

向AI转型的程序员都关注公众号 机器学习AI算法工程
Transformer架构已成为大模型基座,但不同模型的Attention机制、MoE设计、位置编码等关键实现差异显著,理解这些差异对于架构选型和模型优化至关重要。
MIT博士 Sebastian Raschka 整理的 LLM Architecture Gallery 项目,汇集了60+主流大模型的标准化架构图谱,支持任意模型间的架构Diff对比。
项目地址
网站:sebastianraschka.com/llm-architecture-gallery
https://sebastianraschka.com/llm-architecture-gallery/#card-olmo-2-7b
GitHub:github.com/rasbt/llm-architecture-gallery
https://github.com/rasbt/llm-architecture-gallery

收录了哪些模型?
覆盖2024-2026年几乎所有主流模型:
DeepSeek V3/R1/V4 Llama 3/4 Qwen3/3.5/Next GLM-4.5/5 Kimi K2/K2.5/Linear Mistral Small/Large 3 GPT-OSS Gemma 3/4 MiniMax M2/M2.5 Nemotron 3
参数规模从270M到1.6T,全部涵盖。
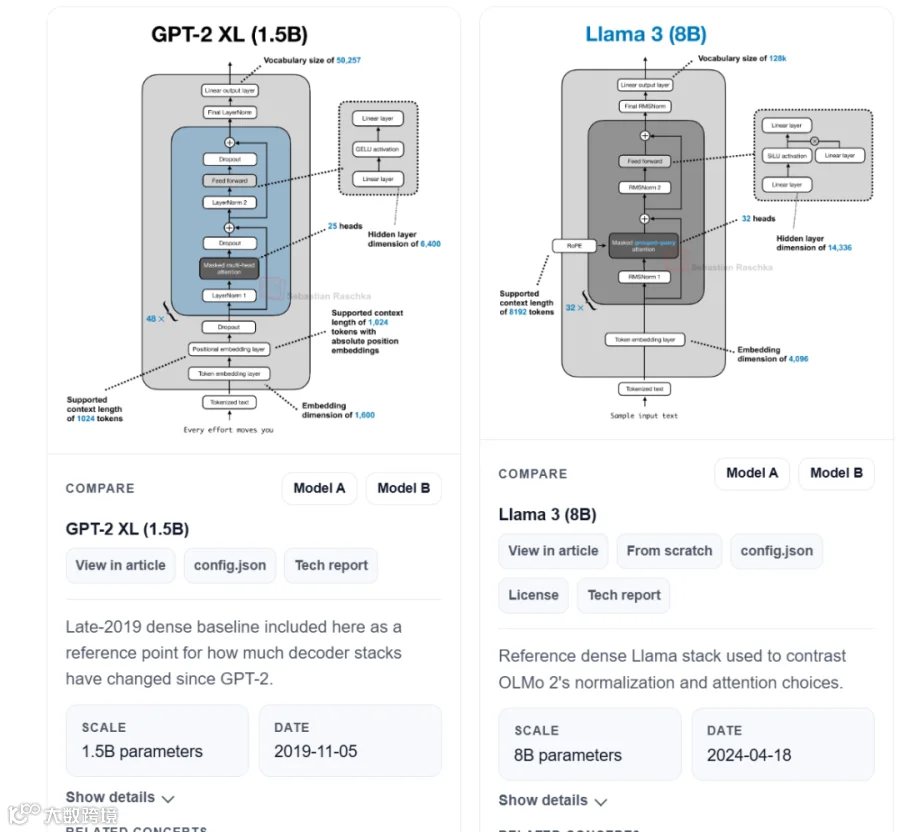
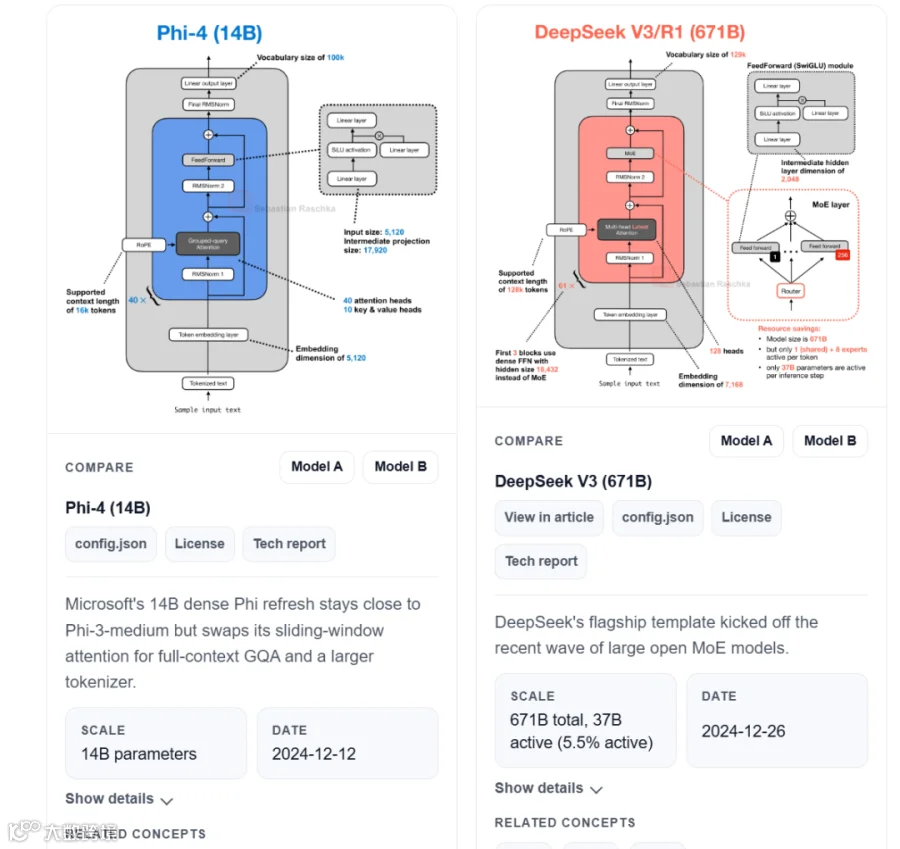
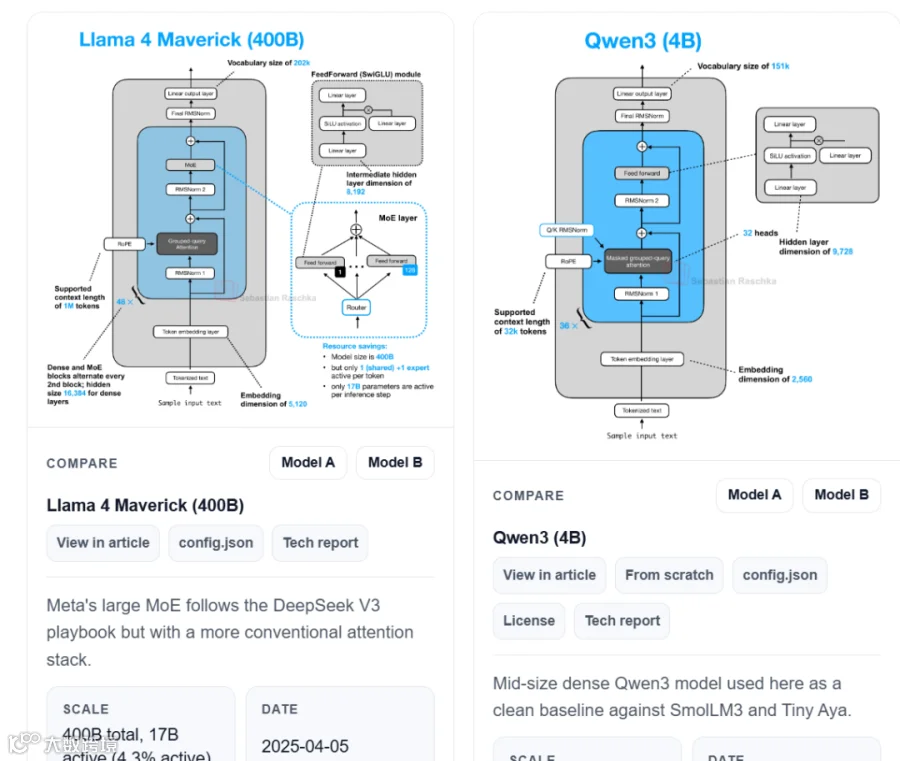
核心功能
1. 架构Diff工具(最实用)
选两个模型,一键对比差异:
-
Attention类型(MHA / GQA / MLA) -
MoE配置(专家数、激活参数、共享专家) -
层数、宽度、KV Cache大小 -
上下文长度、位置编码方案
2. 模型卡片
