

本文发布已获得《都市快轨交通》授权
原文发表于《都市快轨交通》
2025年 第1期
如有转载请联系版权方,标明出处

管洋1, 2,贾利民1,陶思涵1,豆飞3
1研究背景
随着城市轨道交通的快速发展,确保乘客安全已成为公共安全管理的重要部分。当前,视频监控系统作为安全管理的关键技术,在实时监控和异常行为识别方面发挥着核心作用[1-2]。尽管如此,目标检测与异常行为识别在复杂场景下仍面临挑战,特别是在高峰时段和多种遮挡条件下的效果不佳,这主要是由于传统方法高度依赖于视频质量和监控角度[3]。传统方法在视频监控图像异常行为识别应用中效果不佳,存在漏识率较高,且识别用时较长等问题[4]。目标检测技术是视频监控系统中的基础,它涉及在图像中自动识别和定位人体等目标物。尽管传统算法如方向梯度直方图(histogramoforientedgradient,HOG)和基于部件的可变型模型(deformablepartmodel,DPM)在目标检测方面取得了进展,但它们在遮挡和动态背景下的应用效果有限[5]。近年来,深度学习的兴起带来了新的解决方案,如如基于区域的卷积神经网络算法(regionswithCNNfeatures,R-CNN)[6]和YOLO算法(youonlylookonce)[7],它们通过学习大量数据提高检测的准确性和鲁棒性[5]。这些算法已广泛应用于不同场景的目标检测任务中,但在城市轨道交通复杂环境中的表现仍有待提升[1]。在异常行为识别领域,现有技术多依赖于复杂的前处理和后处理技术。虽然基于深度学习的方法在一些标准数据集上表现良好,但它们在实际应用中往往因视角变化、遮挡和光照变化等问题而受限[8]。例如,刘雨萌等[3]提出基于关键帧定位的人体异常行为识别模型,通过筛选和提取视频中的关键帧来提高识别效率。
然而,这些方法在处理高密度客流和复杂背景时,仍存在一定的局限性[9]。人体骨架识别技术,特别是AlphaPose[10]和OpenPose[11]等模型,通过提取人体关键点估计姿态,显示了在复杂环境下识别人体动作的巨大潜力。AlphaPose[10]模型采用区域多人姿态估计技术(regionalmulti-personposeestimation,RMPE),显著提高了在复杂背景下的识别准确率[5]。这些技术能有效地从遮挡和动态背景中识别出人体,为进一步的行为分析提供了基础[11-12]。此外,通过结合时空图卷积网络(spatial-temporalgraphconvolutionalnetwork,ST-GCN)模型,进一步分析人体动作的时空序列变化,进而提高异常行为的检测精度和效率。现有的视频分析技术中,行为识别算法已取得了一定进展。例如,吴田等[9]提出基于改进ST-GCN的10kV带电作业人员视频异常行为识别方法,通过引入通道注意力模块提升了识别准确率。此外,章东平等[8]提出的基于多通道耦合的时空增强异常行为检测方法,通过引入时间增强模块和空间增强模块,从而提高了特征提取的效果。本研究基于城市轨道交通视频监控系统,整合了前沿的目标检测与人体骨架识别技术,开发了一种高效的异常行为识别系统。系统采用AlphaPose模型提取区域多人行为特征,结合时空图卷积网络(ST-GCN)深度分析人体动作时空序列变化,能有效识别诸如摔倒、晕倒及打斗等复杂监控场景中的异常行为。
2基于AlphaPose模型的乘客行为特征提取
2.1AlphaPose人体姿态估计模型
