
人生关键节点,别光追 “最高分”,更要选 “最适配”!
无数家庭面临同一个灵魂拷问:是该冲刺“够得着的最高分学校”,还是选择“真正适合自己的方向”?

有人选择名校
也有人选择专业
每个人的路都不相同
只有适合自己的才是正解

就像后来我明白的,志愿选择从来不是 “选最高分的选项”,而是 “选能跑通自己人生程序的配置”—— 这跟企业选一体机一个逻辑:与其盲目追 “名校光环” ,不如选适配业务场景,让每一个核心都扎扎实实地服务于自己的需求。
一、志愿填报的启示:最高分 ≠ 最适配
想当年,老师总是叮嘱:“别为名校光环选冷门专业,4 年煎熬换一纸文凭真不值当。”
如今企业选型 AI 推理一体机,同样需警惕:“顶级显卡堆砌 ≠ 业务真需求”。当部署 AI 一体机时,若仅为 “参数面子” 强上高端配置:
❌ 超规格显卡闲置 → 成本虚高
❌ 处理器性能不足 → 并发瓶颈
❌ 内存显存失衡 → 长文本处理卡顿
真正的智慧之选 —— 是像填志愿一样:
✅ 精准匹配当下任务
✅ 预留未来扩展空间

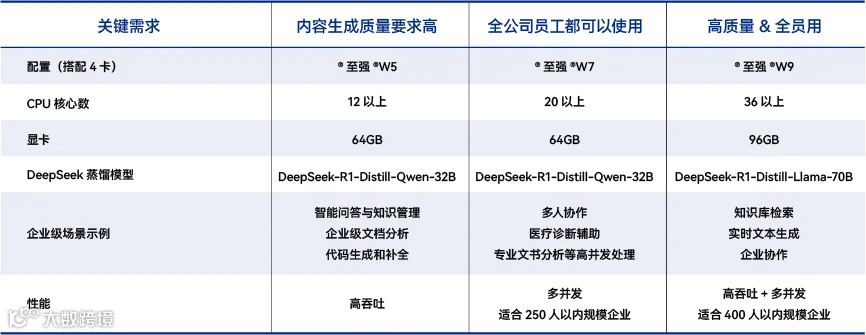
二、基于英特尔® 至强® W 的典型推理一体机解决方案
英特尔® 至强® W 系列处理器,为企业 AI 部署带来 “适配性” 解决方案。采用全大核、大缓存的架构,如 W9 - 3595X 可达 60 核、112.5MB L3 缓存,睿频加速至 4.8GHz 且支持超频,甚至部分后缀为X的型号还可以进一步超频。大核、多核的设计可以很好满足预处理、通讯调度、RAG 等环节的需求,也可以承担部分推理计算任务。就像考生选择 “专业强校” 而非 “综合排名虚高的院校”,至强® W 用核心算力直击企业 AI 部署的 “刚需环节”。
对于推理一体机,英特尔®至强® W 的高扩展性得到了充分发挥。英特尔® 至强® W-3400/3500 系列具有高扩展性,并且支持 8 通道内存,512GB 容量兼顾成本与应用弹性(如运行 DeepSeek - R1 671B 量化版);112 条 PCIe 5.0 通道可灵活配置多块高性能 GPU,既满足大参数模型加载,又能通过扩展吞吐量适应并发需求 —— 恰似志愿填报时预留 “转专业”“辅修” 的可能性,为企业未来业务拓展保留空间。
三、实测数据:适配性带来超预期性能
以部署 DeepSeek - R1 - Distill - Qwen - 32B 蒸馏模型为例,至强® W 平台与显卡搭配展现优势。
显卡配置与模型规模的 “黄金配比”
单块英特尔® 锐炫™ A770 16GB 显卡:可部署 7 - 14B 蒸馏模型;
