

大数据简介
什么是大数据?
大数据(big data)是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
什么是大数据引擎?
大数据引擎是指对大数据进行收集、存储、计算、挖掘和管理,并通过深度学习技术和数据建模技术,使数据具有“智能”。
大数据引擎发展史
第一代:01 Mapreduce
第二代:02 Tez
第三代:03 spark
第四代:04 Flink
大数据计算引擎详解
1、MapReduce
MapReduce是hadoop的核心组件之一。
MapReduce是分布式计算框架,主要进行分批处理任务。
MapReduce是一种编程模型,是一种方法,抽象理论。
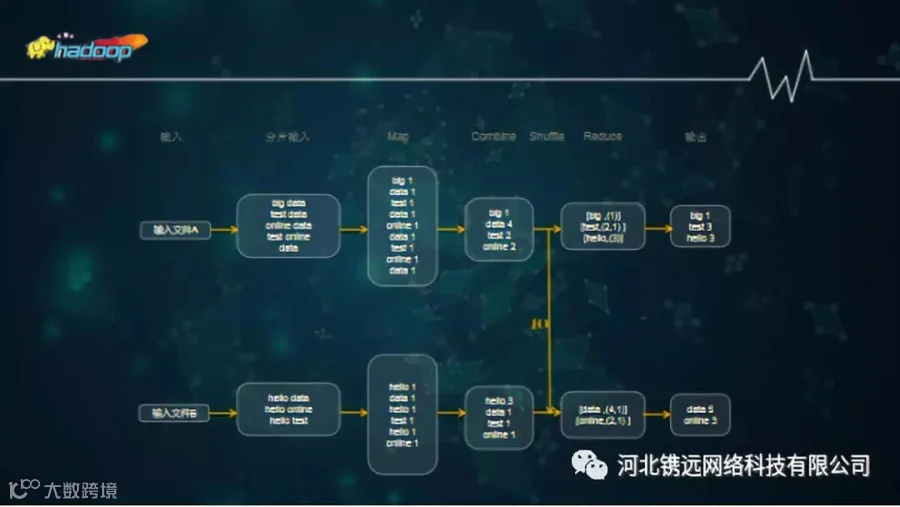
简单地实现一些接口,就可以完成一个分布式程序,而且这个分布式程序还可以分布到大量廉价的PC机器运行。
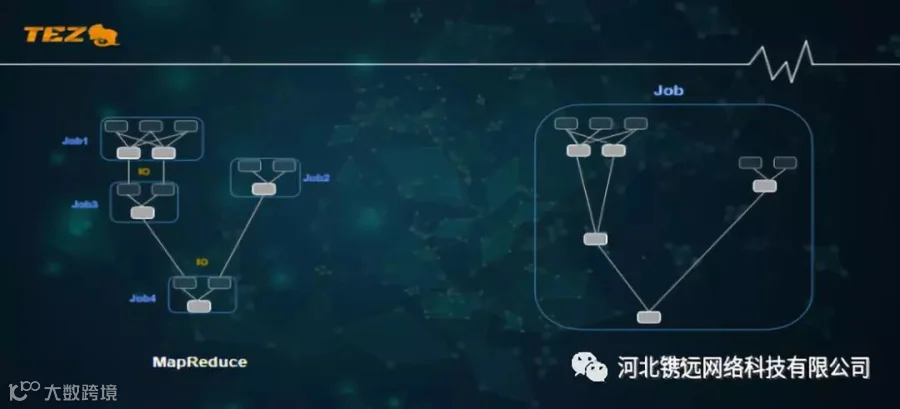
2、Tez
Tez是基于Hadoop Yarn之上的DAG计算框架。它把Map/Reduce过程拆分成若干个子过程,同时可以把多个Map/Reduce任务组合成一个较大的DAG任务,减少了Map/Reduce之间的文件存储。减少任务的运行时间。
3、Spark
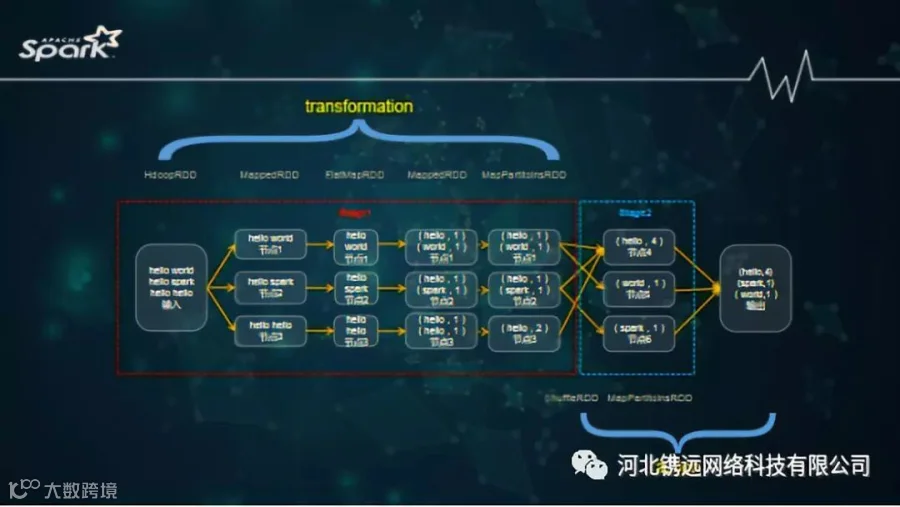
Spark on Yarn模式、Spark on Mesoes模式、Spark Standalone模式、本地local运行模式
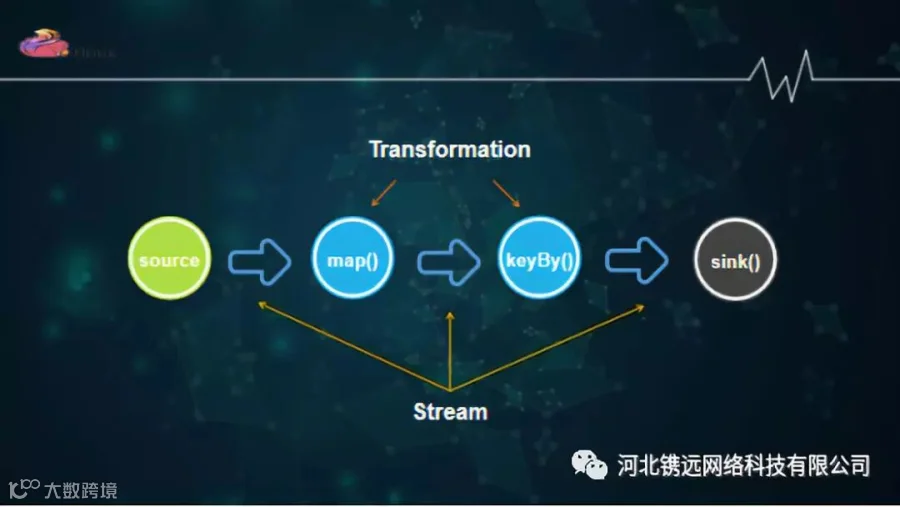
4、Flink
Apache Flink是一个分布式的大数据处理引擎,可以对有限数据流和无线数据流进行有状态的计算。可以部署在各种集群环境,可以对各种大小规模的数据进行快速计算。
总结

