

在 2022 年全球云原生开源峰会(GCOS)上,Apache 软件基金会成员、Apache 孵化器 PMC 成员和 Apache DolphinScheduler PMC 郭炜(William)分享了他对 Apache 数据工程项目提高 DataOps 效率的看法。作为一名开源布道者,郭炜还创立了 ClickHouse 中国用户组,在中国传播开源文化。

关于郭炜:
阿帕奇软件基金会成员
Apache 孵化器 PMC 成员
Apache DolphinScheduler PMC
ClickHouse中国用户群创始人
中国软件行业协会智能应用服务分会副理事长
中国前 33 名开源人士(来自 SegmentFault)
TGO 董事会成员(InfoQ 全球 CTO 社区)
以下为郭炜在 GCOS 2022 上的演讲摘要,供大家参考。
__________________________________________________________
今天,我们发现有太多新的数据技术,我们很难一一了解。那么数据领域在发生着怎样的变化?我们如何应对如此多的技术?我认为有几个新的概念也许可以解决这类问题。

数据网络结构(Data Fabric)
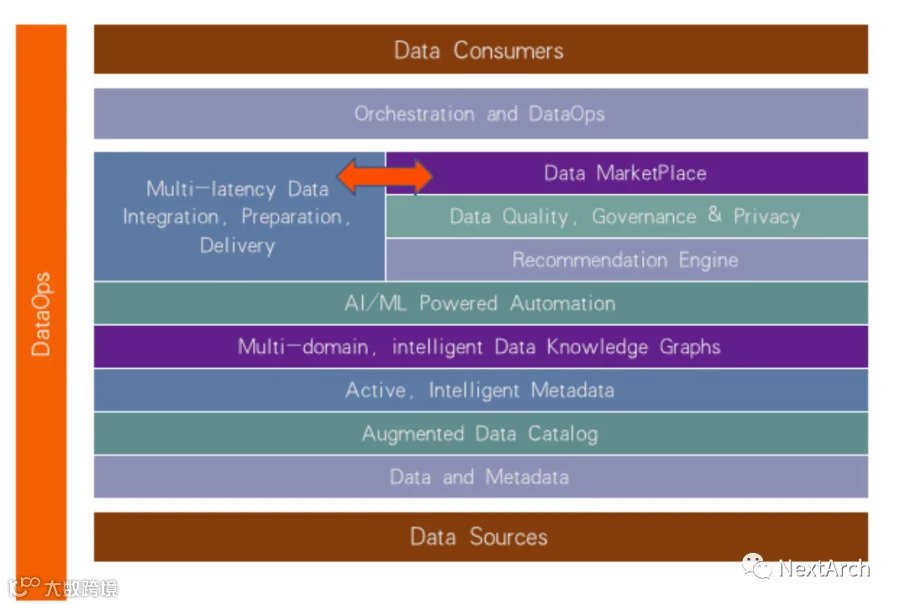
其中一个概念被称为 Data Fabric,这个概念由 IBM 提出,被 Gartner 传播开来。在我看来,数据网络结构的核心是通过主动、智能的元数据来组织你的整个数据。在此之上,你可以构建自己的智能数据知识图谱,并使用机器学习算法来建立自己的数据治理和数据市场。
而在所有的流程下,你都会遇到 DataOps。后面我会介绍什么是DataOps。
