

本文发布已获得《都市快轨交通》授权
原文发表于《都市快轨交通》
2025年 第6期
如有转载请联系版权方,标明出处

闵思远1, 2,孟新宇1, 2,张锐骥1, 2,辛开元1, 2,殷勇1, 2
随着城市智能轨道快运系统(简称智轨)出行需求和运营规模的持续扩大,其在公共交通领域的大规模应用正面临着新的安全挑战。据统计数据显示[1],在智轨系统运营过程中,由人为因素引发的安全事故占比高达运输事故总量的 82.3%,其中由驾驶人员疲劳状态所致的安全隐患尤为突出。疲劳状态会对驾驶员警觉度、感知能力、决策力等多个方面产生负面影响,极易导致交通事故,研究表明驾驶员因其疲劳状态发生的事故损伤程度是清醒情况下的 3.3 倍[1]。因此,研究疲劳驾驶检测非常重要。
围绕疲劳检测的实现路径,现有疲劳驾驶检测系统按传感器类型可分为基于车辆特征、生理特征和面部特征3 类。然而,复杂的驾驶环境可能会降低基于车辆特征的疲劳检测准确性。脑电图(electroencephalo-graphy,EEG)、心电图(electrocardiogram,ECG)等生理信号是直接衡量疲劳的标准,但该类生理特征的收集需要将传感器贴附在人体皮肤上,这可能会引起驾驶员不适,进而影响驾驶员的正常驾驶行为。基于面部特征的疲劳检测以其直观性强和非侵入式的优势得到广泛应用。因此,利用驾驶员面部特征进行疲劳检测成为近年来较为热门的研究方法。CHANG等[2]提出一种基于驾驶员视频分析非侵入式的疲劳检测系统,以闭眼持续时间作为参数,再使用眼睑闭合百分比(PERCLOS)[3]对驾驶状态进行分类。这种方法使用传统的机器学习库提取眼睛和嘴巴的特征,使用固定阈值计算疲劳状态,其准确率有待提高。为提升预测准确率,FRIEDRICHS 等[4]在18 种不同眼部特征中筛选,最终发现以PERCLOS和睁眼速度作为特征参数的准确率最高。为进一步提升检测速度和精度,LI等[5]引入改进的YOLOv3 模型来捕捉人脸面部区域,并利用眼部特征向量和嘴部特征向量计算闭眼时间、眨眼频率和哈欠频率,从而评估驾驶员的疲劳状态。ZHANG等[6]利用红外视频检测,提出一种基于卷积神经网络(convolutionalneuralnetwork,CNN)的眼部状态识别方法,最终通过计算PERCLOS和眨眼频率来检测疲劳程度,但此时疲劳检测的判断仅依赖于眼部状态。为增加特征维度,DWIVED 等[7]通过深度学习对用于疲劳检测的特征进行了筛选,并整理出可用于疲劳检测的特征。LIU 等[8]提出一种基于卷积神经网络和长短期记忆(longshort-term memory,LSTM)的驾驶员疲劳检测方法,将PERCLOS、嘴部特征和脸部方向作为参数,并将连续时间序列上的这些特征参数输入到
LSTM 中,完善了 CNN 不能提取时序信息的缺点。
虽然基于视觉的疲劳检测技术已经取得较好进展,但仍存在一些待解决的问题。本文提出一种新的智轨驾驶员疲劳检测模型。首先,提出基于眼睛纵横比、嘴部纵横比及头部姿态的多面部特征融合方案,并引入纵向头部巡视行为频率作为智轨场景下的分心检测专属特征;然后,在双向长短期记忆网络(bidire- ctional long short-term memory,Bi-LSTM)上融合时间注意力机制,对序列帧按重要性加权,并将特征编码层与注意力化的 Bi-LSTM 结合,实现具备时序上下文感知的疲劳判断,满足实时推理要求;最后,基于混合数据集(公开数据+ 自建智轨匹配样本)进行训练与评估,以场景适配性为导向的数据预处理与标注策略。
