

传统意义上的AI模型,主要分为判别式模型(Discriminative Models)和生成式模型(Generative Models)。判别式模型主要用于解决回归或分类任务,而生成式模型是一类能学习和模仿数据分布的模型。
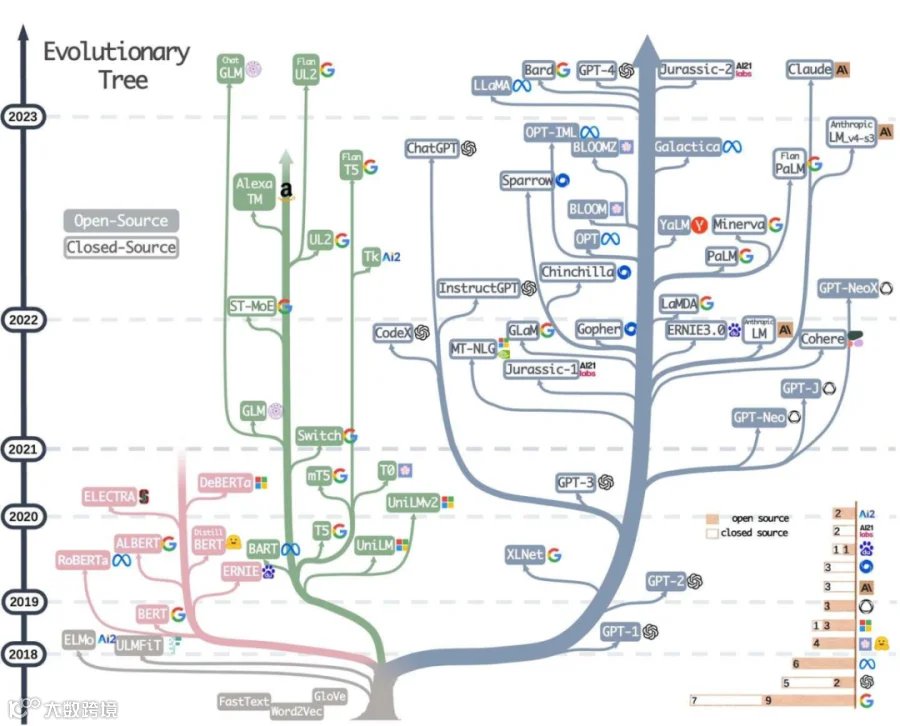
图1:大模型的发展历史
生成式AI(AIGC)将成为未来的通用型AI(AGI)的基石,而判别式AI在视觉识别等分割的AI具体任务中也不可或缺。不同的算法和模型是各家AI最核心的设计,当前市面上的各类AI,基本均以大模型为基础。目前,大模型以Transformer架构为主,Transformer架构是推动大模型崛起的关键创新之一,它革新了序列到序列模型的设计理念。Transformer 架构很难实现大一统,和其他架构会持续演进并共存,形成多元化的技术生态。例如,Transformer架构虽然是当前主流,但新兴架构(如Mamba、RWKV、RetNet)还在不断刷新计算效率。在模型架构本身进行创新需要初创企业拥有强大的计算机科研实力,也要求所在区位具备浓厚的计算机软件业氛围和创新土壤。
除了参数规模巨大,大模型训练所需的数据量往往也极其庞大,通常以PB(拍字节,即1024TB)级别计,包含成百上千亿的词条和数据。这对数据的存储、管理和处理能力提出了极高的要求。这些数据来源广泛,涵盖互联网文本、社交媒体、百科全书、学术论文、新闻报道、书籍、音频、视频、图像等多模态内容。以自然语言处理领域为例,训练数据通常会包含了各类在线百科、书籍语料、CC-News、Stack Exchange等公开可用的大型文本数据集,以及通过网络爬虫抓取的海量网页内容。
数据标注(Labeling)是AI模型训练中至关重要的前置步骤,因为它为算法提供了学习的基础。国内数据标注厂商,广义也被叫做基础数据服务商,通常需要完成数据集结构/流程设计、数据处理、数据质检等工作,为下游客户提供训练数据集、定制化服务。

图2:数据标注历史演变
作为AI底层服务,数据标注最本质的要求就是为下游客户降本增效。而技术是降本增效的最优解决路径,持续迭代技术能力的企业将有机会脱颖而出。数据标注需要企业懂得行业know-how,能够根据客户需求,快速找到并利用与场景最为贴合的数据和人才资源。另外,数据标注仍具有飞轮效应:在技术和场景资源能力双重驱动下,数据处理能力越强,大模型标注经验越丰富,落地案例越来越多,数据处理的可扩展性和灵活性也越高。目前全球领先的大模型数据标注企业主要分布在北美,突出的特点是技术驱动导向,数据标注服务供给能力和质量较高,如Scale AI估值达130亿美金。
OpenAI在2020年指出,大模型也符合标度律。也就是说,随着模型大小、数据集大小和用于训练的计算浮点数的增加,模型的性能会提高。为了获得最佳性能,所有三个因素必须同时放大。当然,不受其他两个因素的制约时,模型性能与每个单独的因素也能观察到幂律关系。因此,不断扩大模型参数的数量、数据集大小和浮点数精度,模型往往就能表现得更好。因此除了模型本身参数规模,数据集规模对存储能力和传输速度提出要求,浮点数精度对计算芯片提出要求。
AI训练核心是大规模的数组计算。人们最早进行AI模型训练主要依靠的是中央处理器(CPU),这是因为CPU是通用计算的核心,然而,CPU的串行处理架构在面对大规模并行计算需求时显得力不从心。图形处理器(GPU)因其并行计算能力和高内存带宽的优势,开始被用于AI训练。英伟达(NVIDIA)的GPU在这一领域取得了主导地位,其CUDA架构允许科学家和工程师编写并行代码,直接利用GPU的计算能力。CUDA包含了一套完整的生态系统,包括硬件抽象层、编程接口、编译器工具链和一系列高性能的数学库。因此,开发者可以利用CUDA平台直接编写程序在GPU上运算,这些程序会被编译成可以在NVIDIA GPU上运行的二进制代码,从而直接调用GPU进行高效计算。随着AI计算需求的进一步提升,专用的人工智能处理器应运而生,例如谷歌的张量处理单元(TPU)。在整个海量计算和数据传递过程中,TPU均不需要内存请求。在处理特定的AI任务时,它的性能和能效远超CPU和GPU。
虽然GPU和TPU等可以通过软件更新来优化驱动程序和提升性能,但其基本的硬件架构不会改变,其计算核心、内存布局和互连结构在制造完成后是固定不变的。为了解决以上痛点,现场可编程门阵列(FPGA)逐渐被用于AI训练和推理。FPGA是一种半定制电路,与GPU等处理器相比,其核心区别在于FPGA允许用户在硬件级别上编程和重新配置电路以适应特定的计算任务。
近年来,随着AI模型的规模和复杂度不断增大,对更高计算性能和更低能耗的需求推动了AI处理器的持续创新。新兴的处理器设计,如神经形态计算芯片、光子计算芯片,以及量子计算,都在探索AI计算的未来可能性。
1. 芯片产业链
无论是存储芯片、CPU/GPU/TPU还是FPGA,均需要尖端制程的光刻技术。制程越先进,数值越小,表明晶体管的尺寸越小,能够集成更多的晶体管在同一芯片上,从而提高芯片的性能,降低功耗,减少发热,并可能降低成本。目前,DRAM存储芯片的先进工艺位于18-15nm之间,而逻辑芯片(CPU、GPU等)最先进的工艺均已处在3nm制程的水准并向2nm突破,谷歌的TPU使用的制程也已达到7nm的水准。目前国产光刻机依然仅在28nm制程及以下具备较优的良率,14nm有关技术仍由中芯国际、华虹半导体进行探索,尚未成熟。FPGA领域,行业的国际龙头企业Xilinx已推出采用7nm FinFET工艺的FPGA产品,而国内FPGA量产产品中最为先进的仅采用了28nm的工艺制程,主流产品仍采用55nm的工艺制程。
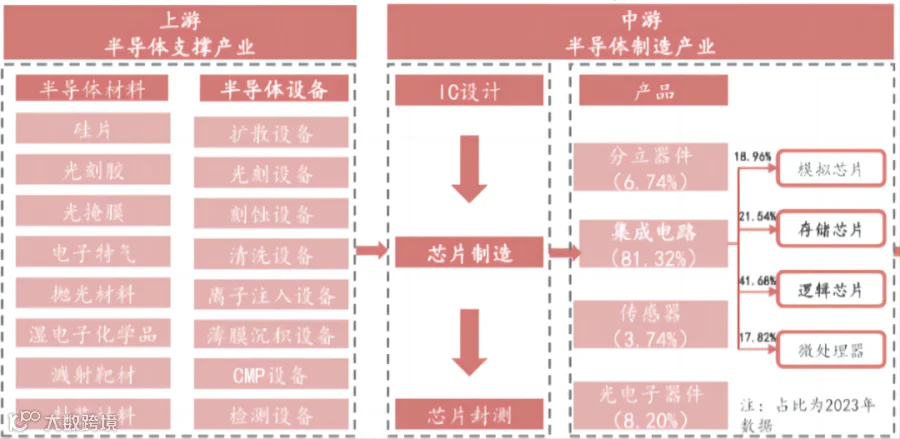
图3:半导体上游产业链