DataMesh
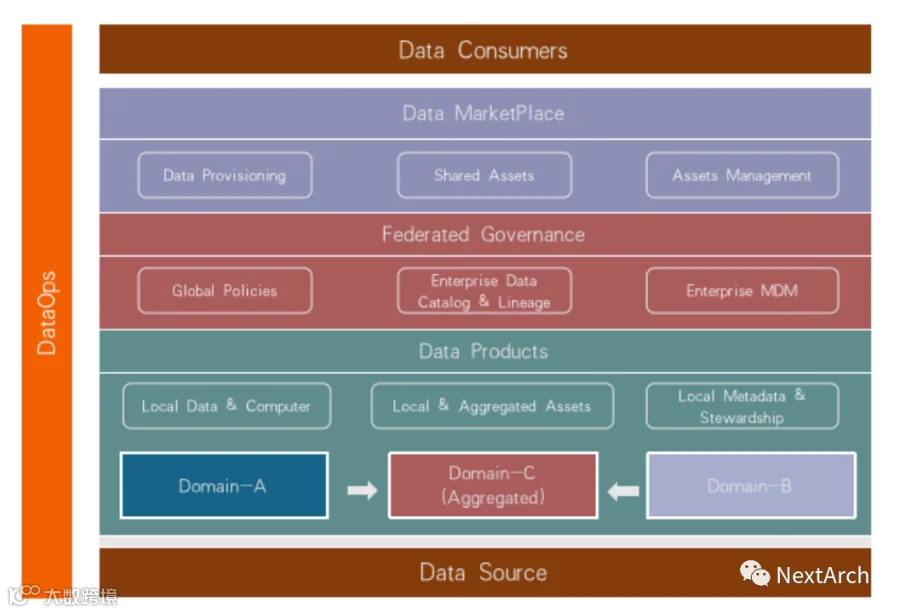
另一个概念是 DataMesh。它旨在创建一些专注于人员和流程的 API,来构建数据产品。使用 DataMesh 时,你不需要知道数据存储在哪里。
你只需要专注于构建自己的分布式治理 API,并用基于数据域的 API 来分散数据所有权。这个概念注重人和流程。
现代数据栈(云原生数据栈)
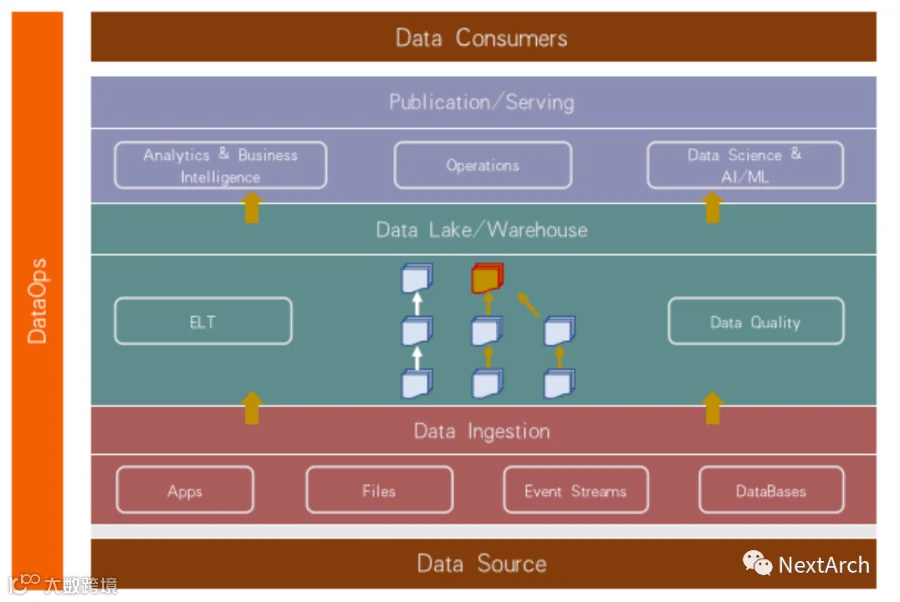
我注意到很多人都在使用现代数据栈。如上图所示,在过去,我们通常使用 ETL 技术,即在处理多数据源时,我们提取数据、转换然后加载到仓库中。
现在情况不同了。现在我们只需要将数据提取并加载到湖中,然后对数据湖或数据仓库进行转换,在这个过程中我们可以控制数据质量,在此之上构建我们的智能,以及一些为科学家或人工智能机器学习设计的操作。
那么什么是 DataOps 呢?在我看来,DataOps 是将数据源与数据目标连接起来的关键技术。它涵盖了数据编排、数据集成、数据转换和数据治理整个过程。
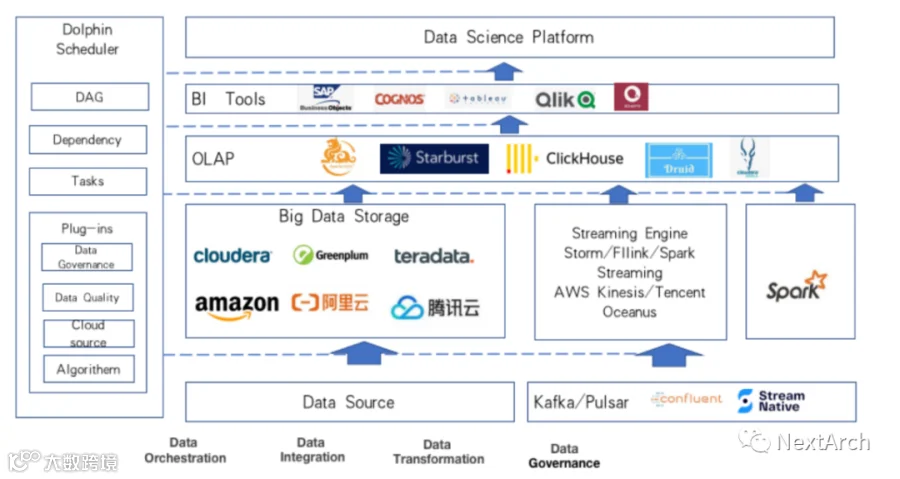
上图为大数据企业的布局。当处理数据源时,你可以将数据加载到 Kafka 或 Pulsar 等大数据存储产品中,再使用 Storm/Flink/Spark Streaming AWS Kinesis/Tencent Oceanus 等流引擎将它们加载到 OLAP 引擎,例如 Crystal、ClickHouse、Druid、impala 等。之后,你可以使用 BI 工具,并将它们加载到数据科学家平台。