1 模型方法
本文提出了一种基于深度学习的智轨驾驶员疲劳检测模型,该模型以相机采集的驾驶员面部视频作为输入,结合使用了开源机器学习与计算机视觉库(Dlib)、多尺度特征编码(heteroscale-temporal encoder, HSTE)和Bi-LSTM,并在 Bi-LSTM 上融合了时间注意力机制(time atention mechanism ,TAM)。
疲劳检测算法主要由 3 个阶段组成,包括人脸关键点检测、面部特征提取和驾驶状态分类。
在人脸关键点检测阶段,Dlib 基于稀疏像素强度数据子集得到视频流中每帧的关键点位置信息,其检测结果直接决定了后续面部特征的提取及疲劳驾驶检测的准确性[9]。
在特征提取阶段,依据关键点的坐标信息计算得到驾驶员的眼部、嘴部及头部姿态的 5 个疲劳特征参数,并通过 HSTE 为后续的 Bi-LSTM 网络提供高阶时序编码。同时,基于头部姿态提出了纵向头部巡视行为频率智轨场景下的专属特征,用以实现驾驶员分心行为的判定。
在分类阶段,使用基于时间注意力的 Bi-LSTM 捕捉不同疲劳行为与时间序列之间的依赖相关性,最终基于 Softmax 模块输出每个驾驶片段是否疲劳的二分类结果。智轨驾驶员疲劳检测算法的总体架构如图 1所示。
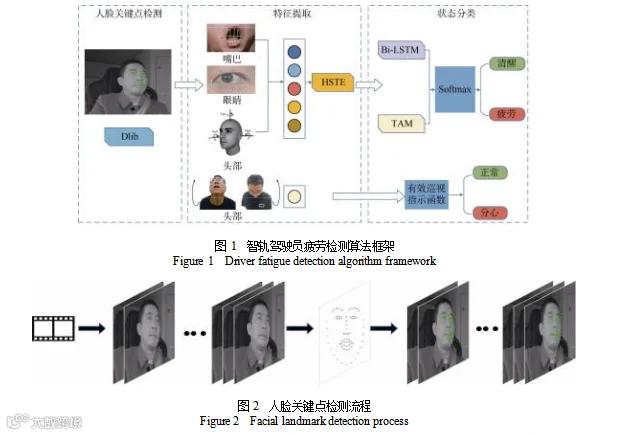
1.1 面部特征提取
1.1.1 基于 Dlib 的人脸关键点检测
本文选用 Dlib 提取驾驶员人脸细粒度特征,Dlib是一个基于现代 C++开发的工具库,集成了机器算法和工具组件,包含了 68 个面部关键点检测模型,该模型由数百万张人脸训练而成。该方法检测人脸时,通过级联形状回归,直接从稀疏的像素强度数据子集中估计面部关键点的位置,兼具高精度与耗时低的特性,
1.1.2 基于几何的面部特征
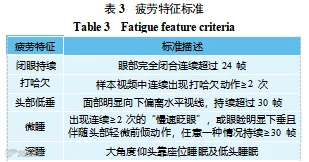
1) 眼睛纵横比。眼睛纵横比(eye aspect radio, EAR),即眼睛的长宽之比。当驾驶员眼部为睁开状态时,EAR 值较大,当为闭合状态时,EAR 值较小。所以本文选用眼睛纵横比值作为衡量驾驶员眼部开合大小的特征,用于检测驾驶员眼睛是否闭合。
首先利用 Dlib 对视频流中的驾驶员面部进行标记,得到眼部关键点的定位如图 3 所示。再利用眼部关键点坐标信息,得到点之间的欧氏距离来计算 EAR,最终 EAR 的值由左眼和右眼同权重计算。EAR 的计算式为:
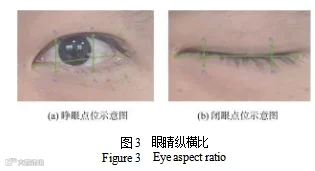
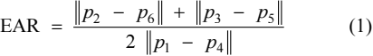
式中,p1~p6 为人眼周围的 6 个关键点的二维坐标。
2) 嘴部纵横比。嘴部纵横比(mouth aspect ratio, MAR),即嘴部的长宽之比。当驾驶员打哈欠时,MAR值较大,当为闭合状态时,MAR 值较小,所以本文选用 MAR 值作为衡量驾驶员嘴部开合大小的特征, 利用嘴部状态判断驾驶员是否进行打哈欠行为。
