本文结合JDK1.7和JDK1.8的区别,深入探讨HashMap的结构实现和功能原理。

这里假设有两个线程同时执行了put操作并引发了rehash,执行了transfer方法,并假设线程一进入transfer方法并执行完next = e.next后,因为线程调度所分配时间片用完而“暂停”,此时线程二完成了transfer方法的执行。此时状态如下:
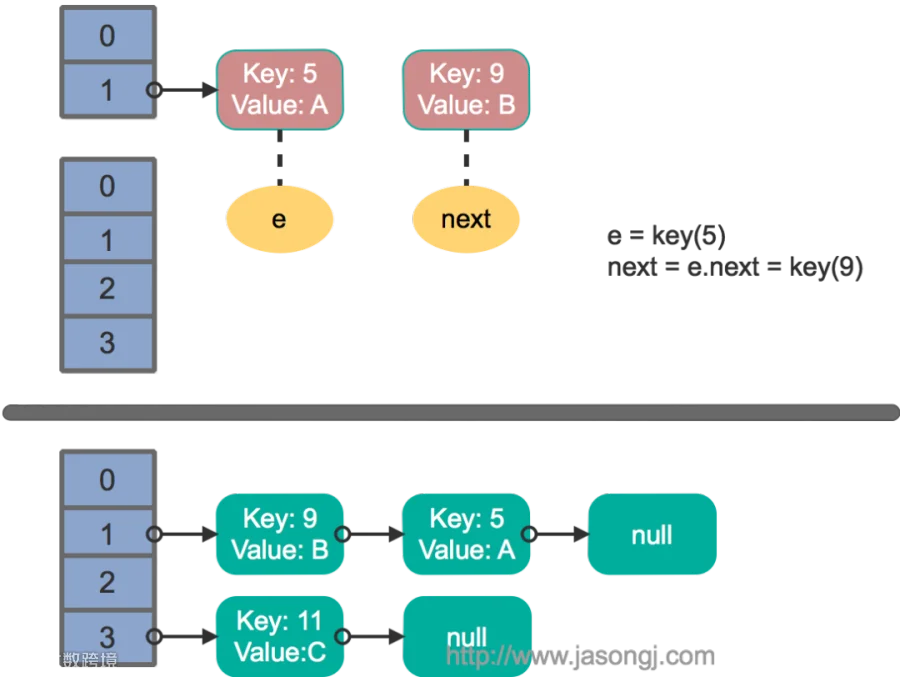
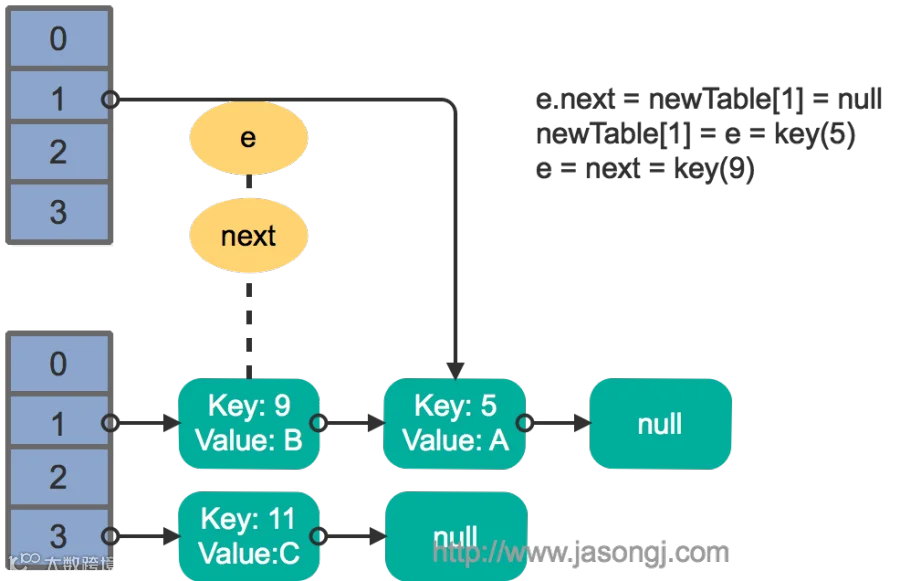
接着线程1被唤醒,继续执行第一轮循环的剩余部分:
e.next = newTable[1] = null
newTable[1] = e = key(5)
e = next = key(9)
结果如下图所示:
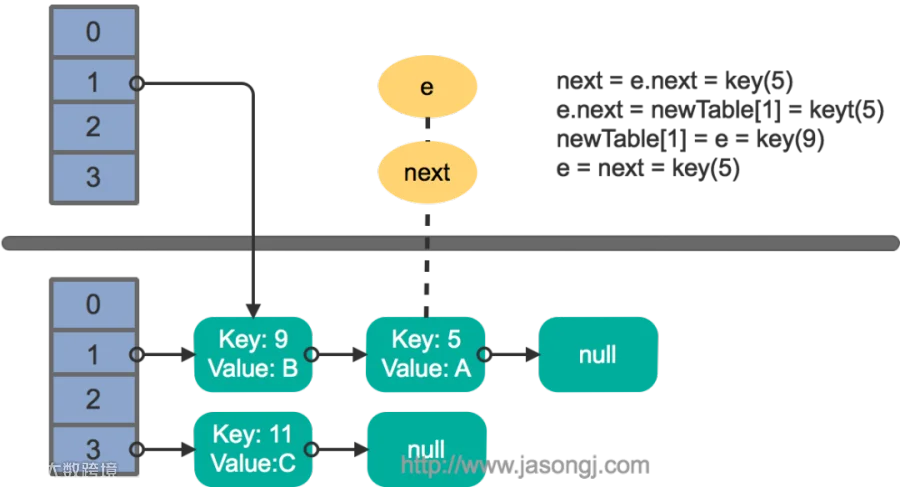
接着执行下一轮循环,结果状态图如下所示:
继续下一轮循环,结果状态图如下所示:
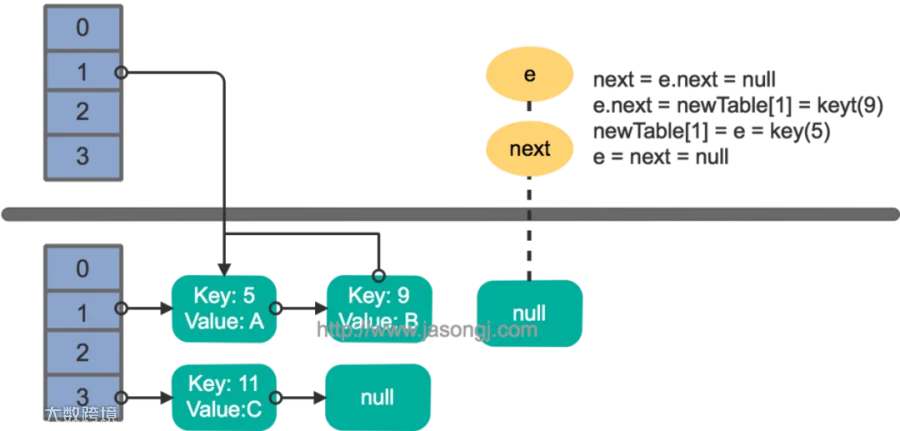
此时循环链表形成,并且key(11)无法加入到线程1的新数组。在下一次访问该链表时会出现死循环。
在使用迭代器的过程中如果HashMap被修改,那ConcurrentModificationException将被抛出,也即Fast-fail策略。
当HashMap的iterator()方法被调用时,会构造并返回一个新的EntryIterator对象,并将EntryIterator的expectedModCount设置为HashMap的modCount(该变量记录了HashMap被修改的次数)。
HashIterator() {
expectedModCount = modCount;