人体姿态估计是目前计算机视觉领域的一个重点研究方向,其通过算法来对视频或图像中的人体进行关键点位置的识别,从而进行姿态估计,被广泛应用于智能监控、动画制作等领域。在多人姿态估计领域,目前主要存在两种框架,即自顶向下(top-down)和自底向上(bottom-up)。本文面向的场景是城轨车站,这类场景面临着客流聚集、遮挡严重等问题,因此应部署多视角监控,覆盖车站不同的区域,避免漏检目标,同时使用高分辨率设备,提升高密度人流中人体特征识别质量。综合考虑硬件设施资源和视频分析框架对自底向上和自顶向下方法的处理,可以得出以AlphaPose人体姿态估计模型为代表的自顶向下方法更适用于这类复杂场景。因此,本文选择AlphaPose模型进行城轨车站内的乘客行为特征提取。不同于其他模型,AlphaPose采用区域多人姿态估计框架(RMPE)代替单人姿态估计框架(single-personposeestimation,SPPE),解决了检测框定位错误和姿态冗余的问题,有效提升了算法的性能。RMPE框架主要由对称空间变化网络(symmetricspatiotemporaltransformernetworks,SSTN)、姿态引导区域框生成器(pose-guidedproposalsgenetrator,PGPG)和参数化非极大值抑制(parametricposeNMS,P-NMS)组成,如图1所示。
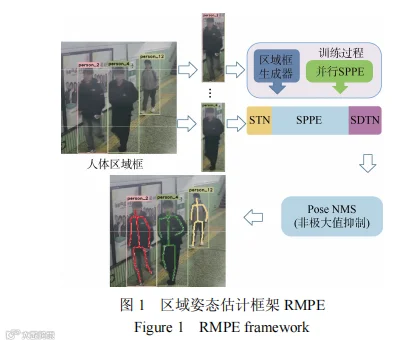
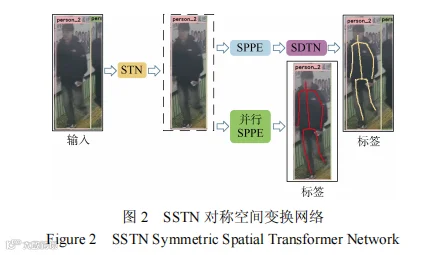
第一个组成部分对称空间变化网络(SSTN)主要用于解决检测框定位错误的问题,由空间变换网络(spatialtransformernetworks,STN)和反向空间变换网络(spatialde-transformernetworks,SDTN)两部分组成,如图2所示,当检测框质量较差时,利用空间变换重新调整检测框使目标人体位于检测框的中心,优化检测效果。GPG考虑应用环境以及人体在监控中被截断的可能性,根据不同人体姿态检测器的分布生成额外的检测框用于SSTN+SPPE模块的训练,以此进行数据增强,这种做法能够大大提升姿态估计的准确度。
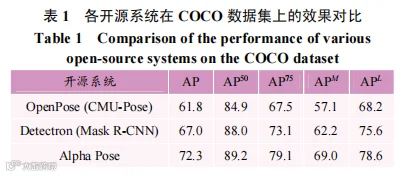
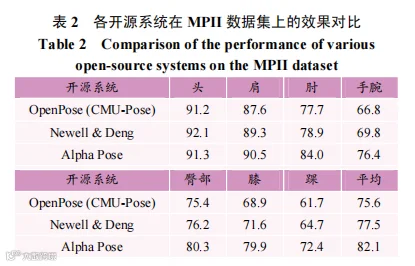
P-NMS则使用新的姿态距离度量方法消除多余的姿态,提高人体姿态估计的精度。P-NMS由置信度消除和距离消除两种消除标准组成,置信度消除是指置信度相似的关节点,而距离消除则是指位置相近的关节点,只要满足二者之一即会被消除。消除过程如下:以得分最高的姿态作为基准,消除与之相近的其他姿态,直至剩下单一姿态为止。基于上述改进点,AlphaPose作为一种自顶向下的多人姿态估计模型,首次在COCO数据集上达到72.3mAP,相对于运用自底向上框架的OpenPose模型提高17%,如表1所示。此外,AlphaPose在MPII数据集上也表现优异,达到82.1mAP,具有较高的精度和跟踪速度,如表2所示。
2.2数据集及关键点标注方案
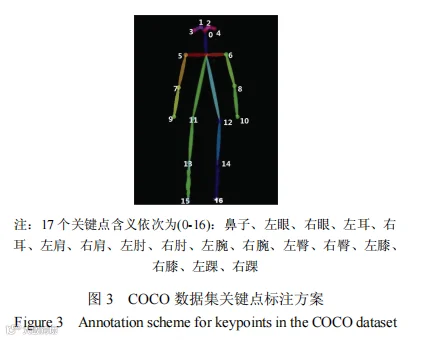