同EAR 值相似,使用Dlib 得到的嘴部关键点的定位如图4 所示。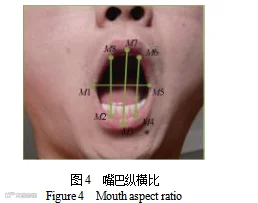
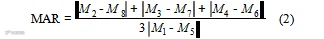
式中,M1~M8 为人脸的 8 个关键点的二维坐标。
3) 头部姿态。当驾驶员产生瞌睡动作时,即点头或歪头,其俯仰角或翻滚角会瞬间变大,因此本文选用 θPitch(头部俯仰角,绕 X 轴旋转角度) 、θYaw(头部偏航角,绕 Y 轴旋转角度) 、θRoll(头部翻滚角,绕 Z 轴旋转角度)作为衡量驾驶员疲劳状态的特征。
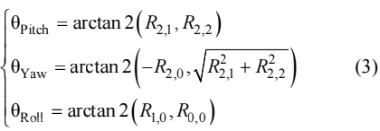
式中:θPitch 、θYaw 、θRoll 分别为头部俯仰角、头部偏航角、头部翻滚角的值;Ri, j 表示旋转矩阵 R 的第 i 行,第j 列元素。

基于式(1)、(2)、(3),得到特征 EAR、MAR、θPitch、 θYaw,θRoll 的值,但由于不同指标量纲不同,需对所有得到的特征值进行标准化处理,消除量纲差异。本文使用 Z-Score 标准化将不同尺度的数据转换为均值为0、标准差 1 的标准正态分布,使得模型可以均衡学习不同量纲特征,保证梯度平稳,进而提升模型收敛速度,转换式为
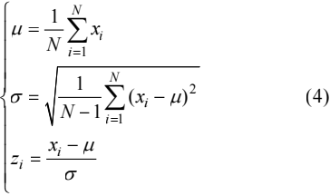
式中,μ 为每个特征值所有数据点的平均值;σ 为标准差;zi 为最后标准化后的数据;N 为样本总数;xi 为对应特征值(5 种特征值处理方式一致)。
4) 纵向头部巡视行为频率。自动循迹模式下,驾驶员需周期性检查仪表盘信息与前方路况,以确保能够随时接管车辆,这一操作行为通常伴随着规律性的低头与仰头动作。为此,本文提出纵向头部巡视行为频率作为新特征量化操作频率,用于建模该类周期性头部姿态变化,以检测驾驶员因分心导致的操作不规范。
在每一个独立的 1 min 时间窗口内(不跨分钟计算),在任意连续 15 帧内,若驾驶员头部俯仰角从 5°~15°下降至–15°~5°[11],并在随后 15 帧内再次回到5°~15° ,
则视为一次有效的纵向头部巡视行为。当 Ns(can) ≤ 1
时,表明第 m min 驾驶员未能按规定周期性检查仪表盘与路况,判定为分心状态,反之则为正常。
有效巡视指示函数定义为

式中:s 、s1 、s2 为视频帧序号,m 为分钟序号。
第 m min 巡视次数的定义为
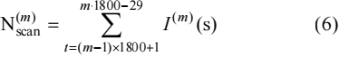
1.1.3 多尺度特征提取及时序编码
在进行驾驶疲劳状态分类前,提出了 HSTE 模块,用于承担多尺度时间特征提取和时序信号压缩编码任务,为后续的 Bi-LSTM 网络模型提供更有效的高层次特征,提高驾驶员疲劳检测模型的整体性能。网络架构细节如表 1 所示。
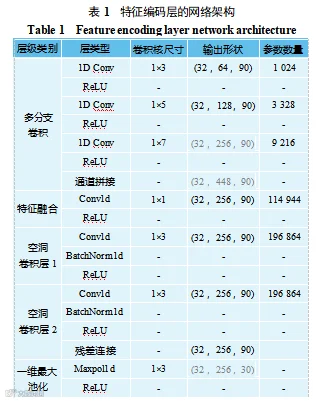
该网络首先将包含5 个特征的时间序列作为输入,经 3 个并行的卷积分支提取多尺度特征,卷积核大小分别为 3、5、7,小核可聚焦局部细节,如眼部瞬时闭合,大核可提取长段上下文特征,如头部姿态连续变化。其次,通过通道拼接和特征融合,保留各分支原始特征信息,避免因池化导致信息丢失。再次,经过残差空洞卷积扩展时序感受野,结合残差连接稳定梯度传播。最后,通过最大池化压缩序列长度,得到特征维度 256 的时间序列。
