
Vision Transformer × 虹膜识别

当 Transformer 遇见虹膜识别
ViT 正在重塑生物识别边界
Vision Transformer(ViT)正在席卷计算机视觉领域,而虹膜识别——这一被誉为"最精准生物特征"的技术——也在经历一场架构革命。从 IrisFormer 到 SwinIris,从近红外到可见光谱,Transformer 架构如何突破传统虹膜识别的性能天花板?本期深度解析三篇 A 级论文,带你看清技术演进脉络。
一、技术速读:三篇核心论文解析
IrisFormer: A Dedicated Transformer Framework for Iris Recognition
核心创新:首个专门为虹膜识别设计的纯 Transformer 架构,摒弃 CNN 局部归纳偏置,直接对归一化虹膜条带进行全局建模。
技术亮点:
- 采用 2D 相对位置编码(RoPE)处理虹膜归一化后的残余旋转
- 水平像素位移增强(Pixel-Shift Augmentation)模拟眼动偏移
- 随机 Token 掩码提升对遮挡和反光的鲁棒性
- 分块顺序匹配(Patch-wise Sequential Matching)保持局部纹理信息
VIS-IrisFormer:可见光谱虹膜识别的 Transformer 实践
核心创新:将 IrisFormer 框架扩展至可见光谱(VIS)场景,针对智能手机低质量图像捕获进行专门优化。
工程突破:
- Android 端自动化聚焦与变焦调整应用
- YOLOv3-tiny 轻量级眼/虹膜检测
- Ghost-Attention U-Net 分割网络
- 符合 ISO/IEC 29794-6 图像质量标准
Enhancing VIS Iris Recognition Through Transformer Attention
核心创新:系统研究注意力机制在可见光谱虹膜识别中的增强作用,提出多尺度特征融合策略。
关键发现:在 UBIRIS.v1/v2、MICHE、CUVIRIS 等公开数据集上,基于注意力的方法显著优于传统手工设计特征(如 Gabor 滤波器组)。
二、技术拆解:为什么 Transformer 适合虹膜识别?
Vision Transformer 在虹膜识别中的典型架构流程
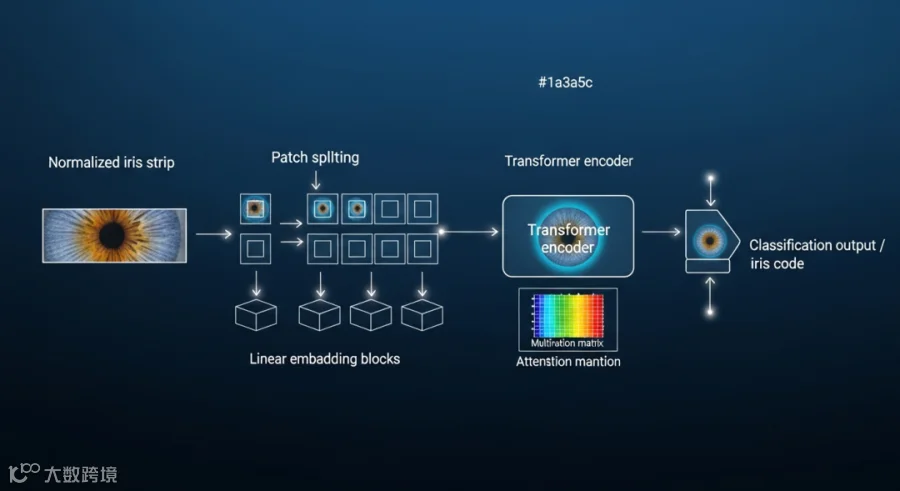
2.1 从 CNN 到 ViT:归纳偏置的取舍
传统虹膜识别系统(如 OSIRIS)依赖 Gabor 滤波器组提取纹理特征,深度学习时代则普遍采用 CNN 架构。但 CNN 的局部感受野和平移等变性在面对虹膜图像时存在固有局限:
- 长程依赖建模困难:虹膜纹理的径向分布特征需要大尺度上下文理解
- 旋转鲁棒性有限:归一化后的残余旋转需要显式处理
- 纹理细节丢失:池化操作可能抹去细粒度虹膜特征
Transformer 的自注意力机制天然具备全局感受野,通过 Query-Key-Value 计算,每个位置都能直接关注图像中任意区域——这对捕获虹膜纹理的分布模式至关重要。
IrisFormer 证明:在虹膜识别任务上,纯 Transformer 架构(无 CNN 预处理)可以达到甚至超越 CNN+手工特征融合的方案。关键在于输入表示和位置编码的设计。
2.2 IrisFormer 的核心设计哲学
IrisFormer 并非简单套用 ViT,而是针对虹膜识别的领域特点做了三方面针对性优化:
① 2D 相对位置编码(RoPE)
