
在数据爆炸和AI驱动的新时代,企业数字化转型亟需高效、弹性的计算支撑与智能化平台支援。领码SPARK融合平台通过深度集成阿里云Serverless Spark,实现了数据计算的智能弹性伸缩与性能飞跃,显著提升了数据处理效率和业务响应速度。本文全面揭秘该融合平台的技术架构、应用场景和AI赋能实践,结合流利说等真实案例分析,展现云原生技术在数据驱动创新中的“新引擎”作用,为企业数字化转型提供理论指导和落地方案。

1. 时代呼唤智变:数字化转型的痛点与机遇
在数字经济快速发展的背景下,数据成为企业竞争的核心资产。然而,企业在数字化转型中面临诸多挑战:
数据孤岛:不同系统之间的数据流动受阻,影响业务决策的及时性和准确性。
计算资源瓶颈:传统计算架构无法满足海量数据的处理需求,导致响应速度慢。
运维压力增大:技术团队需频繁应对集群维护和故障排查,影响创新效率。
AI需求日益增长:企业需要动态、弹性的算力支持,以适应不断变化的业务需求。
领码SPARK融合平台结合阿里云Serverless Spark的技术优势,旨在为企业在数字化转型过程中提供必要的支持和解决方案。
2. 双引擎驱动:领码SPARK融合平台与阿里云Serverless Spark的深度剖析
2.1 领码SPARK融合平台架构解析
领码SPARK平台构建于先进的云PaaS架构上,采用多层设计实现数据集成、开发赋能和安全治理的有机统一。
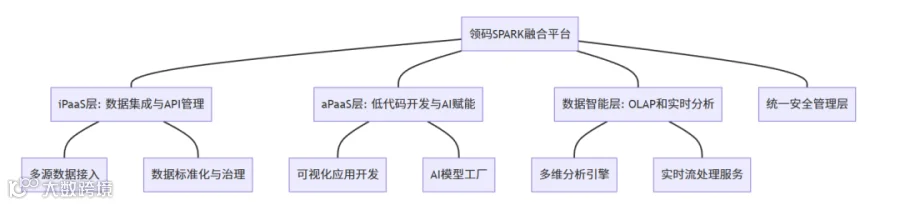
iPaaS层:连接异构数据源,保障数据标准化与规范管理。
aPaaS层:提供低代码开发平台和AI能力,降低业务创新门槛。
数据智能层:融合OLAP与流处理,支持多样化数据分析需求。
安全管理层:提供权限管控、合规审计等企业级安全保障。
2.2 阿里云Serverless Spark优势深度解读
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2.3 双强联合的“化学反应”
领码SPARK提供“智慧大脑”,阿里云Serverless Spark为其注入“算力翅膀”,二者的结合,有效解决了大数据计算中的瓶颈,提升了数据处理的灵活性和业务响应速度,并促进了企业在数字化领域的创新和发展。
