
香港科技大学研究团队提出
更有效的新自动语音识别模型
Siri和亚马逊Alexa等受欢迎的语音助手已经向更多用户推出了自己的自动语音识别(ASR)模型。尽管经过了几十年的研发,但ASR模型在一致性和可靠性方面仍存在问题,特别是处于噪声环境中时。香港科技大学(Hong Kong University of Science and Technology)和WeBank的研究人员提出了一个新的框架——语音语义预训练(PSP),可以有效地提高ASR在日常声学环境中的性能,并展示了他们的新模型对合成的高噪声语音数据集的鲁棒性。
他们的研究发表在8月28日的《CAAI人工智能研究》上。“鲁棒性是ASR长期面临的挑战,”香港科技大学计算机科学与工程系的Xueyang Wu说,“我们希望以低成本提高国内ASR系统的鲁棒性。”ASR使用机器学习和其他人工智能技术将语音自动翻译成文本,用于声控系统和转录软件等。但新的以消费者为中心的应用程序越来越多地要求语音识别更好地工作——处理更多的语言和口音,并在视频会议和现场采访等现实生活中表现得更可靠。
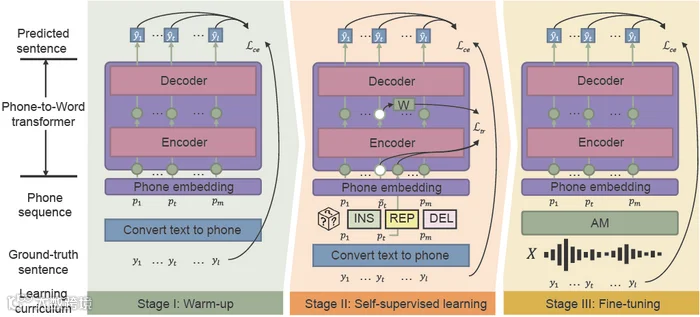
传统上,训练由ASR组成的声学和语言模型需要大量与噪声相关的数据,可能会耗费大量的时间和成本。声学模型(AM)将单词变成“音素”,即一系列基本的声音序列。语言模型(LM)将“音素”解码为自然语言句子,通常有两个步骤:一个快速但相对较弱的LM生成一组候选句,一个强大但计算成本较高的LM从候选句中选择佳的句子。“传统的学习模型对有噪声的声学模型输出表现出较差的鲁棒性,特别是对于发音相同的汉语复音词,”Wu说。“如果第一遍学习模型解码不正确,第二遍就很难弥补。”新提出的PSP框架使错误分类词的恢复变得更加容易。通过预训练一个模型,将AM输出直接翻译成句子以及完整的上下文信息,研究人员可以帮助LM有效地从AM的噪声输出中恢复。PSP框架允许模型通过一种称为噪声感知课程的预训练机制来改进,该机制逐渐引入新技能,从简单开始,逐渐过渡到更复杂的任务。
“我们提出的方法中最关键的部分,噪声感知课程学习,模拟了人类如何从噪声语音中识别句子的机制。”Wu说。热身是第一阶段,在这个阶段,研究人员在干净的“音素”序列上预训练音素转换器,该音素序列从没有标记的文本数据翻译而来。这个阶段对模型进行“预热”,旨在初始化模型参数,将“音素”序列映射到单词。在第二阶段自我监督学习中,转换器从自我监督训练产生的更复杂的数据中学习。最后,用真实世界的语音数据对生成的语音到单词转换器进行微调。研究人员通过实验证明了他们的框架在从工业场景和合成噪声中收集的两个真实汉语会话语音数据集上的有效性。实验结果表明,PSP框架有效地改进了传统的ASR流水线,在两个数据集上分别降低了28.63%和26.38%的相对字符错误率。在接下来的步骤中,研究人员将在大规模非配对数据集上探索更有效的PSP预训练技术。
文章转载至 中科院声学所图书馆
声明:本微信转载文章出于非商业性的教育和科研目的,并不意味着赞同其观点或证实其内容的真实性。版权归原作者所有,如转载稿涉及版权等问题,请立即联系我们,我们会予以更改或删除相关文章,保证您的权利!