今天我将介绍两个关于 DataOps 的 Apache 项目。一个是 Apache DolphinScheduler,用于数据编排,另一个是 Apache SeaTunnel,用于在不同数据库之间进行数据提取和同步。
1 Apache DolphinScheduler
首先,我想介绍一下 Apache DolphinScheduler。它是一个大数据工作流编排平台,在 K8S 或你的本地机器上具有强大的 DAG 接口。它致力于解决数据管道中复杂的任务依赖性。
这是一个非常易于使用的平台,只需要拖拉拽即可创建新的工作流程并维护运行的作业,而无需编码。
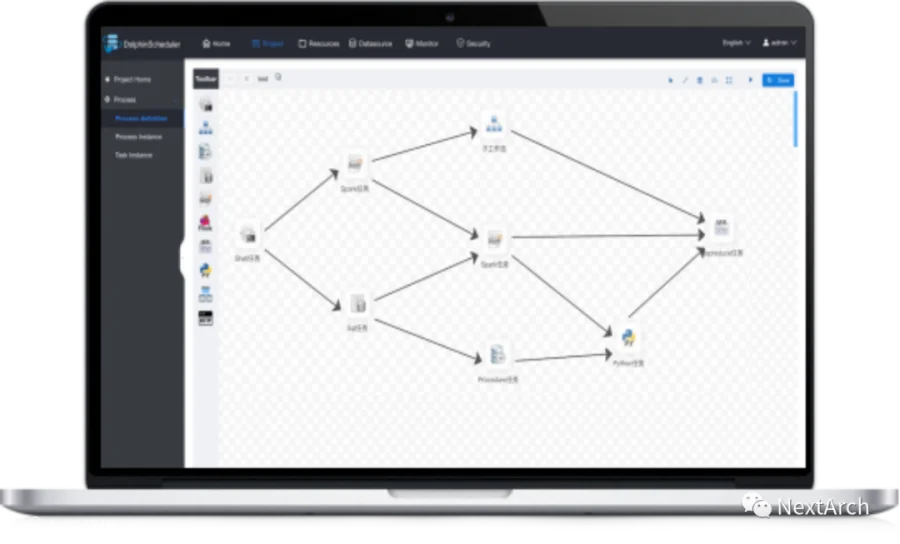
Apache DolphinScheduler 采用多 master 和多 worker 的架构设计,非常易于扩展且极其稳定,云原生的特性也支持多云、混合云和 K8s。用 Python 进行 DAG,MLOPS 编排也没有问题。我稍后会介绍这部分内容。
特性
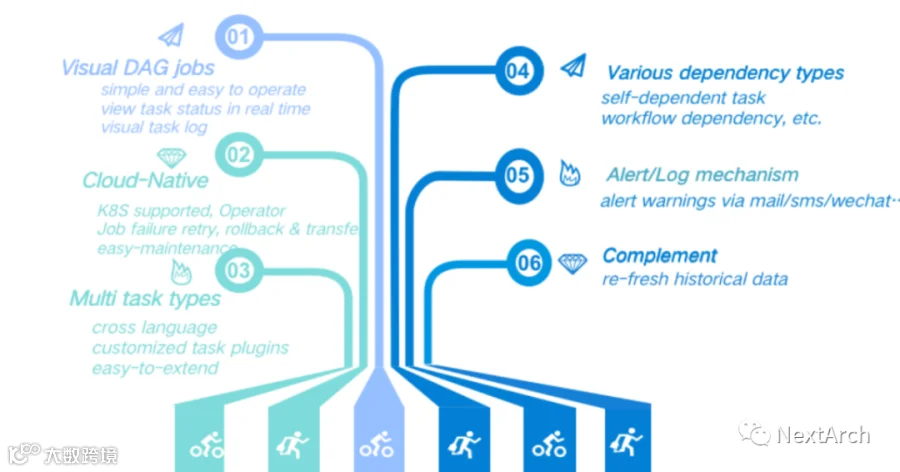
Apache Dolphinscheduler 的许多功能使得轻松构建任务工作流成为可能,例如可视化 DAG 作业支持简单易用的操作以及实时查看您的任务状态。它还是云原生的,支持多任务类型和丰富的依赖类型,并有多种日志和警报机制可供选择,补充功能也让用户可以刷新历史数据。
工作流管理:可视化的拖放式工作流配置
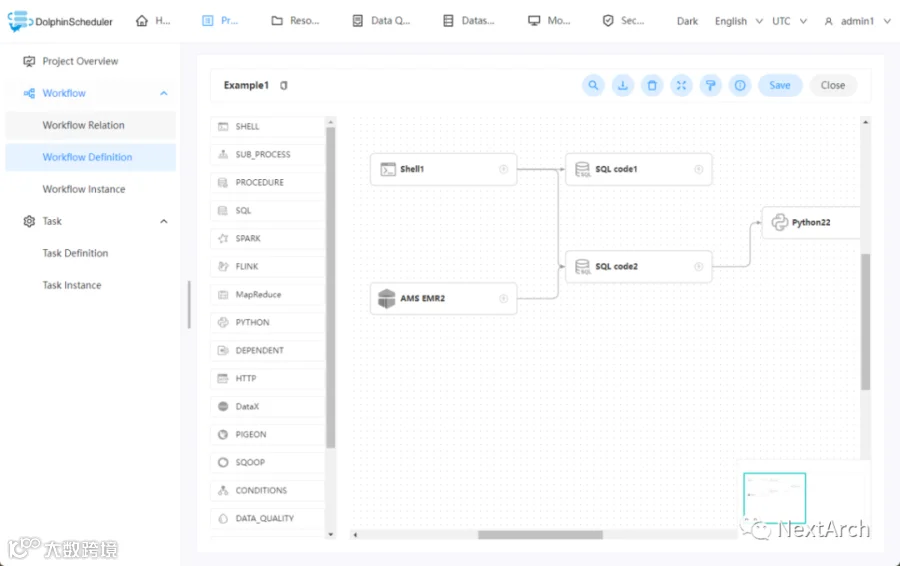