3. 应用实践全景:离线ETL、实时分析与AI模型训练三大场景解码
3.1 极速ETL:告别任务排队与资源浪费
对于每天涌入的海量业务数据,如何保ER确保高效的ETL任务处理成为企业迫切的需求。通过领码SPARK平台的iPaaS层,将ETL计算委托给Serverless Spark,确保秒级启动,显著提升数据处理效率。
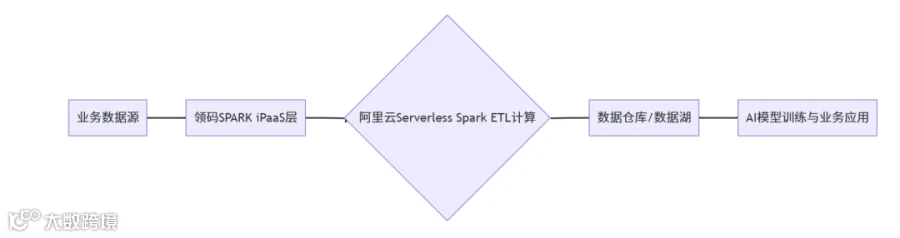
实证案例:
任务耗时减少约40%
Shuffle数据减少80%
资源利用率提升近50%
操作指南:利用平台的可视化调度面板,轻松配置任务流和任务依赖,实现全链路自动化。
3.2 实时分析:洞察纷繁业务瞬息变化
随着业务需求的变化,实时数据处理变得至关重要。领码SPARK结合流处理解决方案,利用Serverless Spark的弹性计算能力,实现实时数据的处理与分析。
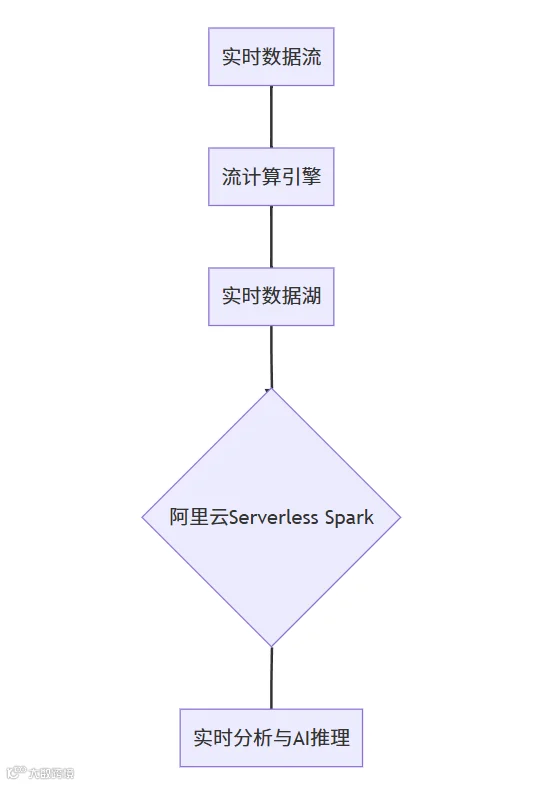
3.3 AI训练与推理:智能算力核心基石
海量数据的AI训练需高效的算力支持,利用Serverless Spark的弹性机制,领码SPARK能够轻松应对突发的计算需求。
实操指引:在模型训练过程中,配置灵活,支持多租户统一管理与按需分配,进一步降低管理难度。
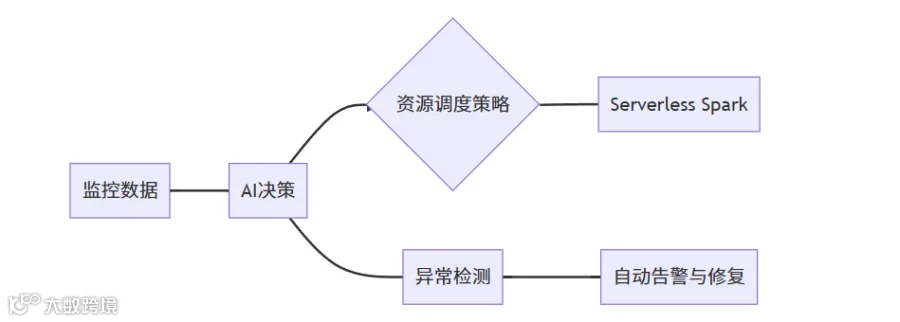
4. AI赋能与智能运维:重塑数据架构新生态
智能资源编排:通过AI预测任务负载,实现资源的自动调度和优化配置。
自动性能优化:根据执行计划,AI动态调整Spark配置,达到自适应调优的效果。
故障检测与自愈:AI监控集群性能,提前发现潜在问题并触发修复流程,提升系统稳定性。
5. 实操指南与效益洞察:步步为营,价值倍增
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
6. 未来展望:从平台走向生态,预见数字智能新星辰
生态开放共建:吸引更多数据源、AI模型和行业合作伙伴,以构建更为庞大的数据智能生态链。
云原生与智能深度融合:随着AI技术和Serverless Spark的演进,推动自动化与智能化运营的新阶段。
全员数据智能:借助平台的便捷性,企业所有员工都能更高效地使用数据和AI工具,提高整体智能化水平。