本期我们将讨论DDR4的DBI数据总线翻转(Data Byte Inversion)特性。
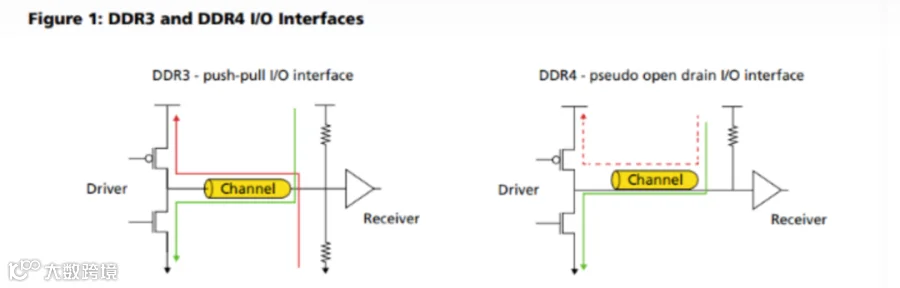
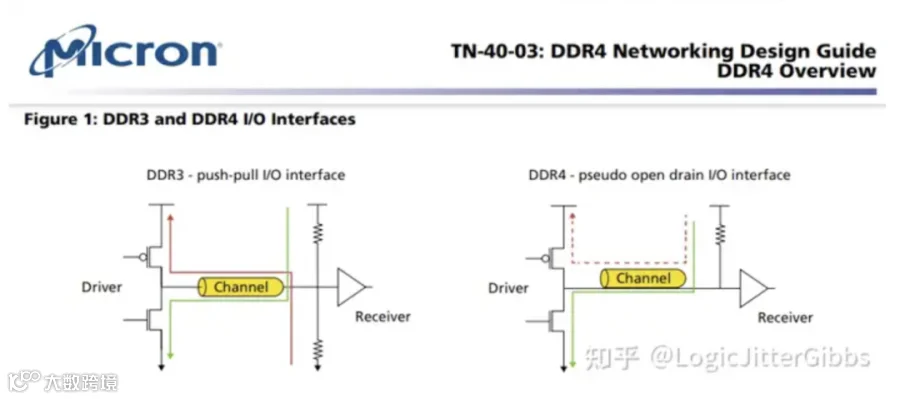
DDR4相较于DDR3的一项重要改进是将数据总线IO更新成伪开漏(POD, pseudo open drain)标准,取代了前代的SSTL标准。在伪开漏电路中,总线驱动高电平时并不会产生功耗,只在驱动低电平时产生功能,因此一项通过尽可能在数据总线上驱动高电平的省电特性DBI由此产生。
在POD中,接收器将信号终结(terminated)到VDD的高电平,而不是像前代一样终结到一半的VDD电压。在低电平状态下,SSTL和POD都有电流消耗,如下图中的绿线所示。实际上,POD可能会消耗略高的电流,因为其终结电压是VDD电压,而SSTL的终结电压仅为VDD电压的一半。这在一定程度上被DDR4稍低的电源电压所抵消,DDR4 VDD电压为1.2V,比DDR3的1.5V显著降低。
这两种驱动选项之间的主要区别在驱动高电平时突显出来。当驱动高电平时,SSTL继续以大约等于驱动低电平时的速率消耗电流,电流方向为接收端的 GND到发送端的VDD/2,如下图中的红线所示,而POD在驱动高电平时不消耗功率,因为收发两端的电压都是VDDQ。
因此,降低DDR4系统功耗的方法是最大化驱动高电平的数量。这时,数据总线反转(DBI)功能就派上了用场。
DBI是数据总线翻转(Data Byte Inversion)的缩写。通过前文我们知道DDR4的POD IO标准电路在驱动高电平时不会消耗功耗,因此发送方会最大化驱动高电平IO的数量,比如一个8bit数据通道上要传输一个0b0001_0011的字节,此时8bit中有5bit为低电平,为了最小化功耗,发送方将数据翻转为0b1110_1100,转为只有3bit低电平。
显然,发送方进行极性翻转后,需要通知接收方此次传输的数据已经经过翻转,不然接收方将接收到错误的数据。DDR4为每个数据通道(8或16比特)引入一个DBI引脚,当发送方将数据翻转为0b1110_1100后,DBI引脚被拉低以指示数据已经经过翻转,接收方需要将数据再次翻转然后使用。
