
PART 01
PART 02
|
|
|
|
|---|---|---|
| 国产数据库 |
|
|
| 国产操作系统 |
|
|
| 国产芯片 |
|
|
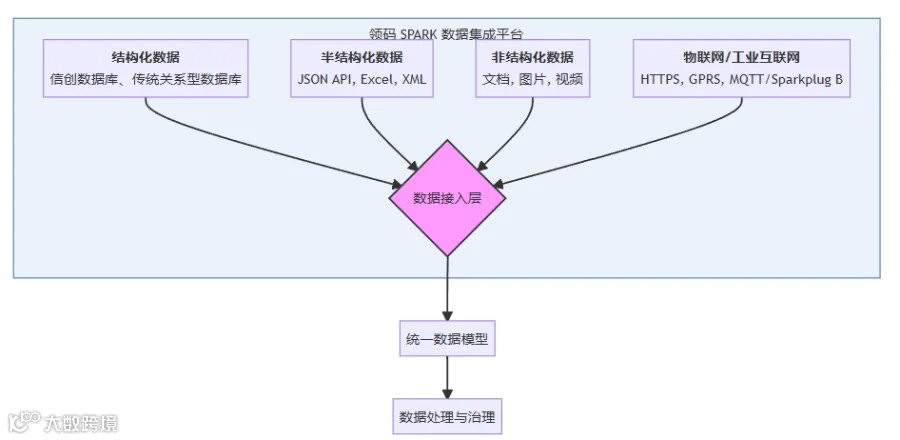
-
通用API集成: 平台原生支持 RESTful、SOAP 等主流 API 协议,允许企业快速注册和管理内外部接口,打破应用壁垒,实现异构系统间的高效对接 。 -
半结构化数据处理: 针对广泛存在的 JSON 和 Excel 文件,平台提供了灵活的解析能力。用户无需编写复杂代码,即可定义字段、解析嵌套结构,轻松将这些数据纳入统一管理体系 。 -
多协议支持: 1.HTTPS:保障了 Web 数据传输的安全性。 2.物联网协议 (IoT):在工业4.0和智慧城市等场景中,设备数据是关键。领码 SPARK 支持 MQTT及其工业增强规范 Sparkplug B 能够高效、可靠地接入海量设备数据。 3.GPRS:对于一些通过移动网络传输数据的传统或远程设备,平台同样提供了接入方案,确保数据链路的完整性 。 -
非结构化数据接入: 未来已来,企业的洞察力越来越多地来源于文档、图片、音视频等非结构化数据。领码 SPARK 具备接入此类数据的能力,为后续结合AI进行内容分析、知识提取奠定了基础。
PART 03
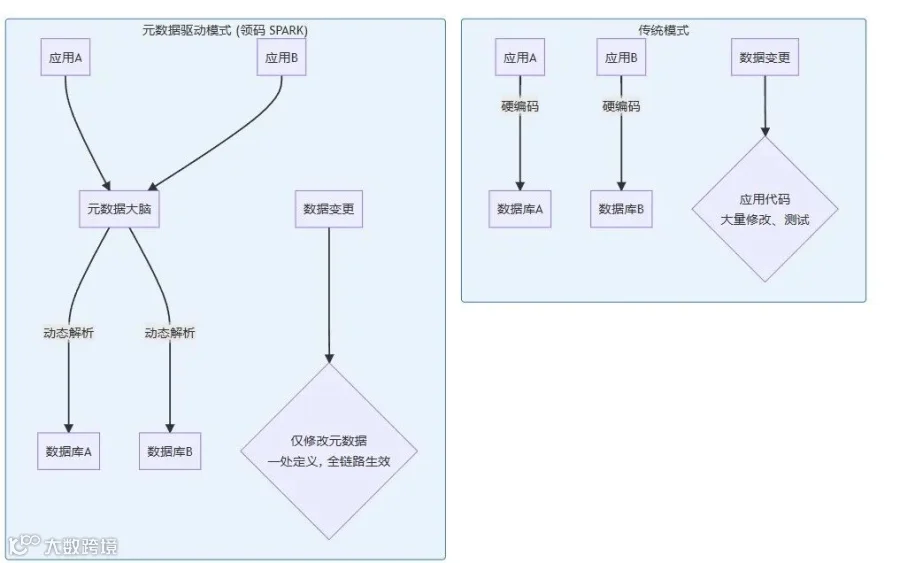
-
全局视野: 平台能够自动发现并纳管从服务器、数据库、数据表到字段级别的完整元数据信息,形成企业的“数据资产地图”。 -
敏捷变更: 当业务需求或数据源结构发生变化时,管理员只需修改元数据定义,而无需改动成千上万行代码。这实现了业务的“无感”升级,大大提升了系统的灵活性和可维护性 。 -
模型构建: 用户可以在平台上直观地进行数据建模,如新建表、创建视图等,将原始数据加工成符合业务需求的标准模型。
-
动态数据规则编排: 平台提供了可视化的拖拽式ETL工作流设计器 。更进一步,其内置的AI策略引擎能够发挥巨大作用: 1、智能映射推荐:在进行数据转换时,AI可以根据字段名、数据类型、数据内容甚至语义信息,自动推荐最可能的字段映射关系,将配置效率提升数倍 。例如,它能理解“cust_name”和“客户姓名”指向同一实体。 2、转换规则生成:对于复杂的数据清洗、格式化需求,AI可以基于样本数据和用户意图,推荐甚至自动生成转换逻辑或代码片段,例如将不规范的日期格式统一为标准格式 。 3、性能动态优化:AI会持续监控ETL任务的运行情况,实时分析性能瓶颈,并动态调整资源配置或执行计划,确保数据处理的高效性 。
