

在图像生成与编辑领域,局部细节崩溃问题一直是困扰创作者和开发者的难题。浙江大学与哈佛医学院联合团队提出的RefineAnything模型,通过创新的Focus-and-Refine策略,实现了对图像指定区域的精准修复,同时严格保持背景不变。这一突破性成果不仅解决了现有模型的三大局限,还在RefineEval基准测试中取得了近乎完美的背景一致性(SSIM 0.9997),为电商产品图修复、广告设计等高精度场景提供了实用解决方案。

相关链接
-
论文:https://arxiv.org/abs/2604.06870 -
源码:https://github.com/limuloo/RefineAnything -
主页:https://limuloo.github.io/RefineAnything
论文介绍

RefineAnything 提出了「Focus-and-Refine(裁剪-放大-修复-粘贴)」策略,反直觉地通过“裁剪放大目标区域”,将有限的分辨率预算集中分配给关键区域,再配合边界一致性损失,实现“高精度局部修复”与“近乎完美背景保留”的双重目标,范式简单但效果极强。
方法概述
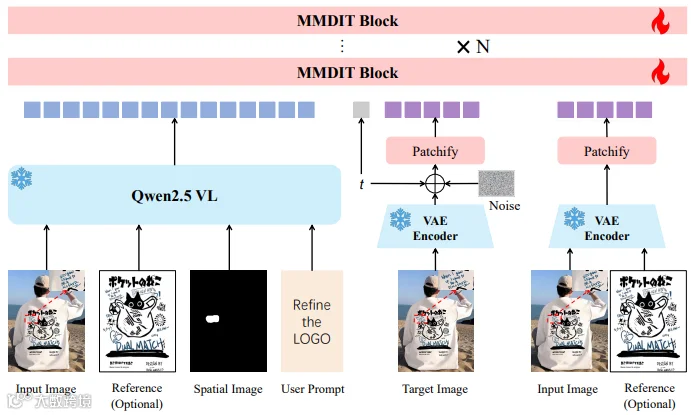
RefineAnything基于Qwen-Image构建,整体采用“多模态编码+扩散去噪”框架,核心围绕四大模块实现精准局部修复,整体简洁高效且针对性解决现有模型痛点。模型通过冻结的Qwen2.5-VL多模态编码器,编码输入图像、参考图(可选)、区域掩码和文本指令,为去噪提供精准引导;冻结VAE将图像映射到潜在空间,兼顾细节保留与算力优化;扩散主干MMDiT Block在多模态与潜在条件下完成目标区域去噪。
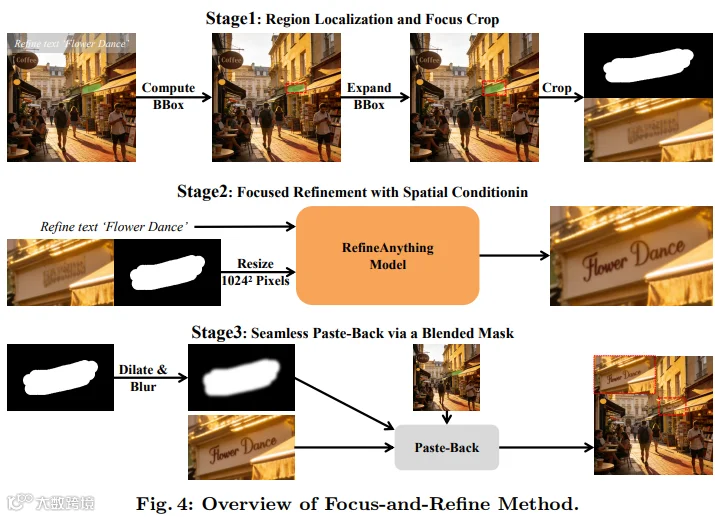
其核心创新是Focus-and-Refine策略,基于“裁剪放大目标区域可提升VAE重建质量”的反直觉观察,通过聚焦(裁剪放大目标区域)、修复(专注局部扩散精修)、粘贴(混合掩码无缝贴回)三步,从机制上保证局部精修与背景不变。同时,设计边界一致性损失减少接缝伪影,提升融合自然度;团队还构建了Refine-30K数据集(20K参考式+10K无参考式)和RefineEval基准,为该任务提供训练与评测支撑,确保模型性能可量化、可验证。
实验结果
定性比较

