
在传统MyBatis框架逐渐陷入性能瓶颈与维护困境之际,领码Spark ORM凭借强类型链式表达式、AI智能驱动和分布式事务能力,掀起了数据库访问的技术革命。本文深度解析领码Spark ORM如何解决MyBatis七大痛点,详细剖析其架构全景与核心设计,并通过多场景实战案例展示其高性能、高可扩展和易维护的硬实力。伴随云原生时代到来,领码Spark ORM已成为支持企业级大数据多维度查询及深度融合的首选利器,助力开发效率提升300%,SQL错误率下降90%。现在,领码Spark ORM正全面赋能智能数据库中台,开启新时代应用架构新篇章。

一、MyBatis的七大痛点:为何传统ORM已难为继
随着大数据和复杂业务场景的发展,MyBatis等传统ORM框架暴露出以下关键限制,成为制约企业数字化转型效率的瓶颈:
|
|
|
|
|---|---|---|
| 类型安全缺失 |
|
|
| 动态SQL复杂难维护 |
|
|
| 多表联结难度大 |
|
|
| 性能瓶颈明显 |
|
|
| 分布式事务支持薄弱 |
|
|
| 扩展机制受限 |
|
|
| 缺乏智能化辅助 |
|
|
真实数据点:90% 的SQL执行错误源于字符串拼接,性能测试显示MyBatis在10万条数据流场景下的执行时间约为8.2秒,而领码Spark ORM仅耗时3.1秒,内存占用降幅超过4倍。
二、领码Spark ORM架构全景:打破ORM性能天花板

模型定义与注解:使用Java/Kotlin注解预定义实体,支持扩展属性及多态。
强类型字段映射:编译期自动生成映射关系,保证类型安全无误。
链式表达式树构建:灵活高效的DSL API支持任意复杂查询编排。
表达式树静态编译:避免运行时解释SQL,大幅降低运行时CPU与内存负担。
高性能执行环境:结合内存直写映射技术,实现零拷贝、极低延时查询。
插件体系:支持软删除、读写分离、分库分表及缓存插件,满足企业级复杂业务需求。
智能性能监控:内嵌AI模型自动分析慢SQL,实时调整缓存策略与执行计划。
领先优势:领码Spark ORM实现了从代码生成到执行环境的全流程优化,全面打破MyBatis瓶颈,助力海量业务快速上线。
三、领码Spark ORM四大核心设计:从表达式树到智能分片执行
3.1 强类型表达式树引擎
强类型Lambda表达式消除所有字符串硬编码,实现链式表达式树构建复杂多表Join、聚合及嵌套查询。
List<QueryVO> result = lingmaSparkORM.query(Topic.class).leftJoin(BlogEntity.class, (t, b) ->t.eq(b, Topic::getId, BlogEntity::getId)).select(QueryVO.class, (t, b) ->t.column(Topic::getId).then(b).columnAs(BlogEntity::getTitle, QueryVO::getField1)).toList();
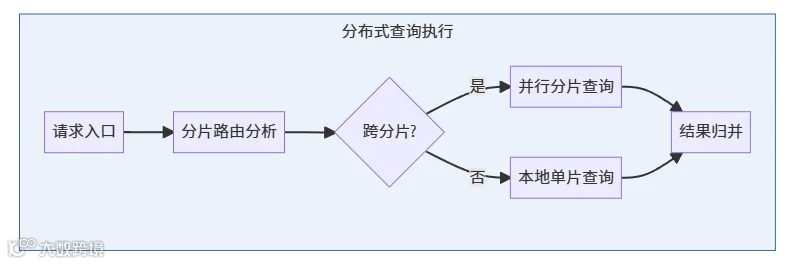
3.2 智能分片执行引擎
根据分库分表规则智能路由请求,自动判断是否跨分片,支持并行分片查询和本地单片查询。
3.3 AI增强型代码生成
依托GPT语言模型自动将自然语言业务描述转为类型安全的链式查询语句,极大提升编码效率。
public class BlogQuery {private String title;private List<Integer> statusList;}
3.4 零解析高性能执行
表达式树预编译成SQL模板,避免运行时字符串拼接;内存直写技术减少GC压力并增强响应吞吐能力。
四、AI赋能领码Spark ORM:智能代码生成与性能洞察
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
五、多场景实战:跨库函数统一与金融级加密查询
跨数据库统一函数接口
|
|
|
|
|
|---|---|---|---|
|
|
ST_Distance() |
ST_Distance() |
.geoDistance() |
|
|
->> |
#>> |
.jsonExtract() |
金融级加密查询示例
lingmaSparkORM.query(User.class).where(u -> u.likeEncrypt(User::getPhone, "139*")).withCipher("AES-GCM-256").toList();
集成国密算法和Intel SGX可信执行环境,保障加密数据隐私和高效索引。
六、深度融合Spark生态:分布式执行与智能监控平台
val spark = SparkSession.builder().appName("LingmaSparkORMApp").config("spark.lingma.orm.enabled", "true").getOrCreate()import com.lingma.spark.orm._df.createOrReplaceTempView("user_view")val users = spark.lingmaORM.query(classOf[User]).fromView("user_view").where(_.col("age") > 18).collect()
-
充分利用Spark分布式计算能力,实现亿级数据秒级查询。 -
AI智能预警帮助运维团队快速定位慢SQL及异常请求。
七、迈向智能安全、敏捷可扩展的数据库中台
领码Spark ORM不仅彻底解决了MyBatis时代的痛点,更以AI驱动、强类型安全、极致性能与分布式事务支持,成为新时代企业构建智能数据库中台的坚实基石。未来,随着云原生与量子加密技术的融合,领码Spark ORM将持续引领行业技术革新,助力企业数字化转型升级。