因此,以逻辑芯片为代表的半导体产业可能成为制约AI行业的关键因素。当前我国半导体设备总体国产化率不足20%,自给率仍然处于较低水平,未来成长空间大。另一方面,科技制裁倒逼国产化加速。自2018年以来,美国先后对我国半导体行业实施多次限制,目前来看主要针对先进工艺,比如16/14nm及以下的FinFet/GAA逻辑器件,18nm以下的DRAM器件和128L以上的Flash器件。海外先进制程设备的禁运为国产半导体设备厂商让出生态位,半导体设备国产化率势必加速。芯片生产的模块工艺是由不同的单项工艺组合而来,单项工艺包括光刻、涂胶显影、薄膜沉积、刻蚀、离子注入、CMP、清洗等,其中薄膜沉积、刻蚀和光刻设备是价值量最大的三类设备。从全球市场份额来看,薄膜沉积设备行业呈现高度垄断的竞争局面,全球市场基本由应用材料AMAT、ASMI、泛林半导体Lam、东京电子TEL等国际巨头垄断。国内的厂商主要在细分领域进行差异化竞争,产品可以互补,如拓荆科技主要产品为CVD,北方华创的主要产品是PVD,微导nm的薄膜沉积设备是ALD。刻蚀方面,制程微缩引起刻蚀数量和技术难度的增加。随着国际上先进芯片制程从7-5nm阶段向3nm、2nm及更先进工艺的方向发展,当前光刻机受光波长的限制,需要结合刻蚀和薄膜设备,采用多重模板工艺,利用刻蚀工艺实现更小的尺寸,使得刻蚀技术及相关设备的重要性进一步提升。
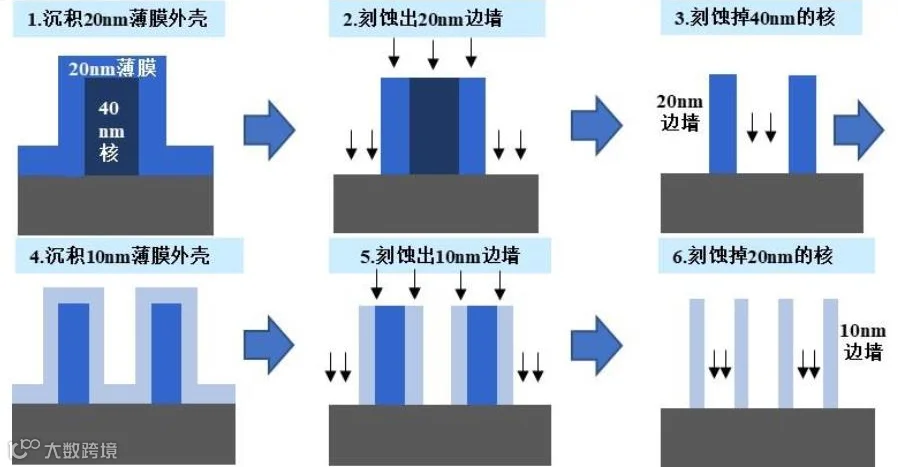
图4:刻蚀工艺流程
光刻机方面,目前全球光刻机市场基本由ASML(荷兰)、Nikon(日本)和Canon(日本)三家包揽,其中高端光刻机更是由ASML垄断,ASML是全球唯一一家具备EUV设备生产能力的光刻机厂商。Canon主要提供低端光刻机产品。从市场份额来看,ASML占据95%市场份额。光刻机可以分为无掩膜和有掩膜光刻机,其中有掩膜光刻机中的投影式光刻机是主流,适用于集成电路的大规模制造。无掩膜光刻机(直写光刻机)灵活性高,可柔性制造集成电路,但是生产效率低,一般用于集成电路器件原型和研制试验制作、光刻掩模版的制作等。为了提高精度,除了使用EUV,还可引入浸没式光刻方法,从而提高成像系统的有效数值孔径,目前长春光电所、长春国科精密、国望光电、中谱科仪等均在开展相应研发。另外,华为在上海青浦建立的用于光刻机研发的全球研发中心建设进展迅速,合计占地面积2400亩,以“终端芯片、无线网络、物联网研发”为优先项目,重点开展芯片设计、封装测试、原材料和设备三大产业。
封装技术是半导体制造后续的关键步骤之一,它涉及将芯片连接到外部电路,并提供保护和散热。先进封装(Chiplet)技术是一种将芯片功能分割为多个独立的芯片模块或小片的方法。每个Chiplet模块都具备特定的功能,而这些模块之间通过高速连接互相通信和协作。这种模块化的设计理念,使得多个厂商可以独立设计和生产各自的模块,最后通过集成实现高度定制化和可拓展性的处理器解决方案。先进封装主要分为两大类,一是基于XY平面延伸的先进封装技术,主要通过RDL进行信号的延伸和互连;二是基于Z轴延伸的先进封装技术,主要是通过TSV进行信号延伸和互连。
2.高速存储
大模型的参数量指数级增长,不仅推升了处理器的算力需求,同时也对与处理器匹配的内存系统(包括即时读写的内存和长期存储的硬盘)提出了更高的要求。内存和硬盘的最小构成单位不同。内存主要由DRAM芯片构成,数据随存随用,断电后数据消失。硬盘主要由NAND闪存(NAND Flash)颗粒构成,数据在断电后不会消失。NAND闪存是一种非易失性存储技术,由于在早期的设计中采用了类似于NAND逻辑门(与非门)的电路结构故而得名。NAND闪存基于浮栅(Floating Gate)晶体管设计,通过浮栅来锁存电荷,这意味着即使在没有电源的情况下,数据也能被保存。
为适配AI大模型的运算需求,内存技术正沿着三条主要路径进化:高带宽内存(HBM)、图形用双倍数据传输率存储(GDDR)及非易失性内存(NVMe)固态硬盘(SSD)。HBM通过堆叠DRAM芯片,实现了内存与处理器间的紧密耦合,大幅提升了数据传输速率,是处理密集型AI训练的理想选择,因其能提供低延迟和高带宽,确保了数据流的畅通无阻。GDDR原本专为图形处理器设计,现也被广泛用于AI领域,特别是在推断任务中,它能以相对经济的成本提供必要的高速数据吞吐量,是平衡性能与成本的有效方案。NVMe SSD,则聚焦于硬盘存储层次,通过PCIe接口提供高速数据访问,极大地缩短了从存储到计算单元的数据传输时间,对大规模数据集的预处理和模型持久化存储尤其关键。
简单来说,HBM和GDDR着重于加速内存至计算单元的数据流动,而NVMe SSD则优化了存储与计算间的数据传输效率。选择合适的内存路径需依据具体应用环境,如模型复杂度、数据集规模及运算任务的实时性要求来决定。
3.高速传输:光模块和高速铜缆
AI训练及调取的巨大数据量也对数据高速高宽带传输提出了较高的要求,以光缆和铜缆为主。光缆主要应用于长距离、高带宽、低延迟场景的传输,铜缆主要用于短距离和低带宽需求的传输。
光模块是用于设备与光缆之间光电转换的接口模块,主要用于实现光电信号的转换,是现代光传输网络中的必要器件。光模块是AI投资中网络端的重要环节,其与训练端GPU出货量强相关,同时推理段流量需求爆发也有望带动需求增长,800G及以上速率的光模块将是未来发展的重点。AI驱动800G/1.6T/3.2T数通光模块快速成长,更高的互联速率+更多的互联数增长奠定了光模块广阔的市场空间。当前阶段英伟达加速卡在AI训练的垄断地位,高速光模块需求与英伟达领先的训练卡出货量高度相关。AI集群网络架构升级,光模块需求弹性大。以传统三层架构到叶脊架构的转变为例,叶脊网络架构下,光模块数量提升最高可达到数十倍。根据Yole预计,2027年的3.2T时代可插拔方案就会变得非常困难,板载封装(OBO)和CPO会成为主流;2030年的6.4T时代则CPO将会成为主流方案。目前,国内厂商已占据领先位置。10G时代以北美光模块厂商为主,40G时代,中际旭创和AOI崛起;100G时代,北美传统光模块厂商份额下滑,国内光模块企业崛起。在光模块产业链中,上游主要包括光芯片、光器件和电芯片等组件。顶级光器件大多仍取决于国外供应商;中游是光模块制造商,负责将上游组件整合成成品光模块;下游客户包括电信运营商、互联网公司和云计算企业等。