两块 A770 16GB:可部署 32B 蒸馏模型量化版;
四块 A770 16GB:处理千字上下文时,输出达 200 - 300 Tokens/s(按 1 Token≈0.75-1.8 汉字计,每分钟可输出近 2 万汉字),支持 20 人以上并发请求,覆盖智能问答、文档总结等场景。如果需要满足较长上下文的要求,如翻译、文档总结、代码审查等,吞吐量和并发度会相应减少。
实测数据
我们可以提供一组测试数据做参考。 测试平台采用了英特尔® 至强® W7-3445 处理器,搭配2块或4块英特尔® 锐炫™ A770 16GB 显卡,以及4090D 24GB 显卡。输入序列为1024,输出为512。并发数都取24。
这里以部署DeepSeek-R1-Distill-Qwen-32B 为代表,是因为这个规模的蒸馏模型已经在多数测试项目中超过了 OpenAI-o1-mini,在实践中也证明可以比较高质量地完成长文本处理、代码生成等任务。以审查合同、会议纪要为代表的严肃工作可以交由部署32B 大模型的一体机完成,而不再需要担心隐私泄露甚至违规的风险。
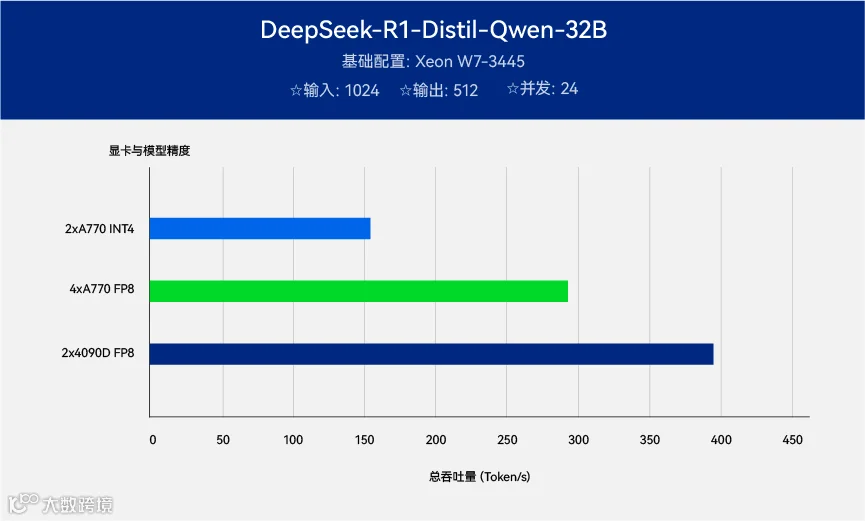
从这组测试数据可以了解到
• 2 块英特尔® 锐炫™ A770 16GB 显卡更适合跑量化版模型。
• 4 块英特尔® 锐炫™ A770 16GB 或2 块4090D 24GB 显卡跑24 并发都很轻松
通过48GB 显存的测试数据做参考,我们还可以发现,4 块英特尔® 锐炫™ A770 的64GB 显存容量在24 并发下还没有充分发挥。这也意味着这个配置允许我们同时承载其他任务,或者说,同时运行几个不同规模的模型。
如果搭配24GB 显存的加速卡,还可以部署70B 蒸馏模型,以支撑长文本生成、创意辅助等高质量的工作。如果不追求模型参数规模,也可以将显存容量优势转化为更高的并发度、更长的上下文(譬如直接输入文档)等价值。另外,较大的显存容量除了可以部署一个较大规模的模型,也可以实现在一体机内部署多个不同规模、 不同特点的中小型模型,以满足不同类型(部门)用户的需求。
处理器与业务复杂度的 “分层匹配”
中小规模模型、部门级应用:选 W5 - 3400/3500 系列,核心数适中,内存带宽大、时延低;
全公司多部门并发需求:选 W7 - 3400/3500 系列,高核数支撑预处理任务,CPU 可分担非实时推理(如文档转化);
高负载场景(RAG 部署、多模型并行):选 W9 系列,强化算力与异构协同能力。
四、实测数据深析