这是 Apache DolphinScheduler 的界面。如图所示,你可以通过拖拉拽创建自己的 DAG 图。在 DAG 图上,你可以拖动并连接有着各自依赖关系的 Shell 程序、Sparks 程序或 EMR 程序等,并让它自动在 K8s 和/或你的机器上运行。
目前,Apache DolphinScheduler 支持各种任务类型,如 Shell、MR、Spark、SQL(MySQL、PostgreSQL、Hive、Spark SQL)、Python、Flink、EMR 等。它还配备了一些逻辑任务,如子进程,这意味着你可以将 Shell、EMR 和 Spark 程序结合起来创建 DAG,此 DAG 将成为另一个更大的 DAG 进程的子进程。
Apache DolphinScheduler 还支持依赖任务。也就是说你可以依赖其他工作流任务,并支持切换。如果你想切换到一个新的程序,通过这种任务和图表很容易创建数据流程。总之,创建和设计整个工作流程非常简单。
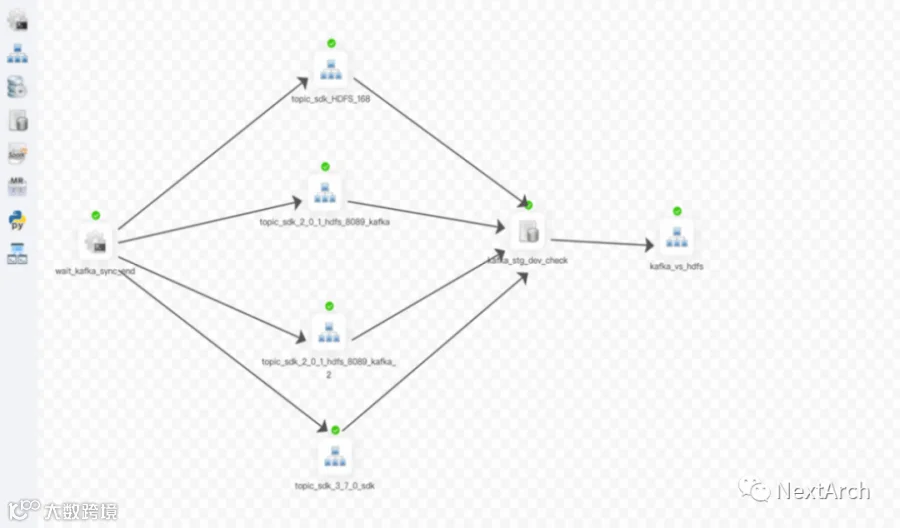
运行工作流程可视化
支持重新运行,重试任务和检查任务
监控工作流运行状态是小菜一碟。在下图中,可以看到工作流程的详细信息,包括成功或失败状态、调度时间、开始时间、完成时间、日志等。监控日志时,只需要登录 Apache DolphinScheduler 而无需登录 Spark 或 EMR 服务器。
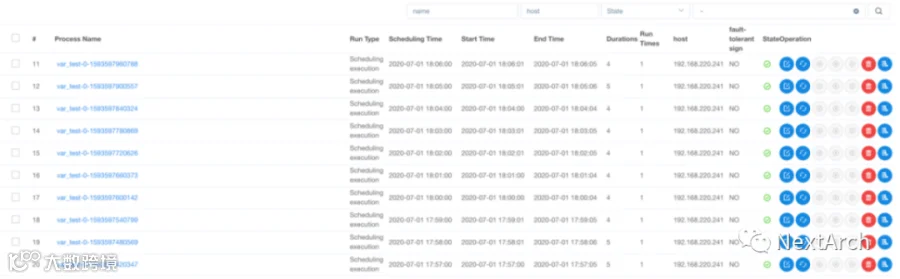

支持重新运行和重试任务和检查任务
任务管理:1、2、3级监控日志
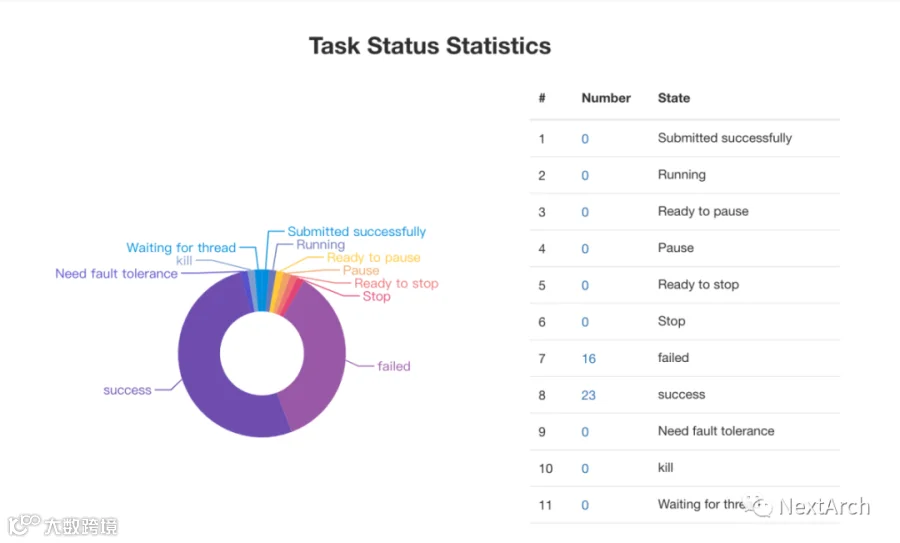 任务状态数据统计
任务状态数据统计
