
本文转载自CSDN论坛作者晴天饺子的博客,转载文章仅供学习和研究使用。
RFM - Refresh Management
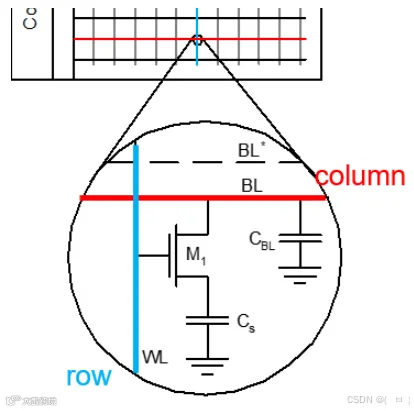
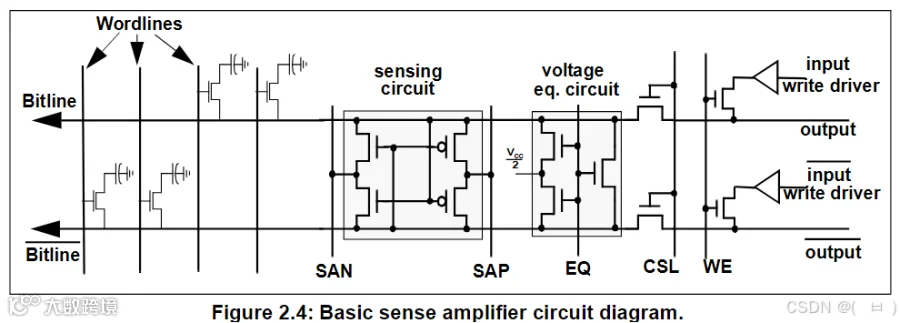
-
关闭所有Row Line - Wordline的供电。 -
所有Bit Line接1/2 VCC供电,充/放电到1/2 VCC,这一步就是Pre-Charge。 -
根据Activate请求,选中对应的Row- Wordline开始供电,对此行所有的奇数/偶数列根据Cell中的数据对Row上的位电容进行充/放电。 -
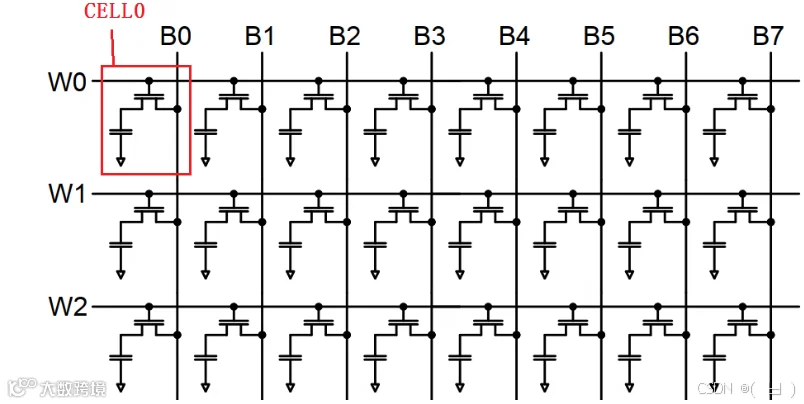
如下图所示:如果CELL0数据为1,Cs电容高于B0 Bit Line上的1/2 VCC,也就是VB0的电平状态为高。反之为低。
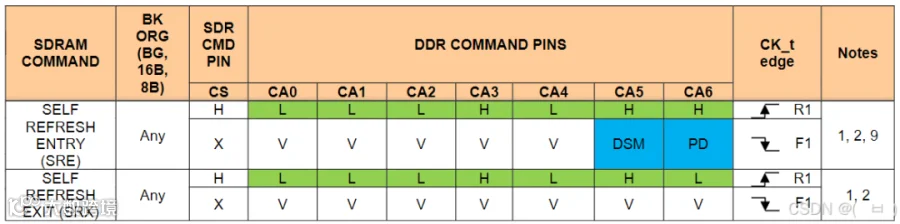
-
H - High Level -
