语音识别助手已经风靡各大手机,最为著名的当属苹果公司的Siri。虽然大部分时候Siri都是非常聪明的的,但是当遇到中英文混杂或者其他语种的混杂的时候,你的Siri一瞬间就会变得“不太机灵的亚子”。

Hi Siri, 今天我要做一个关于EP的演讲,Could you please give me some specific topics?

我没听懂你的意思,请再说一遍好吗


(罢了,人也有耳背的时候)
Hi Siri,今天我要做一个关于环境保护的演讲,Could you please give me some specific topics?

环境保护又是指人类有意识地保护自然资源并使其得到合理的利用,防止自然环境受到污染和破坏

(听起来有点那么回事了)
那具体做什么主题比较好?


不清楚您要做什么

(耐心耗尽)
ummm 我现在得去dinner了

地图没有搜索到dinner

(我谢谢宁)

“
多语种语音识别的挑战
上面的情况属于多语种的语音识别(Multi-lingual ASR), 这个Topic历来都是ASR方向的挑战之一,其难点主要包括:
语言和声学变异:不同的语言具有独特的语音特征、口音变化、语调和说话风格。这些变化要求 ASR 系统能够适应不同的声学和语言模式。
语码转换和语言混合:在多语种环境中,人们经常在对话中在语言之间切换,称为语码转换。ASR 系统必须处理这种语言混合并准确转录语音,这需要无缝地理解和区分语言。
跨语言声学建模:ASR 中的声学模型通常是特定于语言的,这使得将其扩展到新语言具有挑战性。使声学模型适应多种语言需要解决声学特征的不匹配问题并创建捕获跨语言语音信息的共享表示。
特定于语言的语法和语言模型:语言模型在 ASR 中预测句子中的单词序列方面发挥着至关重要的作用。为多种语言开发准确的语言模型需要语言专业知识以及每种语言的特定语法、词汇和上下文的知识。
数据可用性和大小:开发高质量的 ASR 系统需要每种语言的大量转录和对齐的语音数据。然而,不同语言的数据可用性可能存在很大差异,某些语言的资源有限。因此,为低资源语言训练有效的模型变得具有挑战性。
“
多语种语音识别的解决方案
为了克服多语种 ASR 的挑战,研究人员和工程师采用了各种策略和技术。主要包括:
多语种数据收集和扩充:获取每种语言的高质量转录和对话语音数据至关重要。应努力收集更多数据,尤其是资源匮乏的语言。数据增强技术还可以通过应用噪声、速度变化或语言混合来人为地增加训练数据的大小。
特定语言的声学建模:开发特定于语言的声学模型有助于捕获每种语言的独特特征。声学模型可以结合域内数据和跨语言数据进行训练,以提高模型处理语言变异性的能力。
语码转换和语言识别:为了处理语码转换和语言混合,可以采用语言识别技术来检测语音中每个点的语言。这有助于 ASR 系统相应地调整其语言模型和声学模型。
跨语言迁移学习:迁移学习技术可用于利用高资源语言的预训练模型,并将其适应低资源语言。通过使用共享表示初始化模型,然后对特定语言进行微调,可以在有限的资源下提高性能。
特定语言的语言模型:开发捕获每种语言的语法、词汇和上下文的特定于语言的语言模型可以提高 ASR 性能。这些模型可以在大型单语言文本数据上进行训练,并使用特定领域或代码交换数据进行增强。
其中多语种的数据的扩充尤为重要,其他的策略和方案基本都是基于有少量的多语种数据才能实施的,多语种的数据是一切的基石。