在驱动DRA的SoC这一侧,DBI功能一般由DDR控制器实现,DDR PHY一般不负责此事。写操作时,控制器完成比特翻转后通过DFI DBI信号送给PHY,PHY只负责原样输出DQ和DBI信号给DRAM。读操作时也是同理,PHY在DBI特性上是甩手掌柜。
通过MR5使能或者关闭读写DBI功能,读写DBI功能分别由1比特控制。
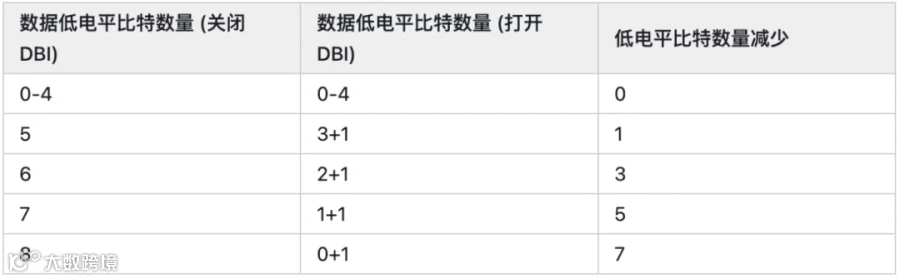
首先,DBI省电多少取决于具体数据间的比特翻转情况,也就是平均每次传输中,DBI能够减少多少次低电平比特传输。以x8器件为例,可能的排列组合如下,表格中的+1表示算上了此时为低电平的DBI引脚:
假设所有比特出现低电平的概率完全随机,那么平均低电平比特数量减少的数学期望为
1/256 x 7 + 8/256 x 5 + 28/256 x 3 + 56/256 x 1 = 187/256 = 0.73
由于完全随机情况下,发生比特跳转的数学期望是4次,因此DBI平均能够减少 0.73/4 = 18.25% 的比特跳转。
援引美光DDR4功耗计算示例中的数据,这大致相当于每个器件节省18.25% 的读写IO动态功耗,大约28mW,占DRAM整体功耗的7%。具体计算的方法以及场景请参考参考文献中的美光DDR4功耗计算PDF。
另外,DBI特性也可以节省SoC端的IO跳转功耗,这个需要另行计算,但笔者个人认为大致和DRAM节省的IO动态功耗相同。
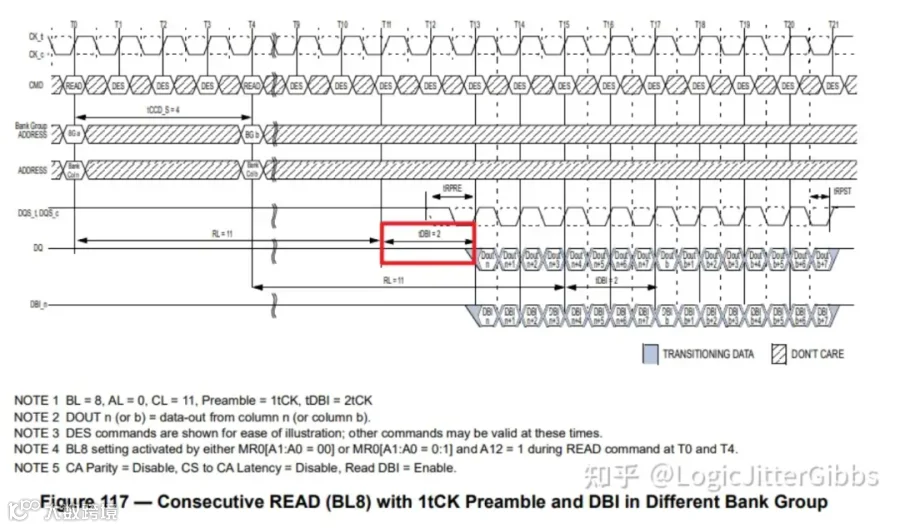
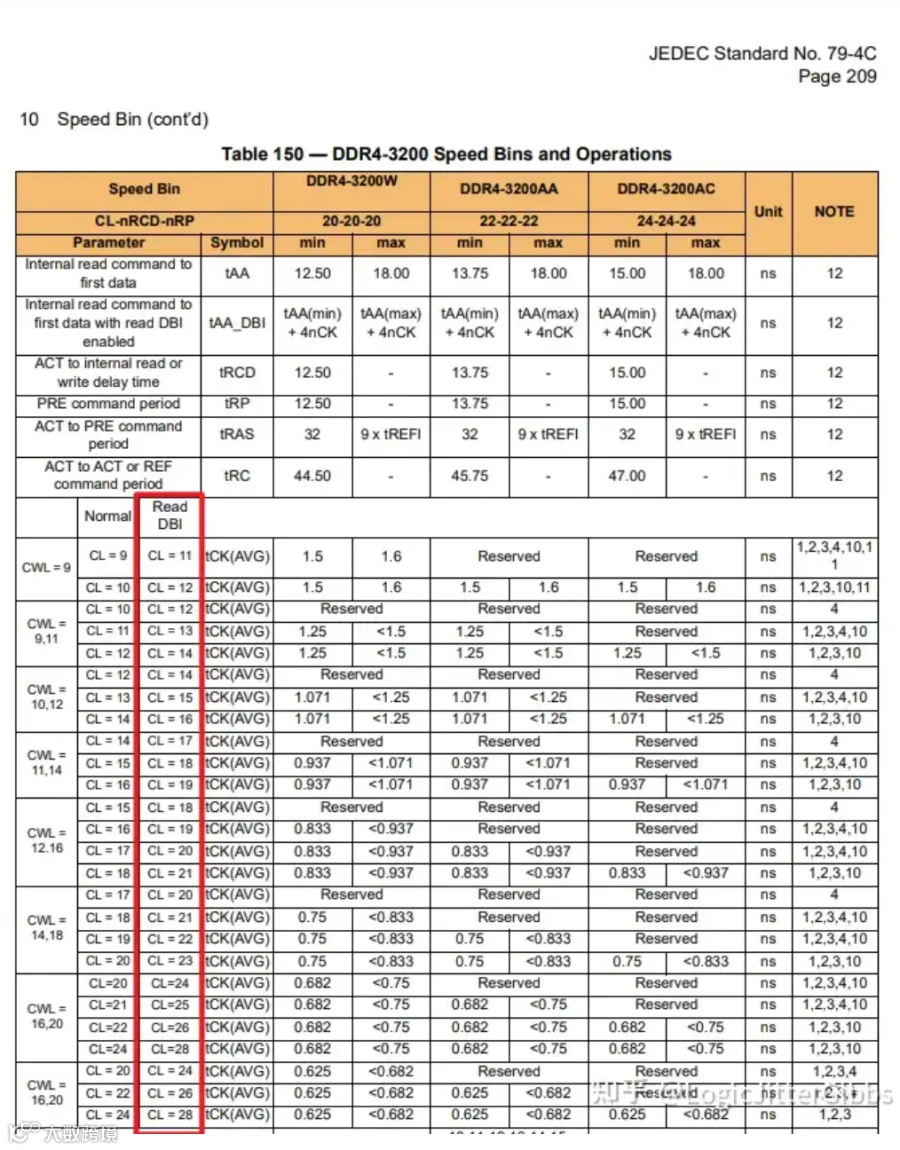
当read DBI使能时,读数据返回会有额外tDBI个时钟周期延迟。Spec中在规定CL的时候,额外规定了read DBI使能时的CL,比正常CL数值大2-4,所以笔者认为这里额外的tDBI是2-4个周期。
事实上,DDR4并没有为DBI新增引脚,而是让他和DM(Data Mask)功能复用同一个引脚。那么在写数据时,DM和DBI只能选择其一。因为DM功能只在写数据时会用到,所以读数据时没有这样的困扰,可以同时使能写DM和读DBI功能。
