
本文转载自系统级SIPI设计与仿真,转载文章仅供学习和研究使用。
DDR5的改进
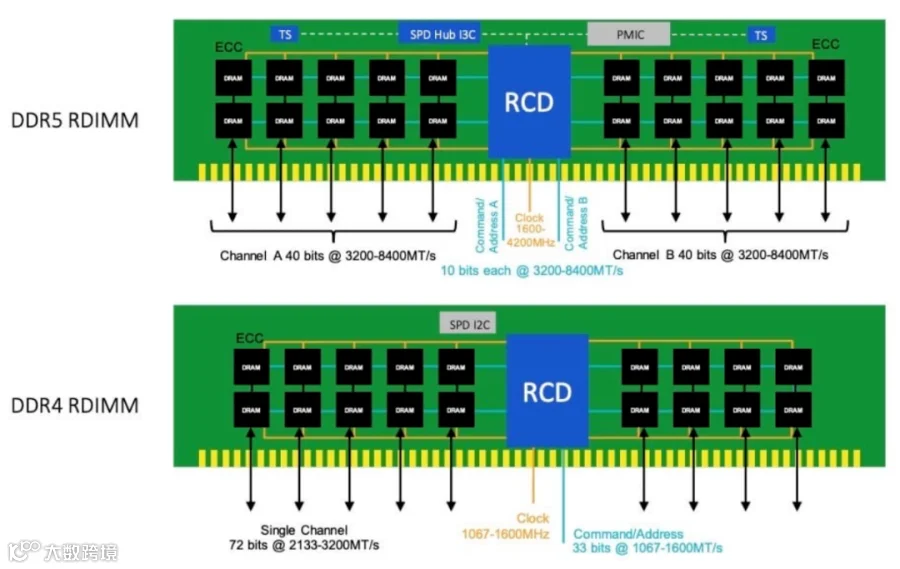
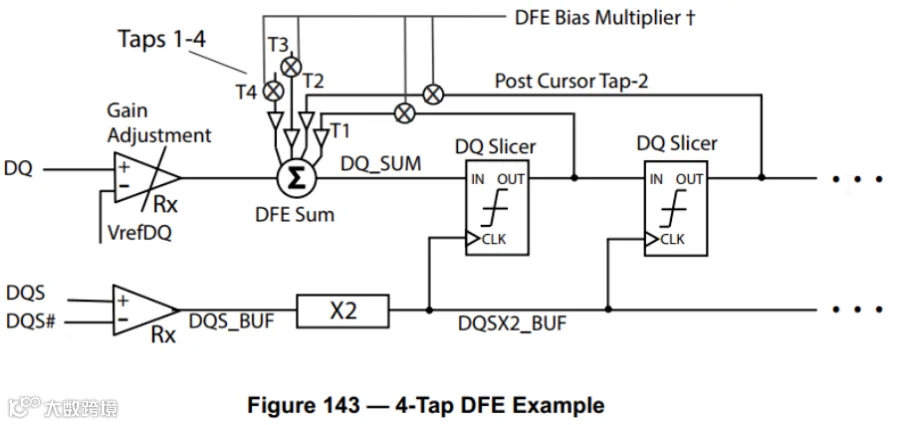
DDR5的均衡
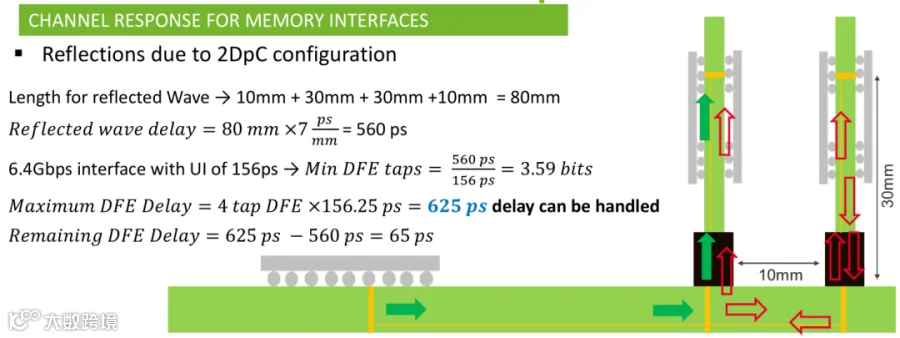
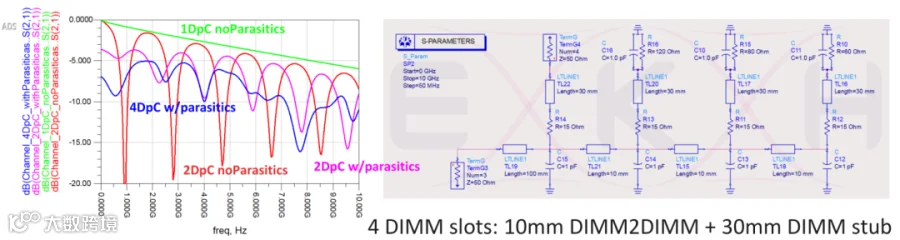
DDR5设置guideline
-
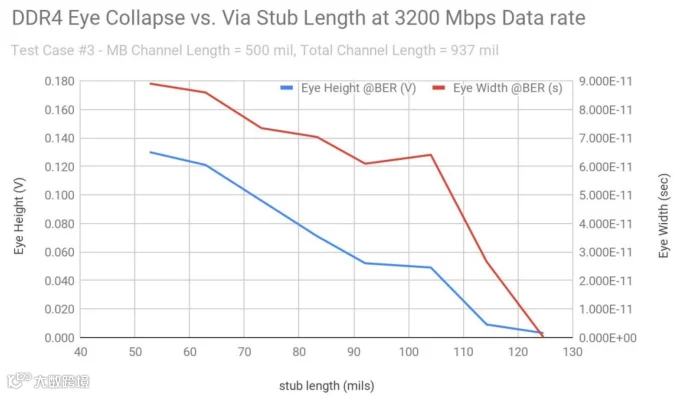
减少过孔Stub:过孔Stub会引入反射和信号失真,应尽量使用盲孔或埋孔来减少过孔Stub的长度。例如在DDR4中,研究表明过孔Stub长度与眼图塌陷密切相关,DDR5数据速率更高,对过孔Stub的控制要求更严格。
-
过孔数量匹配:线路中匹配的过孔数量要相同,因为过孔在Z方向代表额外的长度,不同数量的过孔会导致信号传输延迟不一致。 -
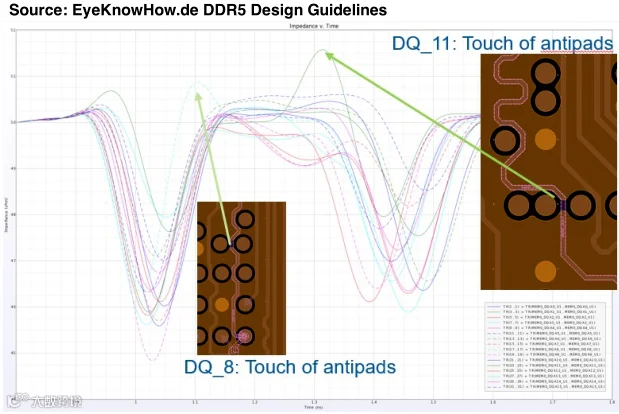
重视返回路径:返回路径对DDR5更为重要,建议使用3D模拟器来考虑其对信号的影响,确保信号有良好的电流返回路径。 下图所示的布线穿过密集过孔趋于,返回路径被打断,在TDR上可以清晰的看到阻抗突变。
-
选择合适材料:使用更好的层压材料,要求损耗因子(Df)小于0.015,以降低信号传输过程中的损耗。同时要确保控制好阻抗失配,避免因阻抗不匹配导致信号反射。 -
通常单端信号如DQ、CMD、ADDR控制40ohm阻抗; -
差分信号如CK_P/N、RDQS_P/N、WCK_P/N控制差分80ohm阻抗。
-
以地为参考:建议所有信号(DQ和CA)都以地为参考,确保信号走线下方有坚实的电流返回路径,减少信号干扰。 -
长度匹配:即使DDR5对字节通道中各比特之间的偏斜有一定限制,仍建议在主板上进行长度匹配,并使用蛇形走线。要注意进行电气长度匹配(以ps为单位),而不是简单的以密耳为单位的走线长度匹配。
-
关注仿真:在设计中使用仿真来关注串扰问题,过孔转换是主要的串扰源。随着电压降低和通道速度增加,眼图会变小,对串扰更加敏感。 -
满足隔离度要求:根据美光DDR5设计指南,建议在高达两倍奈奎斯特频率的情况下,远端串扰功率和不超过-20dB。