本文选用COCO数据集进行AlphaPose人体姿态估计模型的训练。COCO数据集是一个包含大规模图像、字幕和对象类别的数据集,主要用于对象检测、分割等任务[13]。其中,COCO数据集中的关键点标注方案如图3所示,对于每一个人体,都有17个关键点数量,各个关键点代表的含义如表3所示
3基于ST-GCN的乘客行为特征识别
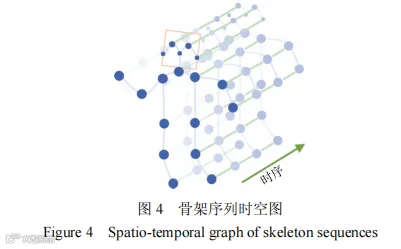
在运用AlphaPose人体姿态估计模型提取出乘客行为特征后,使用时空图卷积网络模型(ST-GCN)对乘客行为特征进行识别,判断其属于哪一类行为动作。图4所示为ST-GCN的骨架序列时空图,蓝点表示身体的关节,人体关节之间的连接根据人体自然构造来定义,帧间边根据视频连续帧之间的相同关节来连接。ST-GCN结构为堆叠时空块的层次结构,其内部由空间卷积(GCN)和时间卷积(TCN)组成。
空间卷积模块具体实现公式为
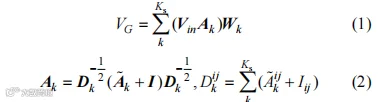
式中,VG为空间卷积的特征结果;Vin为输入的节点特征向量矩阵;Ks为在空间维度上的卷积核;Ak为卷积核内连接无向图的相邻矩阵;Wk为在训练过程中可学习权重矩阵;Dk是度矩阵;A% k是对原始邻接矩阵Ak的变换处理,I为单位矩阵;Dkij是度矩阵Dk中对应元素的计算结果。时间卷积模型(TCN)是基于空间卷积模块的输出,引入时间维度的卷积(V,T),具体实现公式为
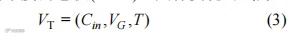
式中,VT为时空卷积输出特征,Cin为输入通道数;T为时间维度。图5所示为ST-GCN网络。基于ST-GCN网络,使用人体姿态估计算法对输入的视频序列进行姿态估计,获得关节点的坐标,其次以人体自然构造和时间作为连接构建骨架序列时空图,之后应用多层时空图卷积对其进行卷积,逐步生成更高层次的特征图,最后运用标准Softmax分类器将其分类到相应的动作类别,实现人体姿态的识别。
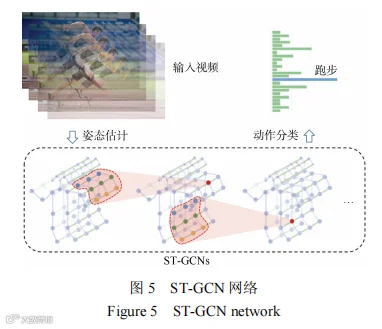
4乘客行为特征辨识
4.1数据集构建
常见的需要识别的乘客行为包括行走、坐立、站立等正常行为,以及摔倒、晕倒、打架斗殴等对自身及车站客流状态危害较大的异常行为。本文所使用的ST-GCN模型提供了预训练权重,为提高数据集的质量,使最终训练得到的模型能够更好应用于城轨车站场景下,本文以北京地铁西直门枢纽站为场景面向城轨车站的乘客行为收集数据集,并将其运用于预训练模型的增量训练中,以期得到更好的模型效果。图6展示了收集的城轨车站乘客行为数据集的部分视频图像。经过筛选,本数据集共有2000余张视频图像投入最终训练,数据集类别包含摔倒、晕倒、打架斗殴、行走、坐立、站立六种不同行为类别图像各400余张,其中摔倒、晕倒、打架斗殴为异常行为数据,行走、坐立、站立为正常行为数据。在样本预处理阶段,使用尺度不变特征变换(SIFT)特征匹配方法,评估视频图像质量,过滤掉畸变的样本数据。

4.2模型训练