每个模型都有标准化卡片:参数规模、Decoder类型、Attention机制、KV Cache、发布日期、许可证...
3. 技术概念详解
MHA、GQA、MLA、MoE、SWA、RoPE、NoPE、QK-Norm、MTP...每个概念都有独立解释页面。
关键数据对比
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
架构演进趋势
Attention:MLA才是未来
Attention机制演进路线:
- MHA
→ 传统方案,KV Cache太大(512KB/token) - GQA
→ 分组共享KV,Llama/Qwen在用(128-256KB/token) - MLA
→ DeepSeek首创,KV压缩到68KB/token,极致省显存
MLA是DeepSeek的核心竞争力:同样的671B模型,KV Cache比GQA方案小4-7倍,推理成本大幅降低。
MoE:专家设计各有各的玩法
- DeepSeek V3
: 8路由+1共享专家,37B激活 - Qwen3
: 8路由无共享专家,22B激活 - Llama 4
: 密集层+MoE交替,fewer but larger experts - Nemotron 3
: Transformer+Mamba-2混合,state-space新方向
长上下文:1M token成标配
2026年的模型普遍支持超长上下文:
-
1M上下文:Llama 4、Kimi Linear、Nemotron 3、DeepSeek V4 -
262K上下文:Mistral Large 3、Qwen3 Next、小米MiMo -
技术方案:YaRN、NoPE、稀疏注意力
阅读过本文的人还看了以下文章:
【模型高效部署】tensorrtx 深度解读,yolov11高性能推理实战案例
整理开源的中文大语言模型,以规模较小、可私有化部署、训练成本较低的模型为主
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx