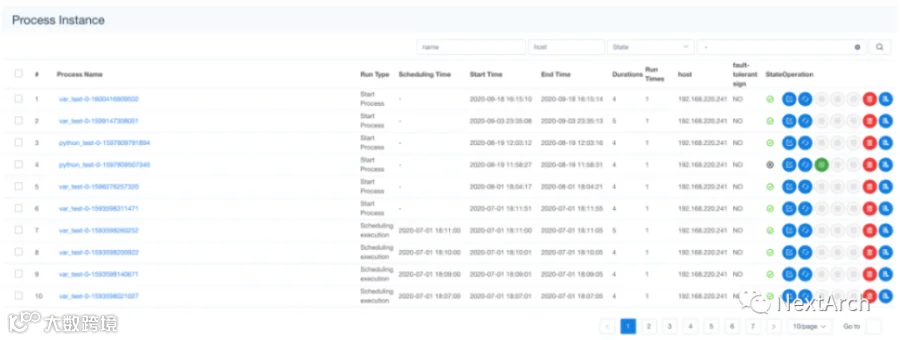
流程实例状态

跟踪任务执行状态
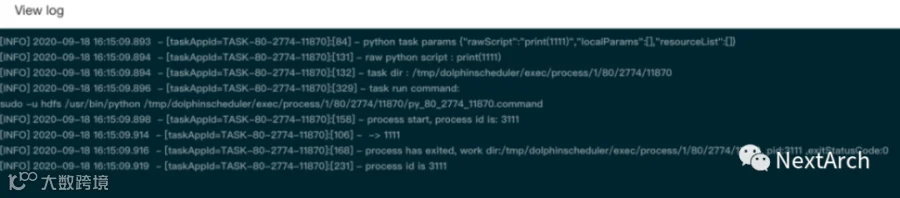
任务执行在线日志
新的功能
1. MLOps 编排
以上是 Apache DolphinScheduler 的基本功能。我们在其中添加了一些新功能以满足用户需求,其中之一就是 MLOps 编排。

我们的程序中有很多新的机器学习包,例如 Pytorch、SageMaker、MLDB、MLflow 或 Jupyter。在编写机器学习算法时,我们会发现很难将它们结合起来使用。比如我想创建我的数据准备流程,我会把数据放到 Jupyter 中,但后面还需要用到 SageMaker。那我怎么才能把它们结合起来使用呢?我可以用 Apache DolphinScheduler 创建并连接所有进程。Apache DolphinScheduler 可以把从 Spark 准备数据,Jupyter 处理数据,SageMaker 在线训练模型,验证或重试数据返回数据准备的整个流程串联起来,一站式维护工作流任务,而无需在不同平台之间进行编码。
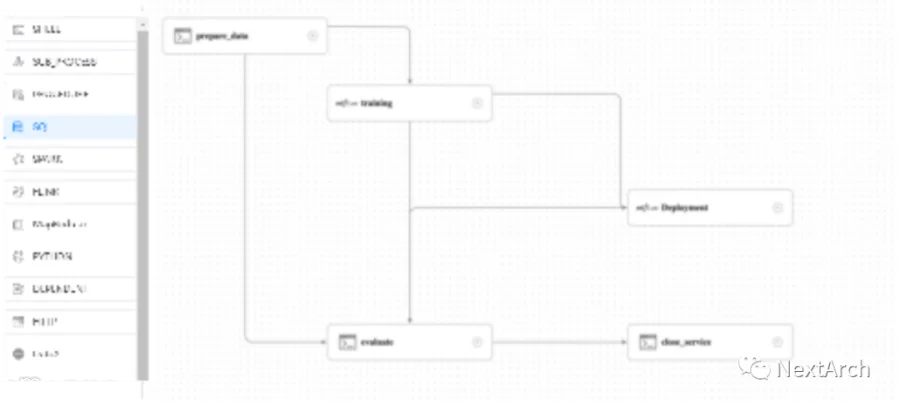
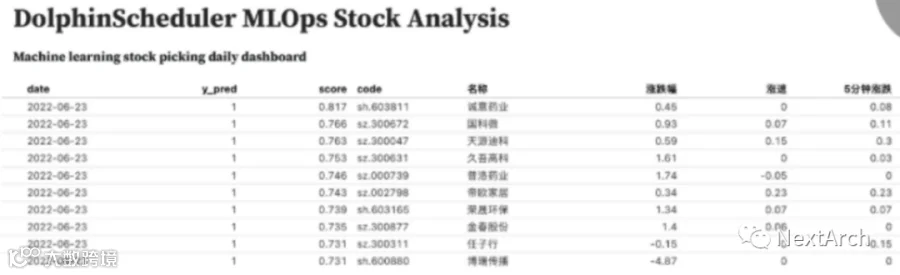
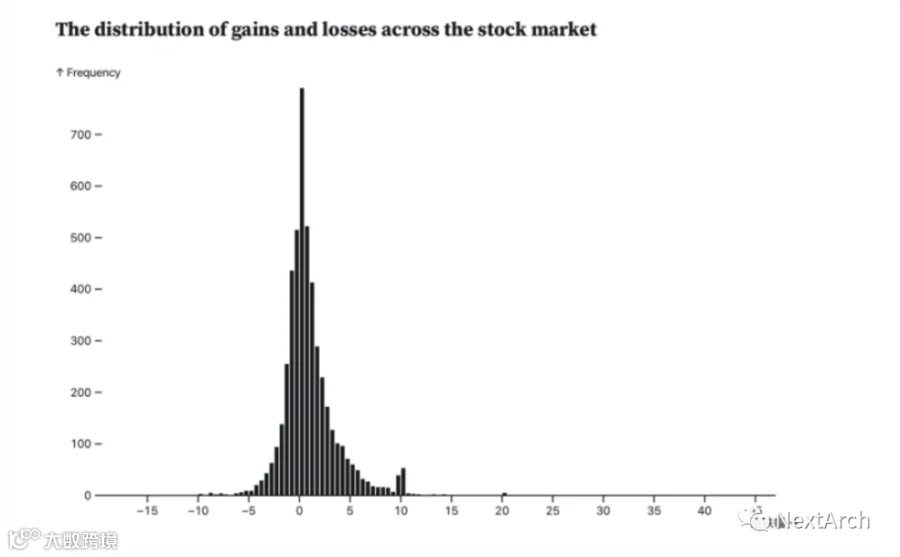
这是 DolphinScheduler 的 MLOps 示例。如图所示,我们搭建了一个选股系统,让 DolphinScheduler 每天用机器学习从中国股市 4800 多只股票中选出排名前 10 的股票,并用 Observable 实时监控选股效果。