实测数据
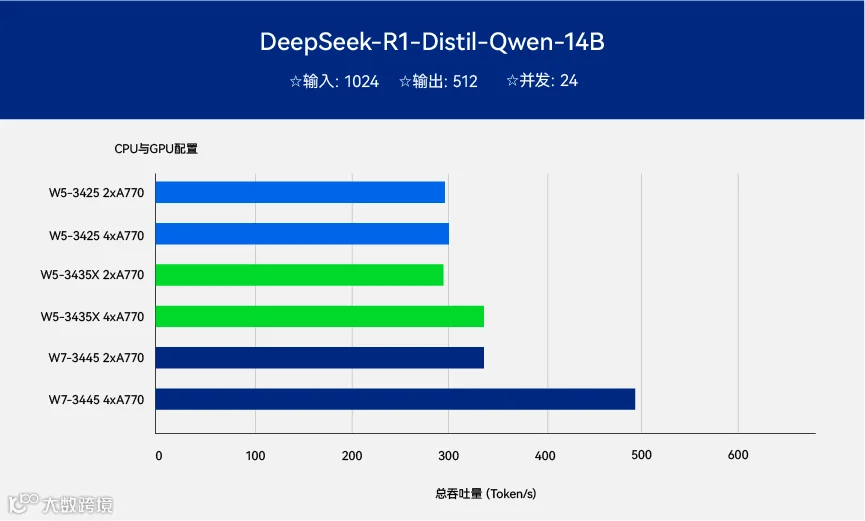
关于处理器性能与显卡配置的匹配关系,我们以规模较小的14B 蒸馏模型为测试对象,以减少对显卡的压力。 测试平台采用了英特尔®至强® W7-3445、W5-3433、W5-3423 处理器,搭配2 块或4 块英特尔® 锐炫™ A770 16GB 显卡。输入序列为1024,输出为512,并发数为24。
四块显卡配置:W7 - 3445 相比 W5 系列,较高的处理器配置可以获得更高的吞吐量。
两块显卡配置:三款处理器配置下的吞吐量差异不大。
五、满血版DeepSeek-R1
对于希望本地部署满血版DeepSeek-R1的用户,英特尔® 至强® 处理器可以搭配大容量内存的优势会显得特别突出。毕竟凑够数百GB 容量显存的门槛实在太高了。对于规模较小的企业、研究团体,尤其是预研阶段,用尽可能低的成本,先验证671B 规模模型的上限是非常务实的
Q4 量化版的 “轻量化部署”
如果要部署最“原汁原味”的FP8精度版本,需要700GB 以上的内存。目前单条96GB DDR5 RDIMM 已经进入市场,单位容量价格与64GB 相比尚可接受,可以构建768GB 的总容量,足够放下671B 模型。对于512GB 内存, 则可以选择配置Q4 量化版本
异构协同
除了利用纯CPU 算力运行, 异构协同的优化工具也已经出现。譬如2025 年春节后最先受到关注的是 KTransformer,可以让GPU 和CPU 共同分担计算任务,将活跃的层安排在GPU 中处理,而将一部分热度低的模型参数放置在容量较大的主内存。目前英特尔开源工具库IPEX-LLM( Intel® Extension for PyTorch LLM )提供的FlashMoE 也实现了英特尔® 至强® 处理器与锐炫® 显卡的异构协同,并且可以发挥前者AMX 指令集的优势。 在IPEX-LLM 的加持下,英特尔® 至强® W 平台可以搭配1 到8 块锐炫显卡,不但可以满足长上下文、长思维链的要求,还可以承担一定的并发性,明显提升了推理一体机的能力上限。
结语:在技术路口,做 “懂适配” 的选择者
从高考志愿到企业 AI 部署,选型的智慧在于找到 “最适配” 的方案。英特尔® 至强® W 平台,以全大核架构、高扩展性与异构协同能力,为企业提供量体裁衣的算力方案。别再盲目追求 “最高分”,精准选择 “最适配”,让每一分算力都成为业务增长的强大助力。

专注AI高算力、深耕边缘新时代
致力绿色节能环保的高科技产品
如需了解更多产品详情,可访问倍联德官