如果一定要使用写DBI,并且也要使用写Mask功能,也有办法。可以通过控制器的RMW(Read-Modify-Write)功能,先读回数据,修改要写的比特再写回去,来替代DM引脚功能。
写DBI使能时,DDR控制需要增加相应逻辑判断高电平比特数,以及实现比特翻转的逻辑。读DBI时,DDR控制器也需要根据PHY送回来的dfi_dbi_xxx信号,翻转读数据比特逻辑。因此DBI功能会增加DDR控制DFI通路逻辑深度,影响DFI通路时序收敛。
DFI作为一组高频率、超大比特位宽的总线,它的时序收敛一般都是DDR子系统,甚至SoC时序收敛的要点。解决办法也比较直观,在DDR控制器输出输入级增加DFI Pipeline,但这又增加了DDR访问的时延,而DDR时延又是整个系统时延的关键...
本期我们讨论了:
DDR4 DQ IO标准变化
DBI功能的作用
DBI功能原理
DBI省电也不完全免费:DBI特性开销
在一项功耗敏感的应用,可以使用DBI功能来节省DRAM IO动态功耗,节约的功耗大约在50mW量级(DRAM+SoC/PHY),具体节约的功耗大小取决于数据比特跳转的频率。但DBI的开销主要是写方向不能使用DM引脚,读方向会增加2-4个周期延迟。
参考文献:
https://static.sw.cdn.siemens.com/siemens-disw-assets/public/82737/en-US/Siemens-SW-DDR4-board-design-and-signal-WP-82737-C1.pdfhttps://www.mouser.com/pdfDocs/tn_4003_ddr4_network_design_guide.pdf
TN-40-07: Calculating Memory Power for DDR4 SDRAM
牛芯半导体(深圳)有限公司(简称“牛芯半导体”)成立于2020年,聚焦接口IP的开发和授权,并提供相关整体解决方案,致力成为全球领先的IP供应商。
牛芯半导体在主流先进工艺布局SerDes、DDR等中高端接口IP,产品广泛应用于消费电子、网络通信、数据存储、人工智能、汽车电子、医疗电子等领域。
未来,牛芯半导体持续响应IP市场需求,适应不断演进的接口技术和日益拓展的接口互联场景,赋能数智时代下的千行百业。