
本文转载自AI内存引擎,转载文章仅供学习和研究使用。
核心目标:
数据链路的本质映射
分层架构:
从物理层到逻辑层的协同设计
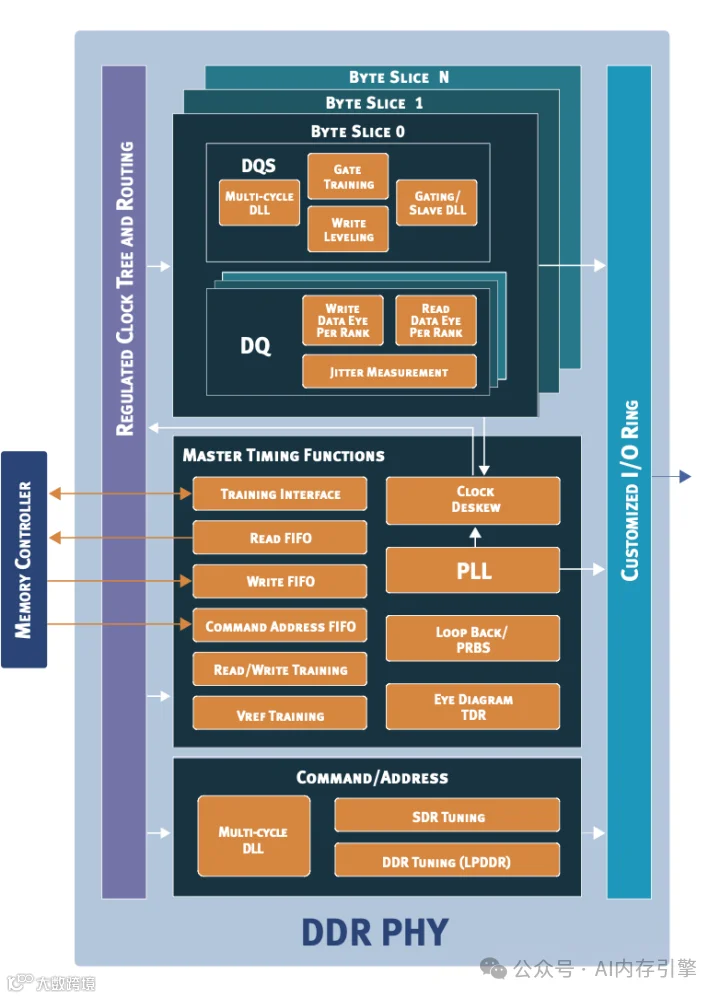
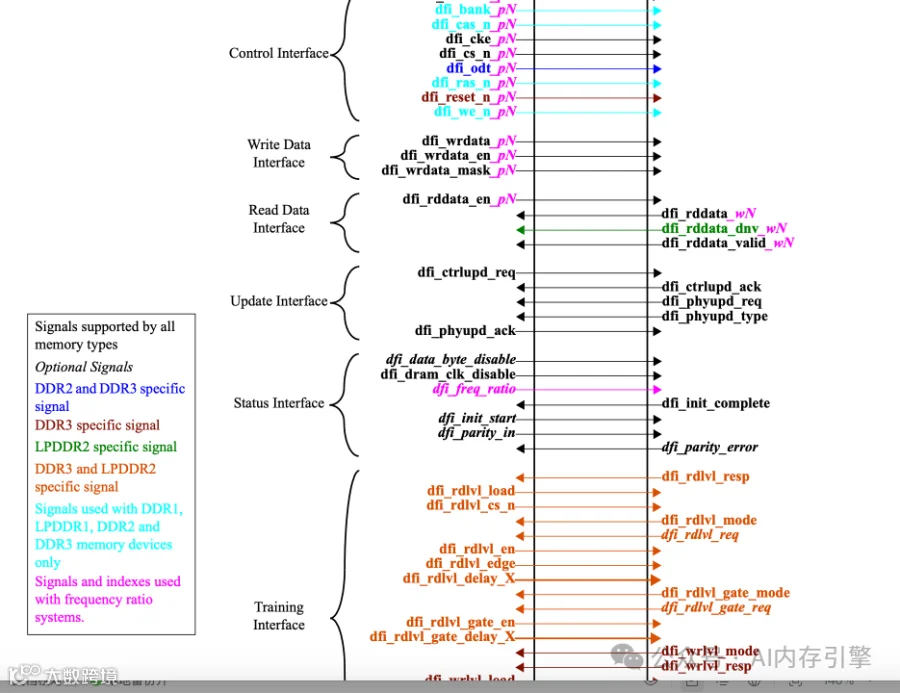
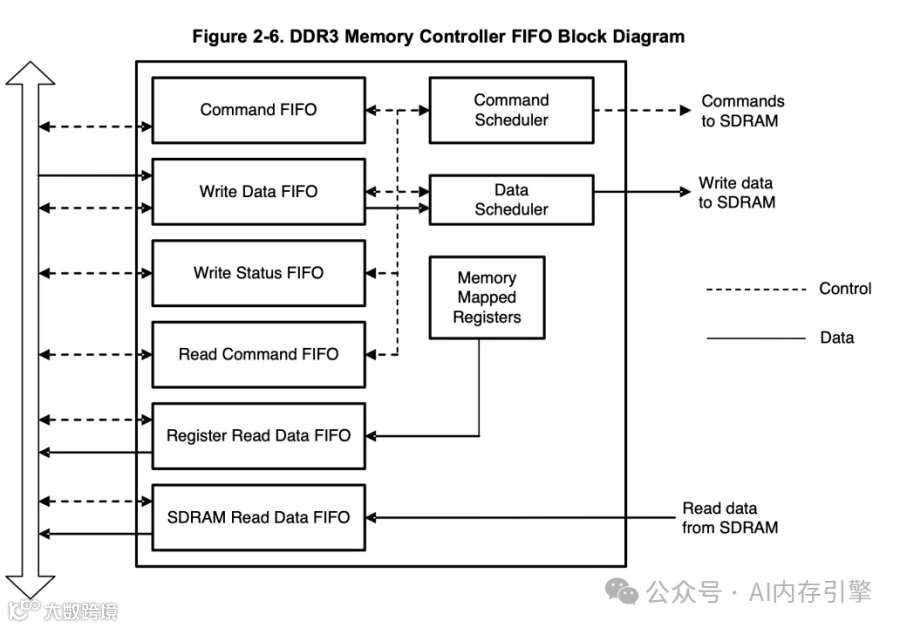
数据流向:
从请求到存储的完整链路