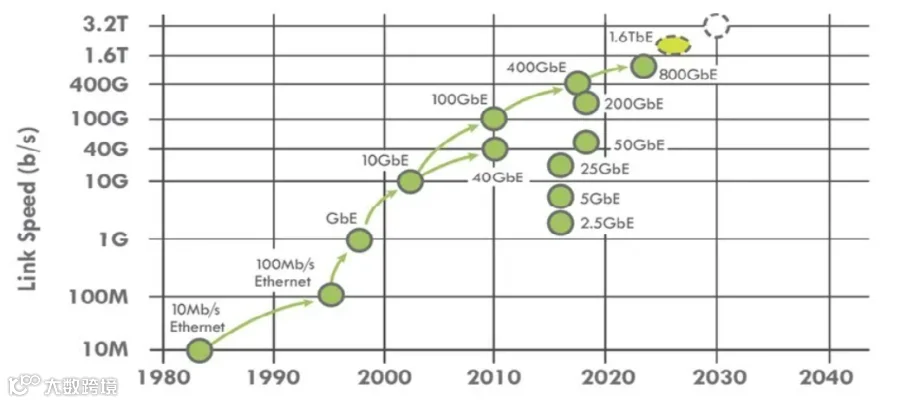
图5:光模块速率演进
由于大规模运算必然带来发热,光模块及各类芯片需匹配冷却系统。目前主流液冷架构有两种:冷板和浸没式。冷板路线是在服务器背后直接加装液冷板,将数据中心IT设备的热量传导到冷板上,然后通过冷板内部液体循环实现换热,再通过室外冷却塔等设备实现散热。浸没式则是直接将服务器电子元器件浸入特制具备高热传导性的冷媒中,冷媒沸点低,可以快速将服务器产生的热量传导出去,从而产生更高效的散热效果。目前冷板式液冷是最主流的液冷方案,IDC近日发布报告称,2023全年中国液冷服务器市场规模达到15.5亿美元,其中95%以上均采用冷板式液冷解决方案。随着算力需求的增加,机架功率密度将快速上升,新建机架功率20kW起步,并向60kW普及,因此,未来十年是冷板液冷技术的高速发展期,液冷数据中心占比将超过六成。英伟达日前新发布了GB200 NVL72多节点液冷机架级扩展系统,能够大幅提升大规模训练速度。
目前数据中心内部主流的交换网络连接方案主要包括三种:光模块+光缆的组合方案、AOC(有源光缆)方案以及DAC(直连铜缆)方案。光模块+光缆是当前最主流的长距离传输方案,主要应用于电信传输网、中距离接入网以及数据中心互联(DCI)和服务器架顶交换机等场景。在通信机柜内部,当互联距离在5米以内时,铜缆成为了常用的选择。直连铜缆(DAC)由镀银的铜导体和发泡绝缘芯线组成,无需光电转换模块,是成本最低的高速互联方案之一,也是目前高速线缆市场的主流产品。DAC在短距离应用中是一种替代光模块和AOC的低成本高效益的通信解决方案。当前国内高速线缆市场规模已突破百亿,国内已有以阿里巴巴和腾讯为代表的大型数据中心用户率先切入。
4.数据中心
数据中心(IDC,Internet Data Center)是专门用于支持计算和数据处理任务的设施或物理空间,是各大AI训练和部署的物理实体,可以理解为一个大号的计算机及其支持系统。数据中心通常拥有大量高性能的服务器、GPU加速器和专门的存储系统,以提供强大的计算能力并加速深度学习;同时也配备了高速的网络设备和优化的软件框架,以支持高效的数据传输和算法训练通过这些专门的配置和优化;能够为各种规模和复杂度的AI工作负载提供可寂稳定的计算环境,并满足大规模数据存储、备份和分析的需求,为各行各业的AI应用和服务提供了强大的支持。数据中心可按算力分为云数据中心、智算中心、超算中心三种。
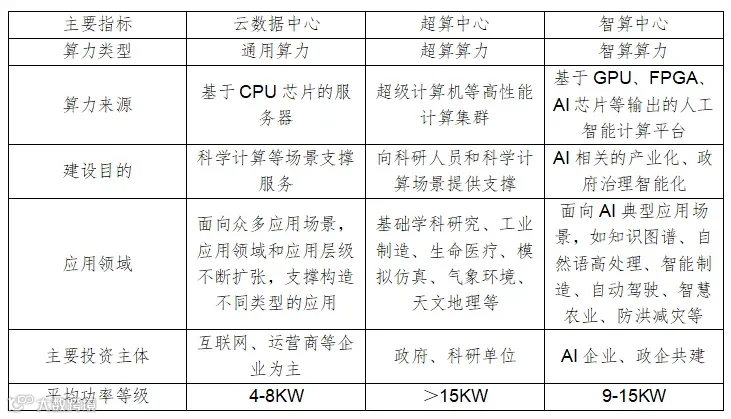
图6:数据中心分类
云数据中心面向众多应用场景和应用层级扩张;智算中心以AI专用芯片为计算算力底座,以促进AI产业化和智能化为目标,面向AI典型应用场景;超算中心主要支持科学计算和工程计算。数据中心主要组成部分由IT设备及基础设施两大类组成,IT核心设备包括网络设备(交换机、路由、连接器)、服务器(算力设备、存储设备)等,基础设施主要包括供配电设备(UPS、蓄电池、柴油发电机、配电单元)、温控设备(冷源设备、机房空调、新风系统)以及弱电布线等。
大模型带来的计算和存储开销的激增,与应用场景对资源的限制和端侧平台的计算和存储能力限制形成了矛盾,从而一定程度上限制了神经网络在一些应用场景的落地。例如,为了应用的实时、可用、隐私等方面需求(如城市安防、自动驾驶、家用机器人、无人机、穿戴设备等应用),或是场景物理限制(如手机的体积和散热等限制),以及成本控制等多方面的综合考虑,AI需要被部署在低算力、低存储的边缘计算设备和终端设备上。另外,AI部署在本地也可以更好的获知用户需求,提供更加个性化的服务。
为了解决这一矛盾,通常有两类思路,一是把大模型“做小”,通过优化轻量化算法,针对软硬件系统设计优化的小模型;二是通过部署云端平台,用移动设备实时联网对AI接口进行访问。通过混合搭配,可以减轻运营压力,降低算力成本和能耗,同时提升了安全性与用户体验。
目前,对小模型的研究已获得了初步成果。在研究总结现有大模型算法的基础上,人们提出在大模型的基础上通过知识蒸馏和合成数据来训练出质量更高的小模型,可以理解为将大模型学习到的内容作为先验知识,嵌合进小模型的学习过程。例如,微软推出的Phi-3、苹果的OpenELM、国内面壁智能的MiniCPM等,参数量虽小,但通过精准的数据集和优化算法,也能在特定任务上展现卓越性能,甚至超越某些大模型。小模型的优势在于成本效益高、反应迅速、易于部署在边缘设备上,完美契合了智能手机、物联网等场景的需求。
云端AI即将数据中心部署的AI产品将接口开放给用户访问,其对用户端的算力要求很低,可以实现大模型的强大功能,但需要高带宽、低延迟的网络通信,且安全性和隐私性相对较低。
大模型,尤其是深度学习模型,主要聚焦于文本理解,如自然语言处理(NLP)领域。大模型逐渐向多模态拓展,不仅能够独立处理文本、图像、音频等单个模态的信息,更重要能够理解并整合这些不同模态数据之间的关联和交互,实现对复杂场景的全面理解。
多模态模型,如CLIP、M6等,不仅包含了处理文本的Transformer模块,还集成了用于处理图像的卷积神经网络(CNN)或其他视觉Transformer,甚至还有处理音频的特定网络层。在多模态模型中,不同模态的数据首先被单独编码,然后通过联合训练策略,如对比学习,使模型学会在不同的数据空间中建立联系,从而能够理解和生成跨模态的内容。例如,给定一张图片和一段描述它的文本,多模态模型可以学会图像与文字间的对应关系,实现图像描述生成、视觉问答等功能。从更广义上说,自动驾驶、具身智能均是多模态大模型的落地场景,它们均拥有形式迥异的输入数据和输出要求。