-
文字修复:针对断笔、错字、乱码等问题,能够一键修正,同时保持字体风格、大小与原图一致,比如将“HOPExcep”修复为“HOPE accept”,将“牛大人台湾火锅他”修复为“牛大人台湾火锅吃到饱”,无任何违和感; -
Logo修复:能够精准还原Logo的图案、文字和颜色,修复过程中不破坏背景纹理,比如修复OKC Thunder Logo、BLMTCH Logo等,边缘干净、细节完整; -
人脸/手部修复:改善面部细节的自然度,修复皮肤纹理、五官细节,同时保留原有面部特征,不出现“换脸”式修复;手部修复则能还原手指结构、皮肤纹理,解决AI生图中常见的手部畸形问题; -
背景保留:所有修复场景中,非编辑区域的背景都纹丝不动,无论是街景、产品背景还是人物背景,都能保持原图的一致性,没有任何意外修改。 
定量比较
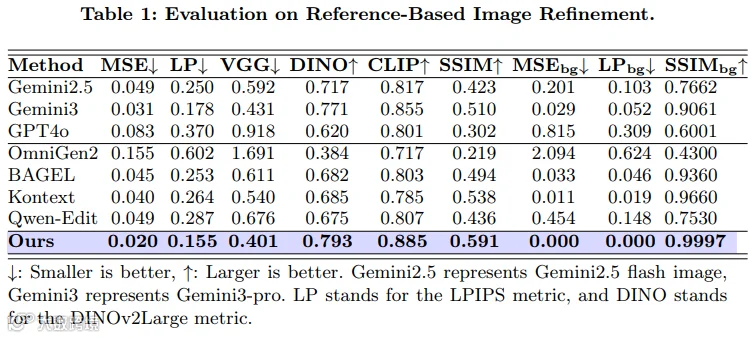
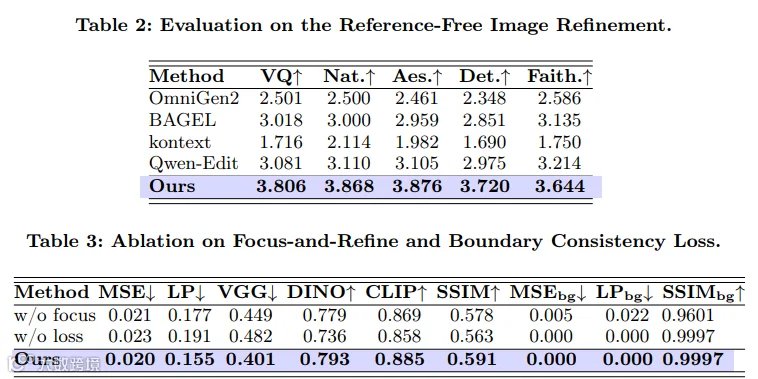
-
区域保真度:修复区域的MSE(均方误差)从基线的0.040降至0.020,降幅达50%;LPIPS(感知相似度)从0.264降至0.155,降幅达41%,意味着修复后的局部细节与真实目标/参考图的相似度大幅提升,细节还原更精准; -
背景一致性:背景区域的SSIM(结构相似性)高达0.9997,近乎完美——要知道,基线模型的背景SSIM仅为0.9660,这意味着RefineAnything彻底解决了背景漂移问题,非编辑区域的像素几乎没有任何变化; -
综合表现:在所有评测指标上均全面超越所有基线模型,无论是参考式还是无参考式修复,都能保持稳定的高性能。
结论
RefineAnything的价值不仅在于提出了一个高性能的模型,更在于它填补了行业刚需空白,为局部图像精修提供了全新的解决方案,其核心亮点可总结为三点:
-
新任务奠基:首次系统定义「区域特定图像精修」任务,明确了任务边界和评价标准,为后续相关研究提供了清晰的方向,解决了工业界“修局部、保背景”的核心痛点; -
范式简单高效:Focus-and-Refine策略思路简洁、通用,不依赖复杂的模型结构,可轻松迁移到各类扩散编辑模型中,降低了高精度局部修复的实现成本; -
落地性极强:直接适配电商修图(产品细节、文字Logo修复)、广告精修(标牌、海报细节优化)、UI设计(界面元素修复)、老照片修复(局部破损修复)、刑侦图像修复等多种实用场景,商业价值突出。
感谢你看到这里,添加小助手 AIGC_Tech 加入官方 AIGC读者交流群,下方扫码加入 AIGC Studio 星球,获取前沿AI应用、AIGC实践教程、大厂面试经验、AI学习路线以及IT类入门到精通学习资料等,欢迎一起交流学习💗~