1.2 基于 Bi-LSTM 与 TAM 的疲劳状态分类
正常人的眨眼、打哈欠或者低头等行为都是一个动态的连续过程,持续时间约为 1~2 s,仅依赖单帧图像中的面部状态无法准确判断是否疲劳。因此,在视频数据中,驾驶员疲劳状态会在阶段时间内的动作中得到体现。为了通过连续帧特征之间的关系来确定驾驶员的当前状态,本文使用了特殊类型的循环神经网络(recurrent neural network ,RNN),即长短期记忆网络(LSTM)[12],并引入了注意力机制,动态调整时序数据上不同时间步的权重,以加权聚焦于更重要的疲劳信号。
本文提出的基于时间注意力机制的 Bi-LSTM 网络架构如表 2 所示。
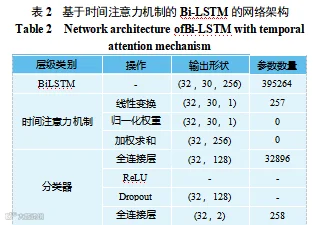
双向长短期记忆网络作为一种特殊的 RNN,由两个独立的 LSTM 网络组成[13]:一部分按照序列的正向顺序处理数据,另一部分按照反向顺序处理数据,并共同决定最终的输出值,输入数据序列经 Bi-LSTM 得到一系列正向和反向的隐藏状态,函数式为
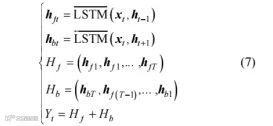
式中,xt 为时间步 t 的输入向量;ht–1 为上一个时刻的隐藏状态;hft 为前向 LSTM 的隐藏状态;hbt 为后向
LSTM 的隐藏状态;LSTM 为前向传递网络;LSTM为后向传递网络; Yt 为前后向合并的隐藏状态;T 表示时间步的总长度,即序列的最后一个时间点的索引。
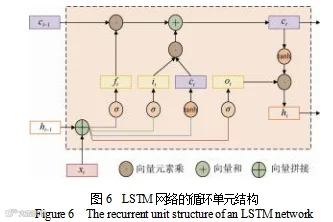
LSTM 网络的循环单元结构如图6所示,ht为当前时刻的隐藏状态;ct为当前时刻的细胞状态;ct–1为上一个时刻的细胞状态;ft是遗忘门,决定丢弃多少信息;it是输入门,决定写入多少新的信息到细胞状态;
t是候选细胞状态,表示要加入细胞状态的新信息;ot是输出门,决定从细胞状态输出多少到ht;σ 是sigmoid 激活函数;tanh是双曲正切激活函数。LSTM通过遗忘门、输入门和输出门协同工作,对细胞状态进行选择性遗忘、更新与输出,从而能够存储并动态调整历史信息。然而,传统 LSTM 仅依赖过去观测,缺乏对未来时刻信号的利用,容易在序列开头或末尾对关键疲劳动作(如闭眼持续、频繁点头)做出错误或迟滞判断。疲劳状态具有持续性,比如闭眼持续时间变长、频繁点头等,体现这些疲劳行为的特征在时间序列中具有一定的前后关联,而双向长短期记忆网络可以捕获前向和后向的信息,结合未来几帧的数据信息可以辅助验证当前状态的决策,减少决策误判,显著提升模型的预测精度。
尽管 Bi-LSTM 在时序依赖建模上较 LSTM 有明显优势,但序列中各时间步权重相同,无法主动区分高价值关键帧与普通帧,导致模型在多场景下的检测性能波动较大。基于此,本文在 Bi-LSTM 基础上引入时间注意力机制,通过对每个时间步的隐藏状态计算注意力得分并归一化为权重,使模型自动聚焦于关键疲劳信号所在帧。这样既保留了双向上下文的优势,又能在序列中突出闭眼、点头等动作的重要性,显著提升了模型的鲁棒性与精度。
2 实验结果与分析
