可重构数据流三十年:下一代计算平台之争
 智东西
智东西 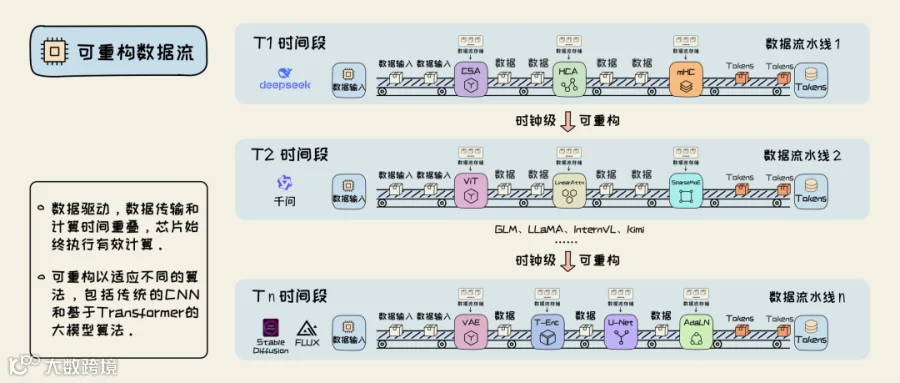
算力革命:可重构数据流架构登上主舞台
历经484天,DeepSeek-V4正式开源发布。其系统级创新将KV Cache扩展至百万级上下文,通过系统压缩机制显著降低存储与计算开销。与此同时,英伟达以200亿美元天价获得Groq LPU推理技术非独家授权并吸纳核心团队,两大事件标志着数据流架构已成为算力革命的核心引擎。
纵观算力发展史,技术路线选择决定产业格局。英特尔凭借x86架构统治PC时代,英伟达以CUDA生态实现十倍性能跃迁领跑AI革命。当Transformer算力需求每两年暴涨750%,单卡算力逼近物理极限,新一代算力平台之争已然开启。
英伟达GTC 2026大会上发布的Groq 3 LPX推理平台,将GPU算力与LPU带宽互补融合。英特尔转向与SambaNova深度合作,国内鲲云科技、清微智能获得大额融资。这些动作共同指向同一技术原点——可重构数据流架构。
技术源头:三十年产业化长跑
可重构数据流架构的诞生(1991-2000)
1991年,陆永青博士在牛津大学提出"改变硬件适配软件"的革命性思路。其团队开发的Occam编译方法首次实现系统化工程方案:用C语言设计硬件,兼顾极致性能与通用性。该技术催生了可重构数据流架构雏形,并在帝国理工学院定制计算实验室持续深化。
与传统架构相比,该技术通过深度流水线与数据流动控制计算,消除数据读写导致的计算空闲。实际应用中可实现10-100倍性能提升,如雪弗龙石油使用Maxeler平台实现钻井效率百倍提升。
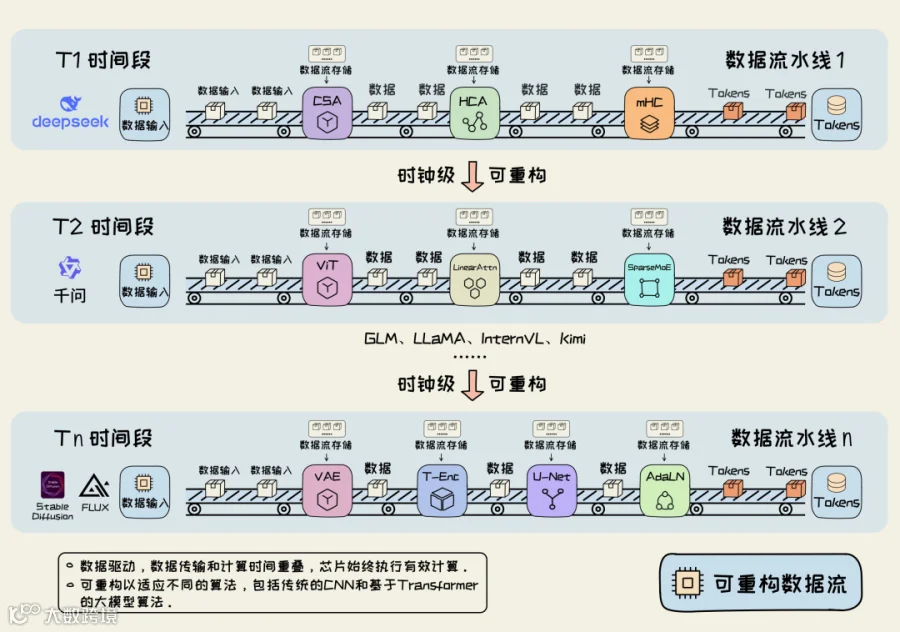
▲数据流计算原理示意图
技术突破:工程化验证关键期(2000-2016)
大西洋两岸学术力量交汇推进技术发展。陆永青与Oskar Mencer合力优化数据流电路,实现每个计算单元满负荷运行。蔡权雄主导的CUBE项目采用64颗FPGA Torus互联结构,Axel集群构建32台异构计算节点,为可重构计算规模化验证奠定工程基础。
牛昕宇作为新一代实验室负责人,推动技术向ASIC演进。其团队在金融计算、生物计算等场景持续验证,最终锚定深度学习赛道。陆永青院士通过600余篇论文构建理论体系,成为可重构计算领域三院院士。

▲陆永青(左)、牛昕宇(右)技术传承
产业格局:三足鼎立的技术路线
三大技术阵营形成(2017年至今)
2017年AlphaGo热潮与谷歌TPU发布加速产业化进程。帝国理工定制计算实验室核心团队创立鲲云科技,同期硅谷诞生Groq与SambaNova,形成全球技术矩阵。

▲可重构数据流架构技术路线图
技术路线竞争焦点
数据流路线:以谷歌TPU和Groq为代表。Groq LPU通过刚性超级流水线实现Llama 2 70B模型推理速度超GPU十倍,延迟降低两个数量级。
可重构路线:SambaNova凭借动态重构能力提升通用性,清华系清微智能专注该领域国产化突破。
可重构数据流路线:鲲云科技集双路线优势。其CAISA3.0芯片测试显示,较同期英伟达产品实现11.6倍芯片利用率提升与134.93倍延迟降低,第二代CAISA430持续保持性能代际优势。

商业化突围:从性能神话到生态构建
DeepSeek-V4的技术突破验证了数据流架构优势——更复杂的计算流水线能更好释放其性能潜力。但规模化落地的关键在于生态构建能力:
鲲云科技CAISA系列芯片已覆盖2000余家生态客户,清微智能TX系列实现规模应用;英伟达整合Groq技术推出NVIDIA Groq 3 LPU平台,英特尔联手SambaNova布局推理市场,全球AI推理赛道进入实质性竞争阶段。

▲NVIDIA Groq 3 LPX机架系统
战略启示:下一代架构的中国机遇
区别于"中国英伟达"的追赶叙事,可重构数据流架构见证了中国团队三十余年技术积淀:从帝国理工实验室学术源头,到鲲云科技产业化落地,中国已在计算架构"无人区"实现同步创新甚至局部领先。
深圳完善的电子产业链、丰富应用场景与长周期创新支持机制,培育了这场"源头创新"的土壤。当算力主阵地发生历史性位移,中国正以自主技术路线参与定义下一代计算架构。
随着DeepSeek-V4等开源项目推进与英伟达Rubin平台落地,可重构数据流架构将加速重塑全球算力格局。