L - Low Level -
X - 可以为任意电平状态,包括浮动电平信号 -
V - 可以为High或者Low电平,但不可以为浮动电平信号 -
DSM - 为High表示自刷新和深度睡眠Deep Sleep同时出现,为异常状态 -
PD - 为High表示自刷新和下电Power Down同时出现,为异常状态
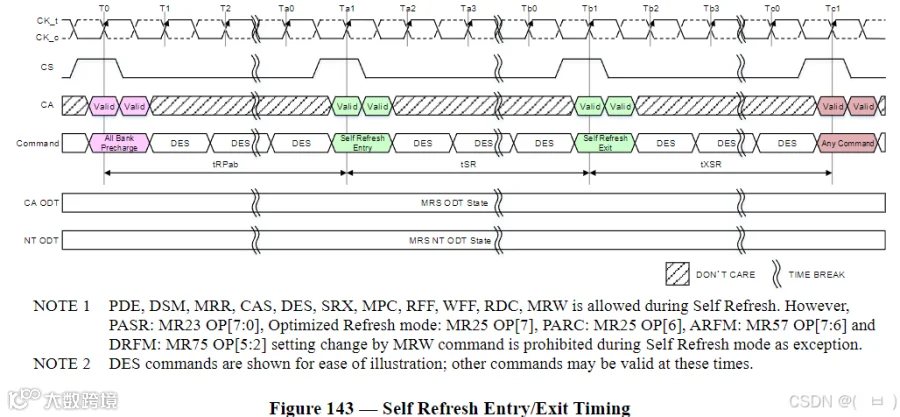
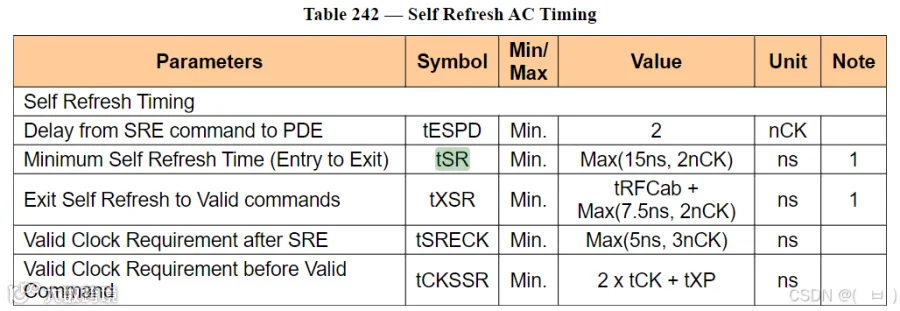
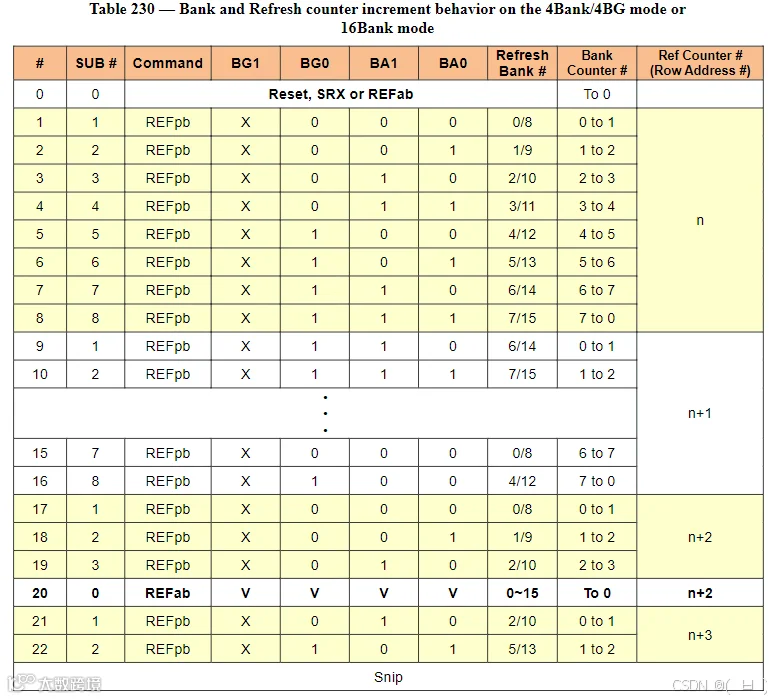
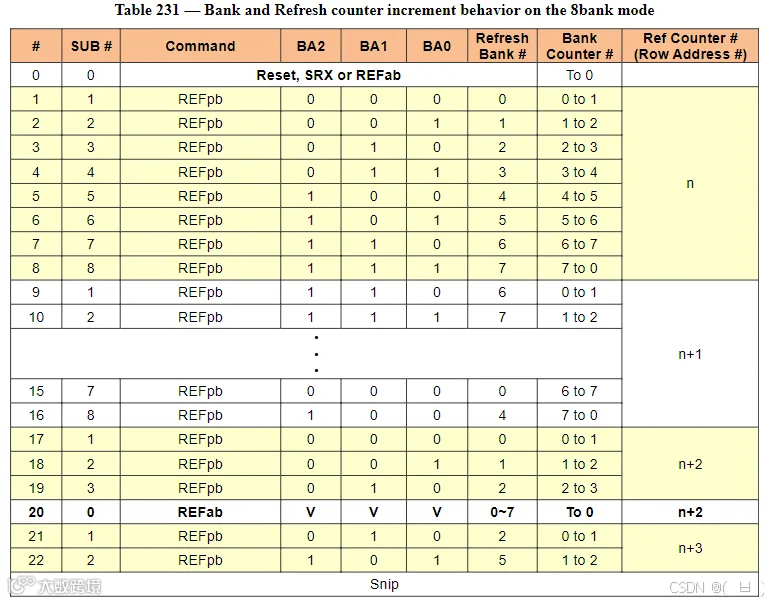
LPDDR4 RFM
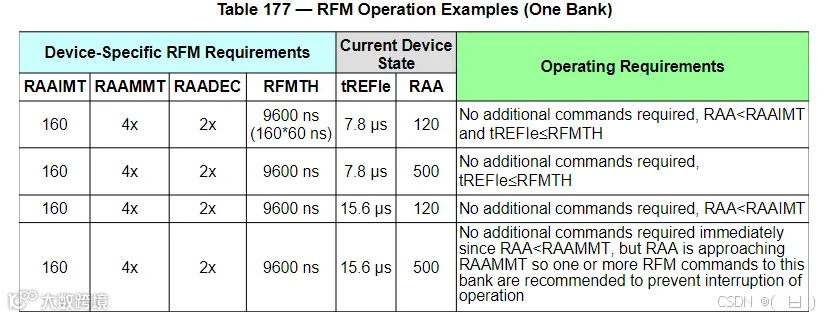
-
RAA - Rolling Accumulated ACT,监控ACTIVE激活指令次数的变量 -
RAAIMT - RAA累计阈值,用于触发一次RFM -