为验证所提模型在精度与实时性上的优越性,量化各模块对序建模能力的实际增益,本文先基于公开数据集 YAWDD 与自建男性驾驶员数据,经过筛选、切片、Dlib 特征提取与 Z-Score 标准化,构建数据集并设置训练超参;再通过模型对比实验(与 RetinaFace+ ERT、HOG+CNN 比较)评估所提算法的整体检测性能,并用逐步递进的消融实验考察各关键组件对准确率、推理时间和 AUC(ROC 曲线下面积)的独立贡献。
2.1 数据集收集与预处理
本文数据集采用了公开数据集YAWDD[14]与自建数据集:YAWDD 包含57名男性及50名女性志愿者的模拟驾驶视频,覆盖多年龄、种族和面部特征,记录不同光照条件下的正常驾驶、闭眼、打哈欠等行为;鉴于宜宾智轨驾驶员群体中36~50 岁男性占比达88%,自建数据集通过模拟驾驶平台,采集10 名男性驾驶员(含28岁1名、52岁1名、36~50岁8 名)的30 段视频(总时长50 min),重点捕获正常驾驶、长时间闭眼、打哈欠、头部大角度转动、后仰及瞌睡状态等行为,以适配实际应用场景。
因当前智轨驾驶员都为男性,为与智轨工作场景匹配,本实验对 YAWDD 数据集进行以下处理:去除女性驾驶员视频及佩戴墨镜的男性驾驶员视频,剩余共计243 段。两种数据集视频原始帧率都为30,为提升样本数量,本文将驾驶视频切割为共计90帧的视频片段,共计获得样本4 072 份。依据表3 所列的疲劳特征标准,对所有视频样本进行人工标注:完全符合判定标准的样本标记为疲劳状态,其他样本标记为清醒状态。经4 人复核验证,最终获得疲劳样本3 563 份,清醒样本509份。将混合后的疲劳驾驶数据集按7︰2︰1的比例划分为训练集、验证集和测试集,数量分别为训练集2851 份、验证集814份、测试集407份。然后,使用Dlib提取视频数据集中的特征数据,针对时序特征中的异常值,剔除超出合理范围的数值,使用前后两帧的均值进行填充,再对得到的数据进行Z-Score 标准化。
在训练过程中,使用训练集数据进行迭代训练,得到本文所提出模型的有效参数,然后利用验证集确定模型的最优参数,最后,使用测试集验证模型的整体准确性。
2.2 实验环境与评价指标
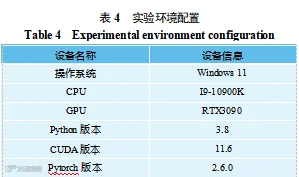
在本文实验中,批量大小设定为 32,训练 100 个周期,初始学习率设定为 0.0001,L2 正则化系数设定为 0.001,防止模型过拟合,提升泛化能力。实验环境配置如表 4 所示。
针对二分类问题,预测结果通常存在着4 种互斥的预测情况,一般情况下用TP、TN、FP、FN代表4 种预测结果。TP为样本是正类,模型预测结果也为正类;TN为样本是负类,样本预测结果也为负类;FP是样本实际为负类,但模型误判为正类;FN 是样本实际为负类,但模型误判为正类。本文使用准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1 值(F1-Score),共4 种评价指标评估模型优劣,其相关计算式为

2.3 模型对比实验
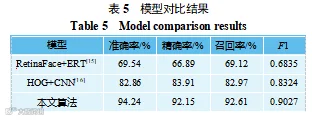