虹膜归一化后呈矩形条带(64×512),但实际捕获时仍存在细微旋转。2D RoPE 允许模型感知 patch 之间的相对位置关系,同时保持对水平位移的适度容忍——这与眼球的自然运动模式吻合。
② 水平像素位移增强
在训练时随机对归一化图像进行水平方向像素平移(shift_pixel=14),模拟不同捕获时刻的眼位差异。这种数据增强策略显著提升了模型对真实场景旋转变化的泛化能力。
③ 分块顺序匹配
不同于传统方法提取全局特征向量,IrisFormer 保留所有 patch 的特征序列,通过余弦相似度的序列匹配计算两幅虹膜的相似度。这种方式:
- 保留了局部相似性信号
- 允许局部遮挡/反光区域的容错
- 与人类专家比对虹膜纹理的直觉更接近
三、行业雷达:从实验室到产品化的关键路径
3.1 可见光谱(VIS):移动场景的突破口
传统虹膜识别依赖近红外(NIR)成像,需要专用硬件。而可见光谱虹膜识别直接使用普通摄像头,是移动端部署的必由之路。
但 VIS 场景面临独特挑战:
- 光照敏感性:环境光变化导致虹膜外观剧烈改变
- 色素差异:深色虹膜在 VIS 下纹理对比度显著降低
- 图像质量问题:手机摄像头对焦、运动模糊等因素
VIS-IrisFormer 的解决方案值得借鉴:
- 质量保障层:通过 YOLO 检测+轻量分割网络,在捕获端就拒绝低质量图像
- 跨光谱对齐:针对 NIR 注册/VIS 识别的混合场景,优化特征空间一致性
- 端到端优化:从图像捕获到特征匹配的全链路调优
3.2 性能对比与工程权衡
当前 SOTA 在标准数据集上的表现:
技术选型建议:NIR 场景可追求极致精度,VIS 场景需优先考虑鲁棒性和用户体验。
3.3 未来演进方向
基于当前研究趋势,我们认为以下方向值得重点关注:
① 自监督预训练
虹膜数据的标注成本高昂,利用大规模无标注数据进行自监督预训练(如 MAE、DINO 框架)有望进一步提升小样本场景性能。
② 神经架构搜索(NAS)
针对移动端算力约束,自动搜索最优的轻量化 Transformer 变体(如 MobileViT、EfficientFormer 的虹膜定制版)。
③ 对抗鲁棒性与隐私保护
随着深度学习在虹膜识别中的普及,对抗攻击威胁日益凸显。同时,可撤销生物特征模板(Cancelable Biometrics)的工程实现也需要与深度特征提取框架深度耦合。
四、虹识视角:我们的思考与实践
作为专注虹膜识别十余年的技术团队,我们对这一波"Transformer 浪潮"有以下观察:
Transformer 为虹膜识别提供了新的架构选择,但并非银弹。对于高精度 NIR 场景,传统 CNN+注意力融合的混合架构仍有竞争力;对于资源受限的移动场景,轻量 Transformer 是值得探索的方向。
虹膜识别的落地瓶颈从来不是单一算法指标,而是完整体验闭环——从引导用户对准、质量实时反馈、到误识率的合理预期管理。VIS-IrisFormer 类工作在捕获端的质量保障值得参考。
随着 OVAI 等新一代 AI 驱动虹膜系统的推出,算法、芯片、传感器的垂直整合能力将成为核心竞争力。Transformer 架构的灵活性,为我们持续迭代算法-硬件协同设计提供了更大空间。
- IrisFormer 开源代码:github.com/XianyunSun/IrisFormer
- VIS-IrisFormer 实现:github.com/naveengv7/Vis-IrisFormer
- 虹识技术 OVAI 系统:www.homsh.cn/ovai