你可以通过拖拉拽来准备数据,在 MLflow 上训练数据后部署模型,通过 Shell 评估数据,就可以得到训练结果。
它让数据分析师和科学家可以轻松地构建和重用分析流程。
我注意到一些开发人员希望通过 Python 创建 DAG,而不仅仅是通过拖放来创建进程。
所以我们开发了一个名为 PyDolphinScheduler 的新功能。这个功能让你可以使用 Python 程序(左)创建如右图所示的 DAG 图。
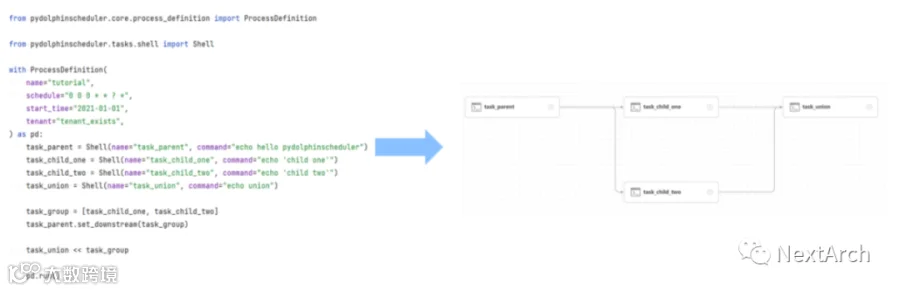
之后你可以监控工作流的进程并在 DAG 上运行任务,进行版本控制、代码审查、CI/CD 和其他操作也很简单。
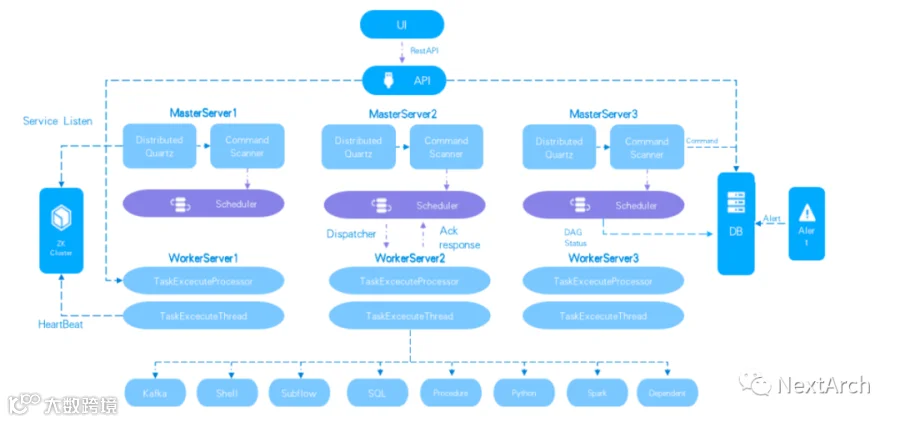
新的云原生架构也是 Apache DolphinScheduler 的新特性之一,多 Master 和多 Worker 的设计使得它可以支持 K8s。
最近,我们发布了一个 K8s 算子来优化 K8s 上运行的工作流,让 DolphinScheduler 更方便地组织整个数据流程。
用户案例:
Apache DolphinScheduler 已经在IBM、腾讯、沃尔玛、麦当劳等多家企业的生产环境中使用。

社区发展迅速:
Apache DolphinScheduler 社区发展得越来越快,有超过 370 名贡献者,并欢迎更多人加入。
想要了解更多关于这个智能、简单和协作式的工作流调度项目,可以查看 Apache 官方网站 https://dolphinscheduler.apache.org/,或加入 Slack 频道 https://join.slack.com/t/asf-海豚调度程序/shared_invite/zt-1cmrxsio1-nJHxRJa44jfkrNL_Nsy9Qg。