if (size > 0) { // advance to first entry
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null)
;
}
}
在通过该Iterator的next方法访问下一个Entry时,
它会先检查自己expectedModCount与HashMap的modCount是否相等,如果不相等,说明HashMap被修改,直接抛出ConcurrentModificationException。该Iterator的remove方法也会做类似的检查。
该异常的抛出意在提醒用户及早意识到线程安全问题。
单线程条件下,为避免出现ConcurrentModificationException,需要保证只通过HashMap本身或者只通过Iterator去修改数据,不能在Iterator使用结束之前使用HashMap本身的方法修改数据。
因通过Iterator删除数据时,HashMap的modCount和Iterator expectedModCount都会自增,不影响二者的相等性。如果是增加数据,只能通过HashMap本身的方法完成,此时如果要继续遍历数据,需要重新调用iterator()方法从而重新构造出一个新的Iterator,使得新Iterator的expectedModCount与更新后的HashMap的modCount相等。
多线程条件下,可使用Collections.synchronizedMap方法构造出一个同步Map,或者直接使用线程安全的ConcurrentHashMap。
注:文章来源于网络。
如有侵权,请于后台联系,做删除处理,感谢您的支持。
网络安全科普|5G三大安全风险与对策
网络安全科普 | 8种常见的OT/工业防火墙错误
网络安全科普|2021年大数据安全的7个主要变化