多模态模型使大模型向通用人工智能(AGI)又迈进了一步,已成为大模型发展前沿方向。目前,多模态模型的最大应用是AIGC。按照模态划分,AIGC应用层可分为文字生成、音频生成、图像生成、视频生成、跨模态生成和策略生成。由于NLP技术发展历史较久,因此文字生成属于发展时间最长、落地应用也最为成熟的赛道。而在这波AIGC发展热潮中,跨模态生成将会带来最多的新应用场景。其中,文字生成图像、文字生成视频和图像/视频生成文本均已有产品问世,尤其是文字生成图像,如Stability AI,已经在全球范围内有了C端用户量的证明。随着ChatGPT、文心一言、Sora等产品问世,AIGC覆盖场景愈发丰富,表现效果逐步成熟。机遇与挑战并存,AIGC为行业带来发展机遇,创造出更多新应用场景和商业模式的同时,也伴随着一些需要应对的挑战。对于To B类企业而言,AIGC可与其现有业务进行有机结合,实现业务降本增效,为数字人、SaaS、数字设计、金融等行业带来新机遇。
1. 智能搜索
在 ChatGPT 之前,所有的AI基本上都基于逻辑规则来处理翻译任务,而翻译是最纯粹的自然语言处理问题,因此最先作为语言类大模型(LLM)的实际应用。随后,智能搜索被作为纯LLM的有力补充,以检索增强生成(Retrieval -Augmented Generation,RAG)技术为核心。RAG是一种结合了检索和生成两种技术优势的AI方法,主要用于改进自然语言处理任务中的模型表现。在传统的生成式AI模型中(如LLMs),知识完全基于模型的预训练过程,模型很难掌握最新信息或特定领域知识。RAG通过引入检索组件,允许模型在生成响应时访问和引用外部信息源,如数据库、文档集合或互联网上的实时数据,从而显著提高了生成内容的准确性和时效性。
近年来,多个前沿AI产品已使用RAG技术。例如,凭借全新的Bing搜索,微软已完全构建了其独有的AI生态。Bing将在OpenAI的下一代LLM上运行,专为搜索定制,带来全新的交互体验。微软与OpenAI合作的“Prometheus Model”可提高搜索结果相关性,同时更加安全。通过将AI模型应用于Bing搜索引擎,微软实现了二十年来搜索词条和结果相关性的最大跃升,即使是基本的搜索查询也更加准确和相关;用户体验设计上,新的Bing将带来集答案、聊天和浏览一体的搜索体验。微软认为不断优化的Bing搜索体验将助力其获得市场份额,尤其是国际市场份额(考虑到公司在大型语言模型上的优势将助力渗透海外当地市场)。此外OpenAI推出的GPT-4及其后续版本也有效解决了前代产品回答客观专业性的问题,体现出RAG在多模态领域的应用潜力。开源社区也贡献了不少基于RAG的创新项目,如LangChain框架,为开发者提供了构建结合了外部数据源的AI应用程序的开发平台。
2.自动驾驶
智能搜索仅对AI模型的“脑聪”提出了要求。而自动驾驶作为人工智能技术最重要的落地场景之一,对AI的要求不止于此。自动驾驶技术体系由算法、算力、数据三部分构成,其中算法的有效性影响自动驾驶的每一个环节,从感知环节的特征提取到神经网络的决策,都需要依赖算法改进来提高障碍物检测准确性和复杂场景下的决策能力。自动驾驶技术需要包括感知、决策、执行三部分。
感知环节要求“目明”,为了获取完整的周边环境数据作为输入,多传感器(摄像头、毫米波雷达、激光雷达等)融合将是感知系统的主流发展方向。决策环节要求“脑聪”,是自动驾驶系统中难度最高的部分,需要高效的AI模型和大量训练数据。大模型不仅能处理各类视觉检测任务(车辆检测、车道线检测、交通标志检测、红绿灯检测等)、各类分割任务(可行驶区域检测、全景分析等)和3D点云的检测和分割(障碍物的检测等)任务,也有潜力提升后续的规划和控制的相关技术。例如,特斯拉采用“粗略搜索+凸空间内的连续优化”的混合规划系统进行行进的决策。执行环节要求“手快”,主要是通过车辆稳定系统ESC、线控制动eBooster、线控转向EPS等执行机构精确快速地控制加速程度、制动程度、转向幅度、灯光控制等驾驶动作,目前AI和机器学习(ML)算法也被集成到这些系统中,以提升性能和安全性。
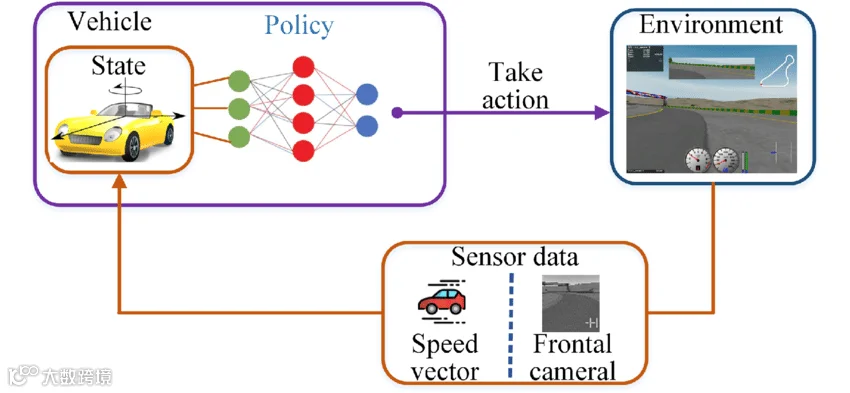
图7:FSD的端到端训练
自动驾驶产业链主要包括零部件供应商与智驾解决方案供应商。零部件供应商主要分为感知层、决策层、执行层,其中感知层包含各类传感器,决策层包含芯片、域控、计算平台等零部件,执行层包含线控制动与转向。此外解决方案供应商可谓整车厂提供整套自动驾驶解决方案,并为各种商业化用途提供方案。自动驾驶感知层硬件主要包括激光雷达、摄像头、毫米波雷达、超声波雷达。自动驾驶感知层的硬件是整车智能化的基础,以摄像头与雷达为主的传感器为自动驾驶汽车提供“视觉”与“听觉”。算法方面,端到端模型有望成共识,以BEV+Transformer算法为主流趋势,优势在于全局视野,应对corner case场景。车身架构方面,汽车底盘线控化大势所趋,未来高阶自动驾驶也将基于线控化的底盘来实现。线控底盘系统构成包括线控转向系统、线控制动系统、线控换挡系统、线控油门系统和线控悬架系统。线控油门由于技术成熟且技术壁垒相对较低,渗透率已接近100%;线控换挡渗透率约25%,正处于快速发展阶段;而线控底盘的核心技术——线控转向、线控制动及线控悬架,其渗透率仍较低,正处于大规模商业化前夜。另外,智能底盘构型趋向更加集成化、轻量化趋势发展,CTC底盘、滑板底盘有望是未来发展演进的终局产品。滑板底盘是专为电动车设计的一体化底盘结构,将整车的三电系统和转向、热管理、悬架等部件高度集成在底盘上,从而提升底盘的集成度和平整度。目前滑板底盘行业内玩家主要有新势力企业、传统车企、零部件企业和低速无人驾驶企业四类,其中新势力企业在行业内处于领先地位,大部分企业已推出自研的底盘产品。