RAAMMT - 累计的RAA计数值倍数信息,用于控制RFM延时执行的最大阈值 -
RAADEC - 累计的RAA计数值倍数信息,用于执行RFM后计算需要减少的RAA计数值 -
tREFIe - 内部有效刷新间隔 -
RFMTH - RFMTH = RAAIMT * tRC(RAS cycle time),不启用RFM场景下,MC需要发出SRE命令的间隔阈值
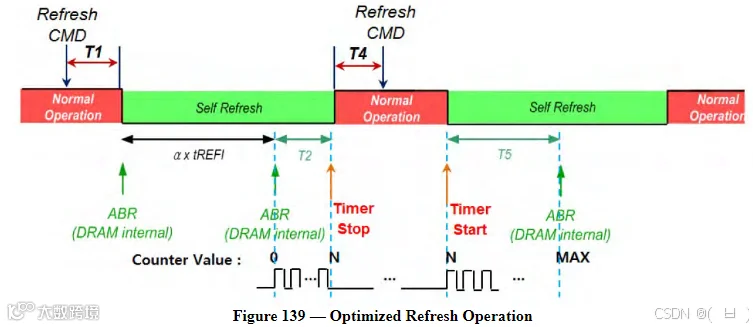
LPDDR5 RFM


Optimized Refresh
往期推荐
|
|||
|
|||
|

牛芯半导体(深圳)有限公司(简称“牛芯半导体”)成立于2020年,聚焦接口IP的开发和授权,并提供相关整体解决方案,致力成为全球领先的IP供应商。
牛芯半导体在主流先进工艺布局SerDes、DDR等中高端接口IP,产品广泛应用于消费电子、网络通信、数据存储、人工智能、汽车电子、医疗电子等领域。
未来,牛芯半导体持续响应IP市场需求,适应不断演进的接口技术和日益拓展的接口互联场景,赋能数智时代下的千行百业。