-
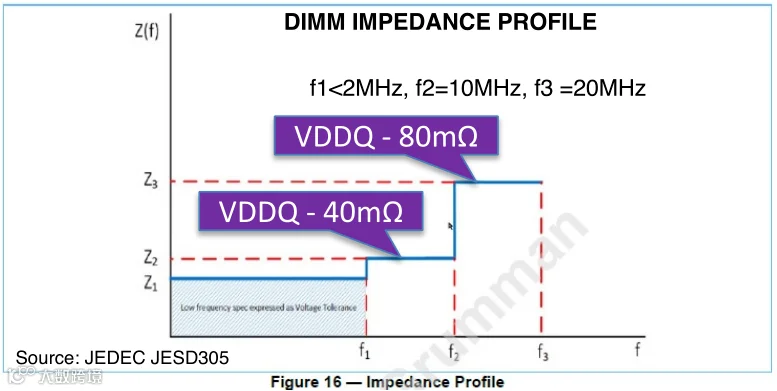
满足不同频率需求:PDN需要满足不同电压和频率下的阻抗要求,以减少电源噪声对信号的干扰。例如在高频情况下,要保证PDN的低阻抗特性,为内存提供干净的电源。
其它内存架构
-
功耗:LPDDR内存专为低功耗设计,在满足移动设备性能需求的同时,最大程度降低能耗,延长电池续航时间。其功耗比DDR内存低很多,如 LPDDR5工作电压1.05V,DDR5为1.1V,更低的电压意味着更低的功耗 。 -
电压:LPDDR工作电压通常低于DDR。早期LPDDR3工作电压1.2V,LPDDR4的工作电压1.1V,LPDDR4X降至0.6V,LPDDR5进一步降低到0.5V;DDR3工作电压1.5V,DDR4为1.2V,DDR5为1.1V。较低的工作电压可减少能耗,还能降低芯片发热。 -
成本:LPDDR内存因应用于移动设备,需在较小芯片面积内集成多种功能,且对功耗控制要求高,制造成本较高;DDR内存面向桌面电脑和服务器等,产量大且技术成熟,成本相对较低。 -
尺寸:LPDDR内存芯片尺寸小,适合移动设备紧凑的内部空间;DDR内存芯片尺寸较大,用于桌面电脑和服务器主板时,空间不是主要限制因素。
-
双倍数据率机制:与DDR一样利用时钟信号的上升沿和下降沿进行数据传输。 -
不断提升的传输速率与带宽:数据传输速率持续攀升,从GDDR5的最高约9Gb/s/pin发展到GDDR6的16Gb/s及以上,带宽相应大幅增加,能够满足GPU对海量纹理、图像数据快速读写的需求。 -
功耗优化:随着技术进步,制造工艺和电源管理技术不断改进,如采用新的电压标准,实现动态电压和频率调整,有效降低了功耗。 -
增强的可靠性技术:集成先进的错误检测和纠正机制,像循环冗余校验(CRC)和奇偶校验等,确保数据在传输和存储过程中的准确性和完整性。
-
电路与架构改进:GDDR6在保持与GDDR5和GDDR5X基础设施兼容性的基础上,增加了双通道(2x16)操作支持,改进了片上终端和输出驱动器特性,提升了信号对称性和与PCB通道的匹配度。 -
沿用与拓展的技术:继承并拓展了从GDDR4到GDDR5的多种技术,如数据总线反转(DBI)降低信号噪声和功耗、判决反馈均衡(DFE)补偿通道损伤、锁相环(PLL)过滤抖动等,还增加了对PLL操作和时钟灵活性的规范扩展。 -