图8:滑板底盘示例
3.具身智能
具身智能(Embodied AI)是由“本体”和“智能体”耦合而成且能够在复杂环境中执行任务的智能系统。具身智能让通用人工智能(AGI)从数字世界走向实体世界,落地在机器人、机械臂、无人车、无人机等。某种意义上说,无人驾驶正是具身智能的第一个最大的应用。因此,具身智能也要求智能体“脑聪、目明、手快”。狭义上的具身智能是指具身智能机器人,要求机器人能够听懂人类语言,然后,分解任务,规划子任务,移动中识别物体,与环境交互,最终完成相应任务。相比于传统基于AI视觉及特定场景预训练的机器人,具身智能机器人具备更强的泛化能力,在现有场景可实现跨场景快速部署、灵活作业,极大降低部署成本及周期;在消费级等新场景可拓展机器人应用边界、打开市场天花板。AGI与物理世界/机器人的融合是必然趋势,具身智能可能是商用AI场景中少数适合创业公司入局的场景。
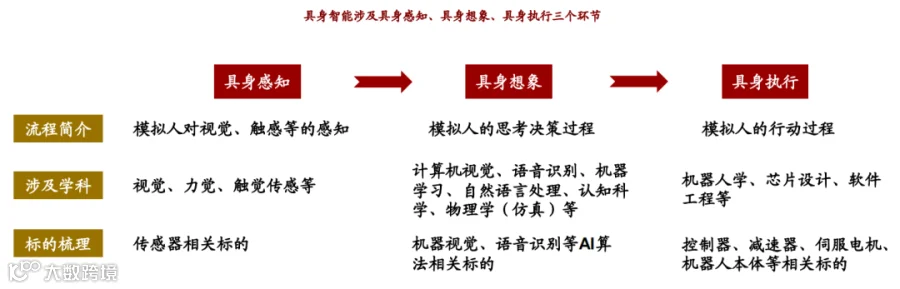
图9:具身智能决策流程
具身智能机器人将为上游供应链打开全新空间。以特斯拉发布的Optimus Gen2为例,其整机成本零部件占比分别为传感器37%、电机20%、丝杠20%、减速器13%.传感器37%。谐波减速器和行星滚柱丝杠构成了特斯拉人形机器人执行器的核心。执行器决定着机器人的负荷和精度。特斯拉的人形机器人共有28个大的执行器(不含手指执行器),主要为两大类:直线/线性执行器和旋转执行器。旋转执行器由电机+谐波减速器+抱闸+双编码器+力矩传感器+轴承组成。直线执行器由电机+行星滚柱丝杠+位置编码器+力传感器+轴承组成。
具体来说,人形机器人可以分为3大部分6个子系统。3大部分是机械部分、传感部分和控制部分;6个子系统是机械系统、控制系统、驱动系统、感知系统、人机交互系统和环境交互系统。控制系统是机器人的神经系统,用于控制其运动。控制系统主要参与者包括两类:一是主流的大型机器人厂商,自主研发控制器和控制算法,包括ABB、KUKA、发那科国内的埃斯顿等。二是专业的控制系统厂商,单独售卖控制器,提供可扩展和二次开发的硬件和软件平台,包括KEBA、贝加莱、倍福。感知层+机器视觉是机器人的“眼睛”。机器视觉的本质是为机器植入“眼睛”,利用环境和物体对光的反射来获取及感知信息,需要具备对外界环境的识别能力,实现导航、避障、交互等功能,需要使用传感器识别物体、测距等。机器视觉是AI深度学习的一种应用与技术方向,无论是人形机器人还是智能驾驶都是机器视觉的落地方向。交互系统依托多模态大模型,大模型和具身智能已成为了推动人工智能未来发展的关键力量。AI大模型浪潮下,全球巨头均发力探索AI大模型与具身智能的融合。目前,诸多大厂已在具身智能领域进行布局,谷歌发布史上最大通才模型PaLM-E;微软探索如何将ChatGPT扩展到机器人领域;阿里巴巴-千问大模型正在实验接入工业机器人等。
在具身智能领域,数据对于训练深度学习模型以增强和优化机器人能力比其他AI应用场景更为重要。这主要是因为,具身智能的数据涉及机器人与其动态环境之间的复杂互动,必须捕捉在多样且常常不可预测的环境中的各种物理互动的数据,这种数据涉及做实验、布置不同物理情景等,其获得成本远高于在互联网采集文本、图片等数据。而且,与互联网上大量的文本数据不同,训练具身智能也面临“数据孤岛”的挑战。具身智能机器人往往需要在特定的受控环境中收集各项物理和环节数据,不同企业和科研团队之间的测试场地和训练数据往往不共通,可能导致重复劳动和资源浪费,形成“数据孤岛”。
4.其他行业的方法论革新
基于AI大模型,许多行业的方法论和生态也将发生革命性的转变。首先,仅RAG技术就具备很强的可移植性,可以有针对性地在各种不同的专业领域开发特有的大模型,例如知识产权检索、技术成果团队匹配等。其次,各类泛用AGI可以加速包括AI行业自身在内的迭代和革新。例如在医疗健康领域,AI可以通过深度解析复杂的生物信息,助力疾病的早期诊断与精准治疗,同时加速药物研发,精确预测药物结构、反应位点、蛋白质结构等,促进合成生物等其他业态的蓬勃发展。教育科技方面,个性化学习系统可以依托AI,量身定制教育内容。环境保护方面,AI能够监控和预测气候变化模式,优化资源分配,支持可持续农业实践,以及保护生物多样性,助力全球环保事业。智慧城市管理方面,通过分析城市数据,AI可以优化交通流量,提升公共安全,促进能源效率,打造更加宜居高效的未来城市。
1. 微软(Microsoft)
微软作为颠覆式创新者,在算力+算法+应用生态上已呈现完整布局。微软2019年3月就对OpenAI进行了10亿美金注资,2023年1月24日,微软公司在官方博客宣布已与OpenAI公司扩大合作伙伴关系,两家公司合作伙伴关系进入新阶段。自2019年注资OpenAI开始,微软便成为了OpenAI的独家云计算服务商。微软的云服务一直为OpenAI的产品、API服务和研究中所有的工作负载提供支持,同时双方在Azure上合作研发人工智能超级计算技术。此后,微软于20年便推出了用于在Azure上训练超大规模人工智能模型的超级计算机,其拥有超过28.5万个CPU核心和1万个GPU,其中每GPU拥有400Gbps网络带宽。
AI算法层面,微软在自研与合作上同时进行,与OpenAI紧密合作,联手英伟达推出威震天-图灵自然语言生成模型(Megatron Turing-NLG),同时自研视觉基础模型Florence。应用上,微软完成产品生态升级,已发布一系列涵盖从Azure OpenAI、Copilot Stack、开发工具到协作应用等领域的AI“全家桶”,将ChatGPT整合进入自身的软件与服务生态之中。根据微软CEO纳德拉在2月8日的发布会上所言,传统搜索引擎痛点主要在于结果不准确,而搭载GPT架构的全新Bing搜索引擎将有效解决这一痛点。