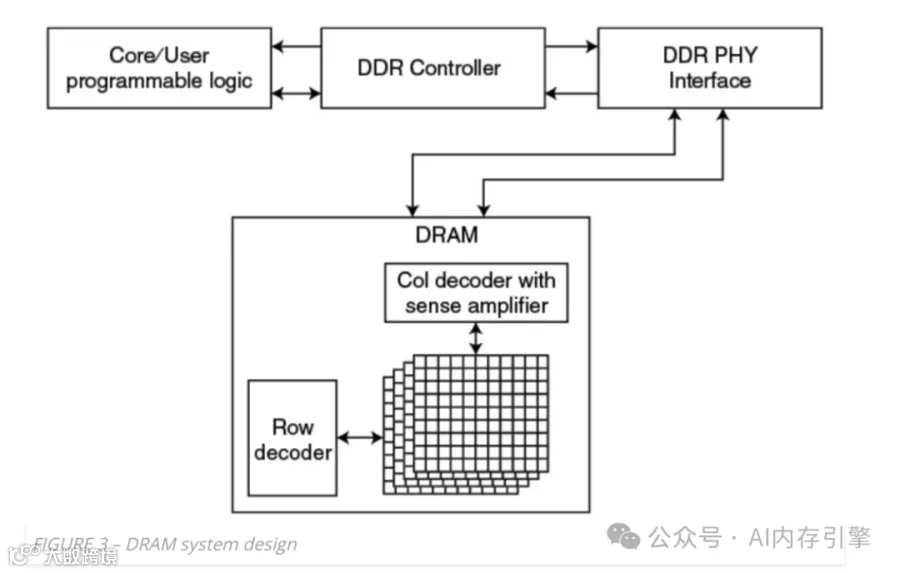
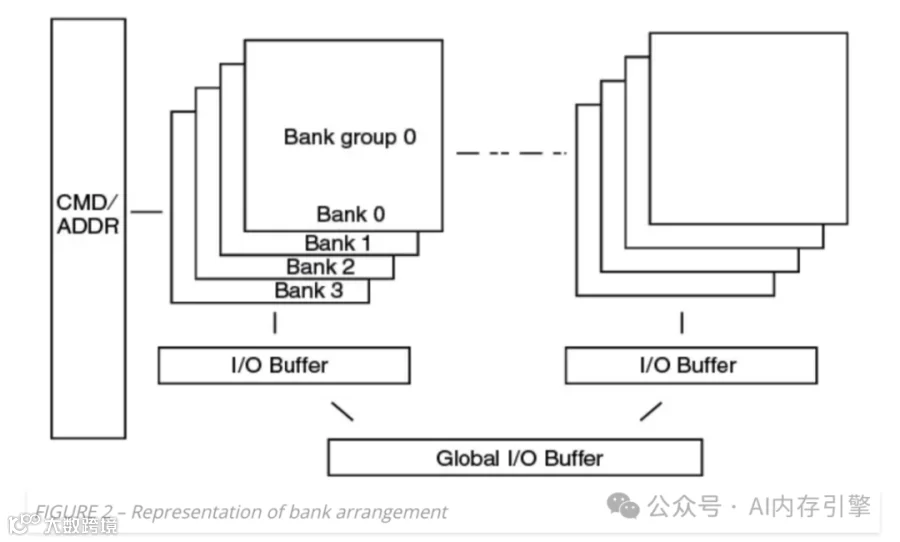
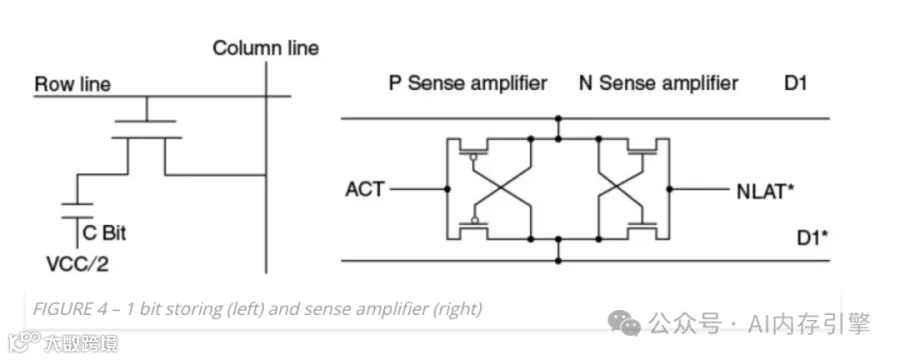
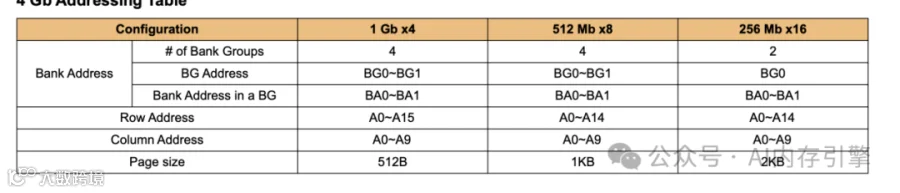
分层架构的设计智慧
往期推荐
|
|||
|
|||
|

牛芯半导体(深圳)股份有限公司(简称“牛芯半导体”)成立于2020年,聚焦提供IP授权与定制、IP代理服务、依托IP技术为客户提供芯片整体解决方案及芯片设计服务。
牛芯半导体在主流先进工艺布局SerDes、DDR等高中端接口IP,产品广泛应用于人工智能、消费电子、网络通信、数据存储、汽车电子、医疗电子等领域。
未来,牛芯半导体持续响应IP市场需求,适应不断演进的接口技术和日益拓展的接口互联场景,赋能数智时代下的千行百业。