-
端到端血缘图谱: 平台能够自动记录数据从源头系统流入,经过每一个ETL节点的清洗、转换、聚合,最终流向目标应用的全过程,并以可视化的图谱形式呈现。 -
AI增强的血缘分析:
PART 04
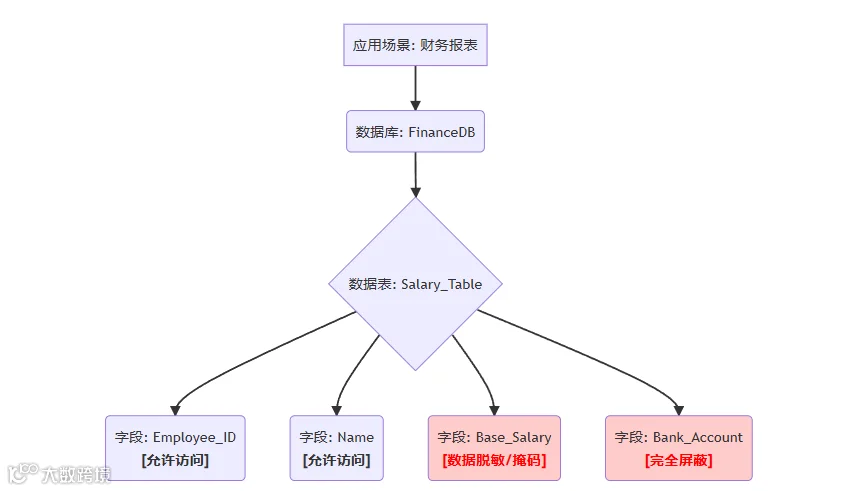
-
数据库/表级访问控制:最基础的权限层,控制用户能否访问特定的数据库或数据表。 -
行级访问控制(Row-Level Security):可以定义规则,使得不同用户在查询同一张表时,只能看到与自己相关的数据行。例如,区域经理只能看到自己所辖区域的销售数据。 -
字段级访问控制(Column-Level Security):这是最精细的管控层。 -
字段屏蔽:可以对特定角色完全隐藏敏感字段,如银行账号、身份证号。 -
数据脱敏/掩码:对于半敏感字段,如薪资、电话号码,可以进行动态脱敏处理(例如,138****1234),在保证数据可用的同时保护隐私。 -
操作审计:平台会详细记录所有数据访问和操作日志,满足合规审计要求,并可通过AI进行异常行为检测,如短时间内大量下载敏感数据等。
PART 05
-
开发敏捷性: 前端开发者或业务系统不再需要关心底层数据库的复杂性,只需调用一个简单的HTTP接口,就能获取所需数据。 -
统一出口: 所有数据请求都通过API网关进行,便于统一进行流量控制、安全认证、监控告警。 -
低代码赋能: 发布的API可以无缝对接到低代码/无代码开发平台(aPaaS),让业务人员也能通过拖拽方式快速构建数据驱动的轻应用 。
-
自引用树: 对于存储在单张表中的树形结构(如员工表中的“ID”与“上级ID”),平台可以自动解析并生成层级关系的API。 -
层级树: 对于多表关联形成的复杂层级,平台也能通过数据建模,将其封装成易于消费的树状结构API。
PART 06
-
“进得来”: 解决了数据来源的广度与深度问题,特别是对信创生态的全面支持,使其成为符合国家战略的可靠选择。 -
“理得顺”: 通过元数据驱动和AI赋能,将繁杂的数据治理工作变得智能、高效且可持续,数据血缘让一切有迹可循。 -
“管得住”: 以精细化的权限管控体系,在数据开放与安全之间取得了完美平衡,为企业数据资产保驾护航。 -
“出得去”: 则通过全API化的服务封装,让数据真正成为驱动业务创新的“燃料”,源源不断地为上层应用提供动力。