2.谷歌(Google)
谷歌作为算力和资金丰富的互联网巨头,同时采用加速推出自研的聊天机器人的手段和联合及投资ChatGPT的竞争对手来建立自己的护城河。自研产品方面,谷歌于2024年5月发布几十款和AI结合的新产品,以对阵OpenAI,包括Gemini1.5Pro、Gemma开源模型,同时推出五款基于Gemini大模型的生成式AI产品。产品中,例如ProjectAstra智能助手。它与NotebookLM结合,将成为GPT-4o的有力竞争对手。硬件方面,谷歌具备TPU研发能力,发布了迄今为止最强大、最节能的张量处理单元TrilliumTPU(第六代)。据谷歌介绍,第六代硬件将为生成式人工智能模型和工作负载提供支持,提供比现有TPU显著增强的计算、内存和网络功能。TrilliumGPU的高带宽内存容量和带宽是原来的两倍,计算能力相比前代提升4.7倍,将在2024年底面向用户(包括云客户)推出。投资ChatGPT竞争对手方面,谷歌向Anthropic投资近4亿美元,获得10%股份,同时GoogleCloud为Anthropic首选云供应商,为其提供AI算力。除了Anthropic,Google云也和Cohere和C3.ai等AI初创公司和开发平台建立了合作。
3.苹果(Apple)
苹果入局AI相对较晚,对于AI的态度更加谨慎,一方面结合自身芯片研发实力推出最新M4芯片及其生态,同时立足手机、个人电脑等苹果强势业务,针对有关设备的特点、痛点开发AI模型,并推出颠覆式终端设备。苹果此前曾陆续发布多模态大模型MM1、Ferret等相关研究工作。直到上月的WWDC大会,苹果宣布了其全线产品的重大更新,引入了生成式AI技术。在WWDC大会上,苹果重点推出了基于M4芯片及匹配的个性化智能系统Apple Intelligence,集成了生成式AI,并与iOS18、iPadOS18和macOS Sequoia深度融合。苹果M系列芯片采用统一内存架构设计,允许CPU、GPU及其他协处理器共享和访问相同的内存池,使得并行计算更快速高效。模型侧,结合自身业务优势,苹果推出OpenELM模型,包含2.7亿、4.5亿、11亿和30亿个参数的四种版本,定位于超小规模模型,运行成本更低,可在手机和笔记本电脑等设备上运行文本生成任务。同时,苹果展示了多模态模型Ferret-UI。Ferret-UI系统可以理解手机屏幕上的应用程序内容,专为增强对移动端UI屏幕的理解而定制。在应用测,苹果正改造Siri,让Siri更好地处理其现有任务,包括设置定时器、创建会面日程和向杂货清单添加物品等,其功能更倾向于个人助手。同时,苹果推出的全新虚拟/增强现实眼镜AI Vision Pro开启了空间计算时代,可以让数字内容看起来就像在用户的真实世界存在,可能是AI终端的颠覆式产品,由于XR设备可承载海量的信息流和深度的内容数据,有望打造全新生态。
4.特斯拉
特斯拉从车出发打造能源生态闭环,进军机器人和AI领域,同时向AI上游布局储能。特斯拉的AI战略始于其自动驾驶技术的研发。特斯拉最早推出Autopilot辅助驾驶系统,如今已经迭代至Hardware3的完全自动驾驶计算平台(FSD),其自主研发的FSD芯片拥有强大的计算能力和低功耗特性。不同于大部分国内厂商多传感器融合方案,特斯拉FSD自动驾驶采用以摄像头为核心的纯视觉解决方案,特斯拉HW2.0/2.5/3.0版本硬件都配备了8颗监测不同方位的摄像头,分别为三颗前置摄像头(其中1颗主摄像头、1颗广角摄像头、1颗窄视长焦摄像头)、2颗前侧摄像头、2颗后侧摄像头、以及1颗后置摄像头。FSD的设计哲学在于打造一个闭环的、端到端的决策系统,车辆不仅要具备感知环境的能力,还要能理解环境信息并做出驾驶决策,且所有行为都由车辆自身完成,无需依赖外部基础设施的辅助。若车辆遇到各类“边角案例”或驾驶员操作与系统“预想”操作不一致时,车辆会脱敏匿名将实际情况上传给特斯拉云端服务器,通过庞大的集中算力进行深度学习以优化系统,有关结果会及时同步给所有特斯拉汽车。
特斯拉还布局了具身智能机器人“擎天柱2代”(Optimus Gen2),最新改进包括整体外观设计更加精细、行走速度提高了30%、重量减轻了10公斤,同时平衡感和身体控制能力得到改善,还配备了全新的双手。马斯克预计,长远来看全球人形机器人的总数最终将达到100亿台,而Optimus业务有望为特斯拉贡献数十万亿美元的市值。另外,特斯拉布局的储能业务将成为其在AI竞争的后期的重要利润来源。AI热潮带来的电力需求将让特斯拉成为美国能源市场上的关键参与者。摩根士丹利预计,2025年,特斯拉的储能业务Tesla Energy利润率可能会超过特斯拉的汽车业务。
5.OpenAI
OpenAI的产品矩阵布局以大模型及其应用端产品为主,以ChatGPT系列产品为核心,涵盖文本、图像、视频生成,同时OpenAI已开始布局AI芯片及智能驾驶领域。ChatGPT作为其文本生成的代表作,以其强大的语言理解和生成能力,开启了大模型的热潮。紧随其后的是DALL·E,的图像生成工具,经过数代的发展,DALL·E3以其卓越的效果受到市场的青睐。最新推出的Sora则专注于将文本内容转化为视频,代表了AIGC(生成式AI)技术在视频领域的突破。OpenAI正在布局3D生成、AI助手、聊天式对话、语音生成等应用。在3D生成领域已发布Point-E、Shape-E模型,预计未来将有更高质量模型出现。