Hadoop MR主要针对大数据量的批处理任务,Spark针对数据量稍小点(小于1T)的批处理任务,处理速度相对MR快。
接下来就是以 Spark 为代表的第三代的计算引擎。第三代计算引擎的特点主要是 Job 内部的 DAG 支持(不跨越 Job),以及强调的实时计算。在这里,很多人也会认为第三代计算引擎也能够很好的运行批处理的 Job。
随着第三代计算引擎的出现,促进了上层应用快速发展,例如各种迭代计算的性能以及对流计算和 SQL 等的支持。
“Flink是一个大数据量处理的统一的引擎”。这个“统一的引擎”包括流处理、批处理、AI、MachineLearning、图计算等等。Flink的诞生就被归在了第四代。这应该主要表现在Flink对流计算的支持,以及更一步的实时性上面。当然 Flink也可以支持 Batch 的任务,以及 DAG 的运算。
大数据技术正飞速地发展着,催生出一代又一代快速便捷的大数据处理引擎,无论是Hadoop、tez,Storm,还是后来的Spark、Flink。
各个框架存在不同差异,适合不同的场景。没有哪一个框架可以完美的支持所有的场景,也就不可能有任何一个框架能完全取代另一个,就像 Spark 没有完全取代 Hadoop,当然 Flink 也不可能取代 Spark。
本文将致力描述 Flink 的原理以及应用。
关于我们:
河北镌远网络科技有限公司(Hebei JYCYBER TechnologyCo.,Ltd.)是一家集人才、技术和经验于一体的,提供全面网络安全解决方案的专业服务商。镌远科技致力于为各行业的网络安全需求提供软件研发和通用解决方案,业务领域主要包括基础服务、咨询业务、产品研发和安全培训四大版块,各版块相互独立又相辅相成,完美阐释了“专业服务、全程服务、延伸服务”的服务体系和“单一业务与长远目标相融合”的服务理念。
关注镌远科技,关注网络安全!
河北分公司:河北镌远网络科技有限公司
地址:河北省邯郸市丛台区中华北大街193号慧谷大厦14层
总公司:北京冠程科技有限公司
地址:北京市昌平区科技园区东区产业基地企业墅上区一号楼九单元四层
实训基地:河北省石家庄市电子信息学校冠程科技研究与实训中心


欢迎扫描关注我们,及时了解更多关于网络安全相关知识