数据预取与操作模式优化:GDDR5X通过双倍数据预取和支持DDR、QDR模式提升数据传输能力,GDDR6在此基础上进一步优化,同时在输出驱动和接口校准等方面进行改进,保障高速稳定的数据传输。
-
3D堆叠技术:HBM采用3D封装技术,将多个DRAM芯片垂直堆叠在一起,利用空间效率,使内存模块能在占用更小空间的同时提供更高性能。 -
硅通孔(TSV)技术:是一种高密度的垂直电气连接方式,能够连接堆叠在一起的多个硅芯片,在HBM中极大地缩短了信号传输距离,减少延迟和功耗,提高了带宽。 -
ubump互连:与TSV相结合,作为将各层芯片连接起来的细微接触点,为数据传输提供了更高的速率和更低的延迟。
-
高带宽:通过宽接口和多通道设计,以及增加引脚数量达到每颗HBM 1024bit内存总线等方式,实现了高数据吞吐量,能满足AI、高性能计算等对大量数据快速处理的需求。 -
低功耗:减少了信号传输路径长度,并优化电路设计,工作电压通常为1.2V或更低,比GDDR显著节能。 -
节省空间:采用2.5D或3D封装,将DRAM芯片垂直堆叠并通过硅中介层连接到处理器,显著减少了PCB面积,适用于空间有限的设备。 -
低延迟:缩短了数据传输路径,再加上优化的电路设计等,有助于提升系统响应速度,让数据的读写更加迅速。
-
人工智能:在AI训练和推理中,尤其是训练过程需要处理海量数据,对内存的带宽和容量要求极高,HBM能够提供强大的支持,如英伟达的A100、H100等AI训练芯片都采用了HBM。 -
高性能计算:超级计算机、数据中心等进行大规模科学计算、数据分析等任务时,HBM可帮助提高计算效率和数据处理速度。 -
图形处理:高端显卡在处理复杂的图形渲染、图像视频编辑等工作时,需要快速传输大量的图形数据,HBM可以满足其高带宽需求。
往期推荐
|
|||
|
|||
|

牛芯半导体(深圳)有限公司(简称“牛芯半导体”)成立于2020年,聚焦接口IP的开发和授权,并提供相关整体解决方案,致力成为全球领先的IP供应商。
牛芯半导体在主流先进工艺布局SerDes、DDR等中高端接口IP,产品广泛应用于消费电子、网络通信、数据存储、人工智能、汽车电子、医疗电子等领域。
未来,牛芯半导体持续响应IP市场需求,适应不断演进的接口技术和日益拓展的接口互联场景,赋能数智时代下的千行百业。