在硬件层面,OpenAI正筹划进入AI芯片市场,目标是开发出能够与NVIDIA GPU竞争的AI芯片。这一战略布局基于OpenAI在算法设计上的深厚积累,以及对大模型计算需求的深刻理解。与传统的AI芯片制造商相比,OpenAI的优势在于能够从算法优化的角度出发,设计出更适合其自身算法需求的硬件。OpenAI通过创业基金布局智能驾驶软件公司Ghost Autonomy,拓展下游应用。
6.英伟达
英伟达是全球领先的AI算力方案提供商,其产品体系涵盖高性能显卡、芯片、硬件及软件解决方案,广泛服务于游戏、专业可视化、数据中心及人工智能等多个前沿领域。显卡方面,英伟达提供包括GeForce、Titan、Quadro和Tesla在内的系列,分别瞄准消费级市场、高端计算、专业设计及数据中心应用。在芯片领域,英伟达推出的GPU、CPU和DPU,不仅巩固了其在图形处理和并行计算的传统优势,更在数据中心、自动驾驶、AI推理与训练等新兴技术领域展现出强大驱动力。硬件产品中,基于其先进芯片技术的服务器、网络设备及存储解决方案,为用户搭建了高效、可靠且安全的计算环境。软件方面,英伟达开发了NGC、虚拟GPU等产品,极大提升了开发者的工作效率,优化了图形处理、游戏体验与AI应用。为了便于调用GPU资源,英伟达开发了一种并行计算平台和编程模型CUDA,不仅可以简化GPU编程,还通过其生态系统优化了深度学习框架的性能,如TensorFlow、PyTorch等,这些框架广泛应用于语音识别、自然语言处理、计算机视觉等AI应用中。
同时,英伟达也加强了对终端的渗透,对于当前最看好的AI制药、新能源汽车、机器人等应用端,英伟达或通过与战略伙伴深度捆绑合作,或通过亲自下场投资的方式,推动其GPU在这些领域的广泛应用。
7.Meta(原Facebook)
Meta是开源大模型标杆,主要围绕社交媒体应用进行布局与商业化。Meta推出的AI大模型以开源为特征,旗下Llama模型均对外部开发者免费开放。2024年4月,Meta推出号称“最强开源模型”的Llama-3,在多个领域领先同等规模的其他模型。Meta背靠强大的社交平台积累,在智能软硬件端同时发力AI应用。基于Llama模型推出的类ChatGPT式AI聊天助手Meta AI具备智能对话、搜索集成、图像生成等多种功能,已接入Meta家族的多个应用软件中,如Instagram、WhatsApp、Facebook等。得益于Meta巨大的社交平台用户群体规模,接受公共用户数据训练后的Meta AI表现可期。除了社交平台,Meta AI还能用于Meta推出的智能眼镜和Meta Quest头显设备,在智能硬件领域开启AI应用商业化进程。
国内大模型研发迅速,多个厂商已有深厚积累。商用聊天大模型领域,在GPT-4发布后,国内大模型军备竞赛加速,均力争性能赶超国外玩家。2023年3月13日,OpenAI发布了作为行业指标的语言模型GPT-4,其后百度发布文心一言,拉开国内大模型追赶GPT-4的序幕;4月商汤科技发布SenseChat,阿里巴巴发布通义千问;7月华为云发布盘古大模型3.0,均力争对标GPT-3.5、在部分性能指标超越GPT-4。此2023年11月7日GPT-4 Turbo发布,24年4月商汤发布6000亿参数级大模型日日新5.0,根据Open Compass评测已率先对标GPT-4 Turbo水平。2024年2月16日,OpenAI发布Sora,以在视频生成领域开启新一轮追赶进程。
1. 华为
华为依托自身业务优势,深耕算力打造强力底座,结合大模型,以提供To B和To G端服务为主。华为在2012年就建立了诺亚方舟实验室负责人工智能领域的研究,研究方向囊括自然语言处理、人工智能决策等领域,具有AIGC模型开发的技术基础。华为是国内最早布局大模型的云服务商之一,早在2021年就已经发布盘古大模型。
华为在最底层构建了以鲲鹏和昇腾为基础的AI算力云平台,以及异构计算架构CANN、全场景AI框架昇思MindSpore,AI开发生产线ModelArts等,为大模型开发和运行提供分布式并行加速,算子和编译优化、集群级通信优化等关键能力。盘古大模型已在多个行业领域实现赋能:政务领域,华为云携手深圳市福田区政务服务数据管理局,上线了基于盘古政务大模型的福田政务智慧助手小福,改变传统的一网通办模式;铁路领域,华为货车检测助手可以精准识别67种货车、430多种故障,无故障图片筛除率高达95%;在煤矿领域,盘古矿山大模型已经在全国8个矿井规模使用,可以覆盖煤矿多个业务流程下的1000多个细分场景。
2.阿里巴巴
阿里本身是云计算行业的领头羊,为进军AIGC领域打下了坚实技术基础。算法模型层面,M6模型参数已突破10万亿。应用推广层面,已构建8大AI应用场景,M6模型也已实现落地,类ChatGPT产品仍在内测中。阿里基于其语言语义、图片识别、智能语音技术搭建了八大场景的AI方案,包括智能客服(智能营销、智能外呼、在线客服等)、信息审核、图片搜索、智慧媒体(用于运营及内容制作)、智能会议、智慧法庭、智慧课堂、智慧医疗等。其中,M6大模型的已落地的应用包括但不限于在犀牛智造为品牌设计的服饰、为天猫虚拟主播创作剧本,以及增进淘宝、支付宝等平台的搜索及内容认知精度等,M6模型在设计、写作、问答等方面表现突出。阿里版ChatGPT也已处于内测阶段,阿里可能将AI大模型技术与钉钉生产力工具深度结合。
3.腾讯
腾讯主要通过AI Lab进行AI相关技术的研究,其成立于2016年,基础研究方向为计算机视觉、语音技术、自然语言处理和机器学习,应用包括游戏、数字人(虚拟形象平台“异次元的我”、手语数智人“聆语”等)、内容(写稿机器人“梦幻写手”等)和社交AI等,目前腾讯A ILab的AI技术在微信、QQ、天天快报和QQ音乐等腾讯产品中已得到落地使用。腾讯的AI体系——“腾讯云智能”内部包含四大层级,最底层是算力(芯片等)、中间是腾讯云智能TI平台,从标注、训练、推理到应用都涵盖在内,然后是AI落地加速及全场景数智化,比如数智人、语音助手、智能客服,让用户真正“开箱即用”。