2 Apache SeaTunnel(Incubating)
另一个 Apache 数据工程项目是 Apache SeaTunnel,目前正在 ASF 孵化。
当我们在处理数据时经常会遇到这样的问题,我们应该如何从把某个数据源的数据提取到目标数据源。
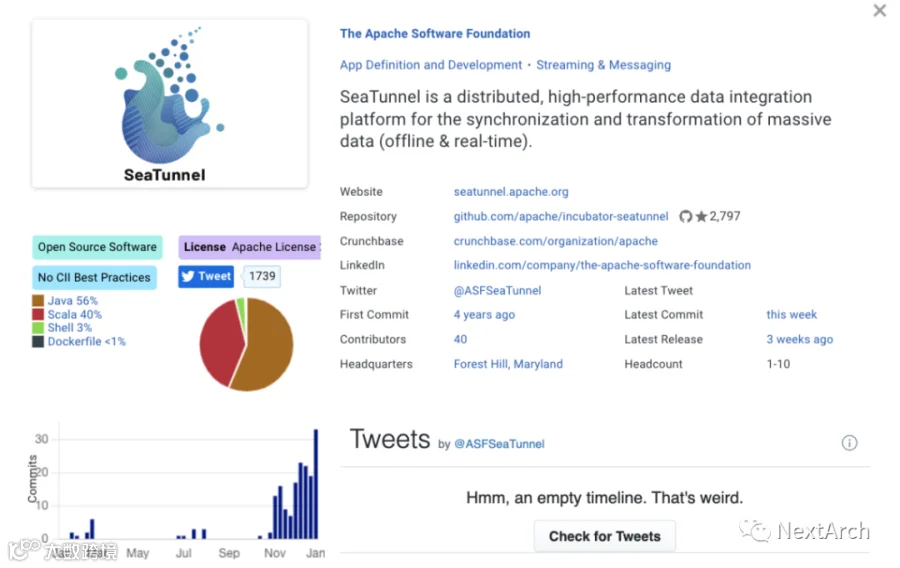
在过去,我们可能会使用 Sqoop 来解决这个问题,但这个项目在去年就“退役”了。对于新世界来说,云原生数据同步项目SeaTunnel 也许是一个新的选择。
这是一个分布式、高性能的数据集成平台,用于海量数据的同步和转换。你可以用它从任何数据库加载数据并发送到其他数据库。
这听起来并不容易。例如,如果你用的是 ClickHouse,会发现查询速度太快,无法将数据 sink 到 ClickHouse。如果你想在 ClickHouse 中插入大量数据,更实惠引发大量报错。
SeaTunnel 通过创建 ClickHouse 文件并将数据文件复制到 ClickHouse 服务器来解决这个问题。
这种方法的性能比向 ClickHouse 插入数据快 10 倍。现在 SeaTunnel 支持丰富的数据库来同步和整合数据到其他数据目标。虽然你也可以选择用 Spark 或 Flink 同步、计算数据,但必须编写数据库之间的连接器。SeaTunnel 现在支持超过 40 种连接器,完美地避免了这个过程。
SeaTunnel 易于使用,免去你学习 Sqoop 或其他语言的麻烦。