为验证本文算法模型检测性能,将不同模型基于同一数据集训练测试,最终得到不同模型的 4 种指标评价结果,如表 5 所示,基于 RetinaFace+ERT 模型的疲劳检测仅对人眼特征进行提取,疲劳状态的判断完全依赖于眼睛状态,忽略其他部位的重要信息,造成整体算法漏判可能性提高,准确率仅为 0.6812;在基于 HOG+CNN 的模型中,将图像分为眼睛和嘴巴区域,再输入到网络中进行卷积,提取特征进行疲劳判断,但由于受到多余冗杂信息干扰,且未考虑前后状态之间的联系,准确率为仅为 82.86;本文提出的疲劳检测算法相比于以上算法具有更高的准确率,准确率达到 94.24%。因此, 基于面部多特征使用与前后驾驶状态有关的算法检测可以实现较高的准确率。
2.4 网络结构消融实验分析
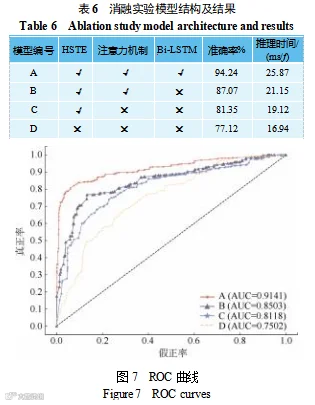
由表 6 和图 8 可知:当去除 HSTE、注意力机制与 Bi-LSTM 后,模型 D 由 LSTM 和 Softmax 分类器构成,其仅依赖单层时序建模结构进行疲劳识别,缺乏对多尺度特征与关键帧的建模能力,冗余信息干扰增强,导致准确率降至 77.12%,ROC 曲线面积(AUC)
仅 0.7502,整体识别性能较弱,推理时间为16.94 ms/帧;在仅保留HSTE 模块的模型C中,由于缺乏注意力机制的时序加权,模型在连续帧中难以聚焦关键疲劳动作,AUC值仅为0.8118,准确率为81.35%,推理时间为19.12 ms/f,虽然速度较快,但鲁棒性依然有限;模型B 在模型C 基础上引入了注意力机制,增强了对重要帧段(如连续闭眼、打哈欠等)的响应能力,使AUC值提升至0.8503,准确率也提升至87.07%,但由于仍为单向LSTM,无法感知前后时序间的完整依赖关系,推理延时为21.15 ms/f;完整模型A融合了HSTE、注意力机制与Bi-LSTM 3 个模块,既能实现多尺度疲劳信号建模,又可动态分配帧权重并引入前后文依赖,使模型在时序上下文中实现更充分的疲劳动作理解,最终准确率达到94.24%,AUC 值提升至0.9141,同时推理时间控制在25.87ms/f,满足30FPS实时检测需求,在精度与效率之间取得了良好平衡。该实验充分验证了各模块设计的合理性及其在疲劳检测中的增益作用,检测实际效果如图8 所示。

3 结论
1) 针对现有视觉疲劳检测方法在智轨场景下适配性不足的问题,本文提出将眼动、嘴部和头部姿态面部特征用于疲劳检测,并针对智轨场景提出了纵向头部巡视行为频率指标用于分心检测。实验结果表明,在模拟智轨驾驶场景下,本文算法均能保持 90%以上的准确率,较单一眼动特征方法提升了 24.7%。这说明多特征协同提取与多尺度融合有效提高了模型在智轨场景的适应性。
2) 为克服传统时序分类模型对关键疲劳动作响应滞后、时间依赖建模不充分的缺陷,本文在 Bi-LSTM基础上引入时间注意力机制,实现了对闭眼、打哈欠等高价值帧的自动加权。与基于眼部状态检测的模型相比,本文模型的 F1-Score 分别由 0.683 5 和 0.832 4提升至 0.902 7,显著降低了误检与漏检率。进一步的消融实验表明,TAM 与Bi-LSTM 联合使用可在保持实时性的同时增强长短时依赖捕捉能力,改善了现有方法时间特征依赖建模不充分的问题。
消息由中国城市轨道交通网CCRM整理编辑,文章来自都市快轨交通,涉及版权请联系删除,如有转载请标明出处)