腾讯的AI大模型为“混元”,该模型包含但不限于计算机视觉、自然语言处理、多模态内容理解、文案生成、文生视频等多个方向的超大规模AI智能模型。与业界其他大模型相比,混元首创了层级化跨模态技术,可将视频和文本等跨模态数据分别做拆解,通过相似度分析,综合考量并提取视频和文本之间层次化的语义关联。该模型已落地于腾讯内部数据挖掘、搜索、广告推荐等。
4.百度
百度作为国内搜索及AI领域头部公司,在AI行业布局较早,新业务均以AI作为重要技术底座。除了广告收入外,公司其他新业务包括云服务、智能设备及服务、智能驾驶等,与人工智能技术有较强关联,是当前公司重点发力投入的第二、第三曲线业务,在AI发展方面把握先机。百度智能云在AI领域领跑,同时自研AI芯片昆仑,具备软硬一体的全栈AI能力。模型层方面,文心大模型基于千亿级参数训练,开源深度学习平台飞桨也积累了大量开发者。2023百度世界大会上,百度通过文心大模型4.0对搜索引擎、百度文库、如流、百度网盘、百度地图等产品进行了全面重构。
5.其他厂商
其他互联网大厂(京东、字节、网易、快手)亦有布局。京东云在AIGC的布局主要聚焦文本、声音、对话生成、数字人生成和通用型ChatAI技术五个方面。字节跳动成立聚焦AI大模型应用的新部门Flow,开启对AI应用层的深度布局。快手在大规模语言模型相关的研究覆盖LLM模型训练、文案自动创作与生成、对话系统开发等领域。
国内创业公司代表月之暗面(Moonshot AI)创立于2023年3月,2023年10月推出全球首个支持输入20万汉字的智能助手产品Kimi。相比当前市面上以英文为基础训练的大模型服务,KimiChat具备较强的多语言能力。
量子信息技术是构建新质生产力推动高质量发展的重要方向。全球主要国家在此领域基本都进行了战略布局。我国在“十四五”规划中就将量子信息列为与人工智能、集成电路等同等重要的技术。
量子信息技术主要涵盖三个核心领域:量子计算、量子通信和量子测量。其中,量子计算是按照既定的算法和程序,对量子态进行操控和测量的过程。与经典计算不同,量子计算并不会真的去计算,而是用特定算法和程序对量子态进行操控,利用量子现象,通过观测量子的行为自然的得到结果。量子计算领域尽管仍处于探索阶段,但已经取得了显著的成就。海外科技巨头带动量子计算产业发展,IBM、微软、谷歌等公司先后发布量子计算路线图,与此同时,国内量子计算产业与海外科技巨头差距不断缩小,2024年1月16日我国第三代自主超导量子计算机“本源悟空”上线运行可以一次性下发、执行200个量子线路的计算任务,比国际同类量子计算机具有更大的速度优势。量子计算软硬件基础设施不断成熟,为商业化落地打下良好基础。当前全球范围内针对量子计算机,已经形成超导、离子阱、光量子、中性原子、半导体量子等主要技术路线,以及以量子门数量、量子体积、量子比特数量等核心指标构成的性能评价体系。量子计算云平台将量子计算机硬件或量子计算模拟器与经典云计算软件工具、通信设备及IT基础设施相结合,为用户提供直观化及实例化的量子计算接入访问与算力服务。软件方面,量子算法不断发展中,在当前硬件条件下重点是综合考虑NISQ算法的容错代价与算法性能之间的平衡,量子软件体系处于开放研发和生态建设早期阶段,正在不断成熟。
量子计算因其独特的并行性和超越传统计算机的强大计算能力,被寄予厚望成为解决当前AI领域算力瓶颈的颠覆性力量。传统计算机基于二进制位(比特),而量子计算机使用的是量子比特,后者可以同时存在于多个状态,利用量子叠加和纠缠现象实现并行处理,理论上能够在某些特定问题上展现出指数级加速的效果。
在AI领域,特别是在深度学习、强化学习以及优化问题(如训练神经网络、搜索最优解、最优化路径规划等)上,随着数据量和模型复杂度的增长,对计算资源的需求呈现爆炸式增长。如果量子计算能够成熟应用,将有可能显著缩短这些过程的运算时间,极大提升效率。不过,目前量子计算还处于发展阶段,量子比特的数量、稳定性和错误纠正等问题尚待解决,实际应用到AI领域还有一定的技术挑战。
狭义的类脑智能(brain-inspired intelligence)是借鉴生物脑的感知认知行为机制和信息传递机制,构建相关类脑智能算法、模型和系统,并通过软硬件协同实现的机器智能。狭义的类脑智能与传统的AI有较大的区别,类脑智能计算的计算速度快、能耗少、逻辑分析和推理能力更强,类脑智能计算机体积小。类脑智能有望对计算系统架构、智能芯片、智能计算机、智能机器人进行颠覆性创新,在智能时代有着广泛的应用前景。广义的类脑智能包括类脑血管系统等生物脑的非神经元及神经网络系统。类脑血管散热系统有助于设计更加节能、更小体积、更为安静、更快速度和更加智慧的类脑智能计算机系统。广义的类脑智能还包括正在兴起的类脑组织工程(brain-like tissue engineering),其应用多能干细胞诱导分化的方法,获取具有大脑细胞类型及结构的类脑器官,模拟和重现大脑的结构和功能及疾病发生过程,并探索类脑器官的潜在医学应用,以期恢复、维持或改善损伤大脑的功能。近年来,我国在类脑计算方面不仅在基础理论上而且在产业技术上,都走在世界前列。
类脑智能相关研究的一大落地场景为脑机接口。脑机接口与AI关系密切,相互促进。AI技术可以显著提高信号处理和解读的准确性和效率。同时,AI可以优化脑机接口系统的反馈机制,提高用户体验。未来,通过AI算法,脑机接口系统可以更准确地预测用户的动作和需求。因此,脑机接口的发展必须紧密结合当前的AI技术,以显著提升系统的整体水平。当前,中国在脑机接口的学术研究、专利数量和研发投入上与发达国家有差距。中国的研究主要由国家支持,而发达国家多为公司自发研究。目前,侵入式脑机接口在全球范围内尚未实现产业化,仅处于临床试验阶段。

来源:常州投资集团博士后创新实践基地/龙城产业技术研究院
编辑:康狄 陈希
审核:赵沁 蒋雅君