用户案例:
SeaTunnel 也受到很多用户的青睐,比如腾讯、OPPO、Shopee 等。

使用 SeaTunnel 的场景主要有 2 个。一是海量数据同步。比如唯品会有很多数据源,包括 Kudu、Hudi、ClickHouse、Presto、Kylin 等,并且有自己的内部数据分析平台。SeaTunnel 被用来同步这些种类繁多的数据源。
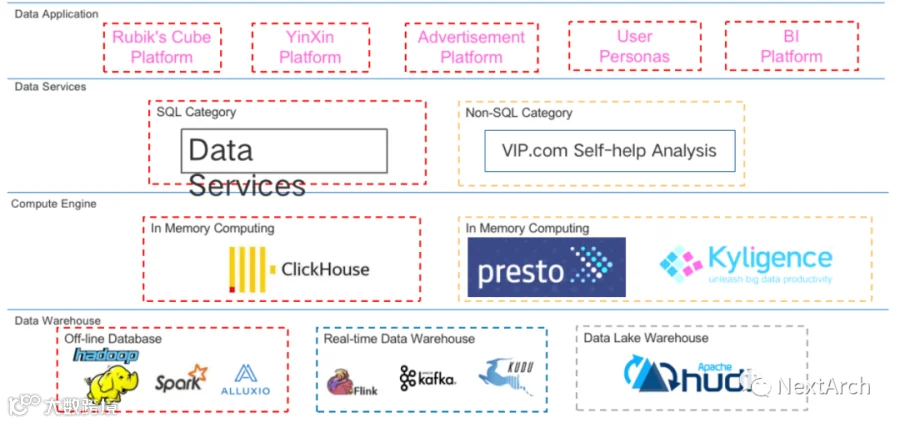
SeaTunnel 可以轻松处理多个数据库或数据源。
如果你对这款高性能数据同步平台感兴趣,欢迎加入 Slack 频道或登录 Apache 网站 SeaTunnel.Apache.org 了解更多信息。
新数据社区,新数据世界!
目前,我们发现除了数据工程师、数据科学家、数据架构师或 ELT 开发人员之外,越来越多的人正在使用数据。每家公司都在创建自己的数据社区,甚至销售分析师、客户支持、董事会成员或财务分析师也在广泛使用数据。我认为 DataOps 将让每个人在未来都可以更轻松地使用数据。最后一句话,我相信未来我们会创造一个新的数据社区和一个新的数据世界。
邮箱:guowei@Apache.org
领英ID:WilliamK2000
NextArch基金会(下一代架构基金会)成立于2021年11月,隶属于Linux Foundation,是非营利性组织。 NextArch基金会(下一代架构基金会)通过开放中立的治理模式,构建适合企业发展的下一代架构的开源生态,促进技术创新及商业增长,并利用项目协作、最佳实践、行业交流等方式来帮助企业数字化转型。点击下方名片进行关注NextArch基金会公众号。
点亮「在看」为开源传播助力 👇