目前已知的开源的多语种语音识别模型是OpenAI开源的「Whisper」神经网络,据OpenAI声明其在英语语音识别方面已接近人类水平的鲁棒性和准确性。其网络架构如下图所示:
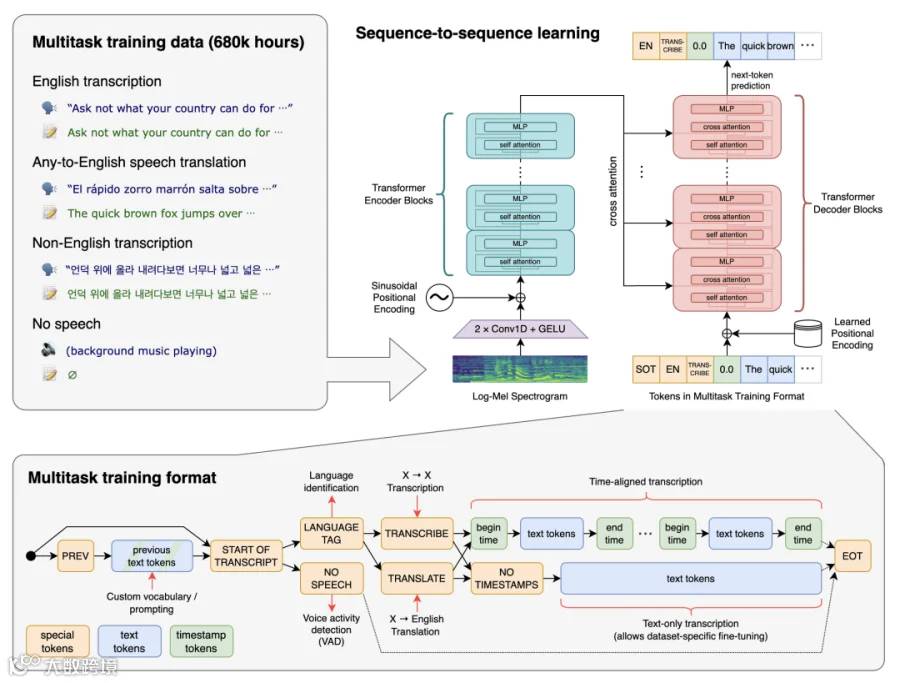
图来自Whisper开源github:
https://github.com/openai/whisper
据悉,Whisper之所以有强大鲁邦的多语种识别功能很大程度上是由于大数据量的训练,Whisper的研究团队通过使用从网络上收集的68万个小时多语音和多任务监督数据,来对其进行训练。训练过程中研究团队发现,使用如此庞大且多样化的数据集可以提高对口音、背景噪音和技术语言的鲁棒性。从Whisper的成功可以看出,多语种数据对于提升ASR系统的多语种识别的重要性。
“
语音识别数据库推荐
海天瑞声基于深厚的语音语言学积累,数据集及数据服务涵盖190+语种/方言,在英、法、德、意、西、日、韩等主流语种基础上,新增了吉尔吉斯语、齐切瓦语、卢旺达语等语种。此外建立了成熟的发音词典构建流程,拥有110+语种/方言的发音词典,拓展了迪维希语、斐济语、马达加斯加语等小语种。
单一的语音识别模型无法满足所有场景的需求。因此海天瑞声还在积极探索并研发多模态融合的语音识别技术,将语音与图像、文本等多种信息相结合,提供更加准确和全面的语义理解能力。
中国中英混识别语音库
Chinese and English Mixed Speech Recognition Corpus
该识别数据在安静办公室环境中完成录制,共有1800位发音人参与,包括871位男性和929位女性,所有参与录音的发音人均经过专业筛选,保证其发音标准,吐字清晰。录音文本来自娱乐搜索领域(音乐、视频)。
产品库编号:King-ASR-700
录音时长:1655.1小时
德国德英混识别语音库
German and English Mixed Speech Recognition Corpus
该识别数据在安静办公室/家居环境中完成录制,共有100位发音人参与,包括58位男性和42位女性,所有参与录音的发音人均经过专业筛选,保证其发音标准,吐字清晰。录音文本覆盖新闻、日常用语等领域。
产品库编号:King-ASR-702
录音时长:211.5小时
美国英语识别语音库-商务会议对话
American English Business Meeting Conversational Speech Recognition Corpus
该识别数据在安静办公室/家居环境中完成录制,共有204位发音人参与,包括93位男性和111位女性,所有参与录音的发音人均经过专业筛选,每3人一组进行商务会议仿真对话录制,录音内容覆盖69个商务话题。
产品库编号:King-ASR-867
录音时长:82.4小时
希腊语识别语音库-对话
Greek Conversational Speech Recognition Corpus
该识别数据在安静办公室/家居环境中完成录制,共有106位发音人参与,包括53位男性和53位女性,所有参与录音的发音人均经过专业筛选,每2人一组进行自由对话录制,录音内容覆盖23个日常话题,如教育、旅行、家庭、宠物等。
产品库编号:King-ASR-885
录音时长:103小时

内容来自:海天瑞声
声明:本文章不代表声学楼赞同其观点或证实其内容的真实性。版权归原作者所有,如转载稿涉及版权等问题,请立即联系我们,我们会予以更改或删除相关文章,保证您的权利!