本实验通过AutoDL提供的环境进行训练,CPU为12vCPUIntel(R)Xeon(R)Platinum8255CCPU@2.50GHz,GPU为RTX3090(24GB)*1,内存为43GB,操作系统为ubuntu20.04,开发语言为Python3.8,深度学习框架为Pytorch1.11.0。基于深度学习训练平台,将收集的城轨车站乘客行为数据集投入模型的训练中。随机抽取数据集的20%作为测试集,其余的80%则作为训练集。模型训练需要对数据预处理,首先基于Excel表格逐帧对城轨车站乘客行为视频图像进行行为类别标注,其次利用预先训练好的AlphaPose模型提取每帧视频图像的人体骨骼关节的坐标,然后对所得人体骨骼关节的坐标数据进行归一化处理等,得到最终输入模型训练的数据。基于上述所得数据进行ST-GCN时空图卷积网络模型的训练,训练参数的设置为批处理大小取值32,迭代轮数为50,类目数为6,学习率为0.001。在训练过程中,选取Adam优化器进行神经网络模型参数的更新及优化,同时选取交叉熵作为损失函数,判断模型在样本上的表现。Adam优化器的更新方法为
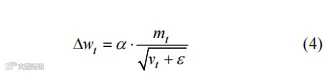
式中,Δwt为第t步参数的更新量;α为学习率;ε为能够使分母稳定的系数;mt为一阶矩;vt为二阶矩,交叉熵损失函数计算式为
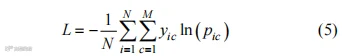
式中,N为样本量;M为类别数;yic为符号函数,当样本i的真实类别为c时则取1,否则为0;pic为样本i属于类别c的概率,机器学习函数处理中默认是自然对数为底,因此常用log函数代表ln函数。
4.3训练结果分析
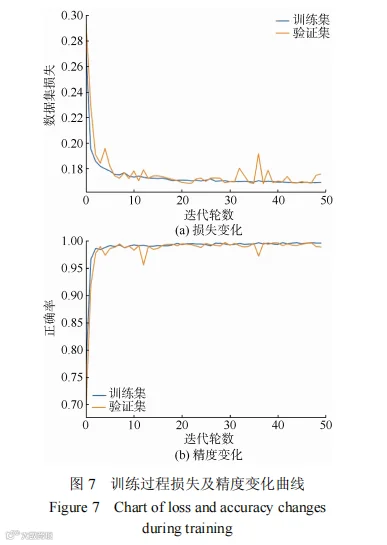
利用plt函数绘制出训练集和测试集的损失及精度变化曲线,如图7所示,训练集的训练效果较好,训练曲线能够在短时间内较好地收敛;测试集的训练曲线有所波动,但在训练约10轮后其损失及精度曲线也均趋于平稳。最终在经过50轮训练后,训练集的精度达到99.66%,测试集的精度达到99.49%,平均精度达到99.59%。
4.4乘客行为特征辨识过程
在得到训练好的模型后开始乘客行为特征的辨识,具体过程如下:
1)输入城轨车站视频采集装备采集到的监控视频图像。
2)利用AlphaPose人体姿态估计模型提取目标乘客的人体骨架序列。3)利用ST-GCN时空图卷积网络模型对提取的人体骨架序列进行分析,识别目标乘客的行为特征。4)输出乘客行为特征辨识结果。
4.5乘客行为特征辨识结果展示
运用AlphaPose人体姿态估计模型提取目标乘客人体骨架序列,再利用ST-GCN分析人体骨架序列,从而识别出目标乘客的行为特征。基于视频图像的车站乘客行为特征辨识结果如图8所示,对于车站内乘客的行为类别(如打架、躺倒、逗留和坐座等)均能较为准确地识别。

5结论
本研究利用人体骨架技术,通过AlphaPose模型精准地估计乘客的人体姿态,并结合ST-GCN模型深入识别其行为特征,实现了视频图像中乘客行为类别的准确判定。主要结论如下:1)通过对AlphaPose多人姿态估计模型的若干改进,在COCO数据集上具有72.3mAP,在MPII数据集上具有82.1mAP的较高精度和跟踪速度。2)基于深度学习训练平台进行实验,在50轮训练后,训练集和测试集分别达到了99.66%和99.49%的高精度,平均精度达到99.59%。3)利用ST-GCN时空图卷积网络模型对提取出来的人体骨架序列进行分析,识别目标乘客的行为特征,能有效识别诸如摔倒、晕倒及打斗等复杂监控场景中的异常行为,对于提升城轨车站的安全管理水平具有显著意义。未来,该技术有望在城市交通安全管理领域发挥更加重要的作用。
消息由中国城市轨道交通网CCRM整理编辑,文章来自都市快轨交通,涉及版权请联系删除,如有转载请标明出处)

