

补充前节的一个疑问:降噪后声波的能量去那了。有人说是给喇叭吸收转化为热了,这个论述对么?实际上我们是抑制了声源向监测点的辐射,或者说让声波反射回去而不能传播进耳机,也可以说是等效的减小了次级子声源的辐射阻。喇叭此时要抵抗阻尼进行振动,有额外能量的消耗但声能并不是给喇叭吸收。有源降噪的另一个描述为:在传播路径上构建完全的阻抗失配界面,形成全反射。
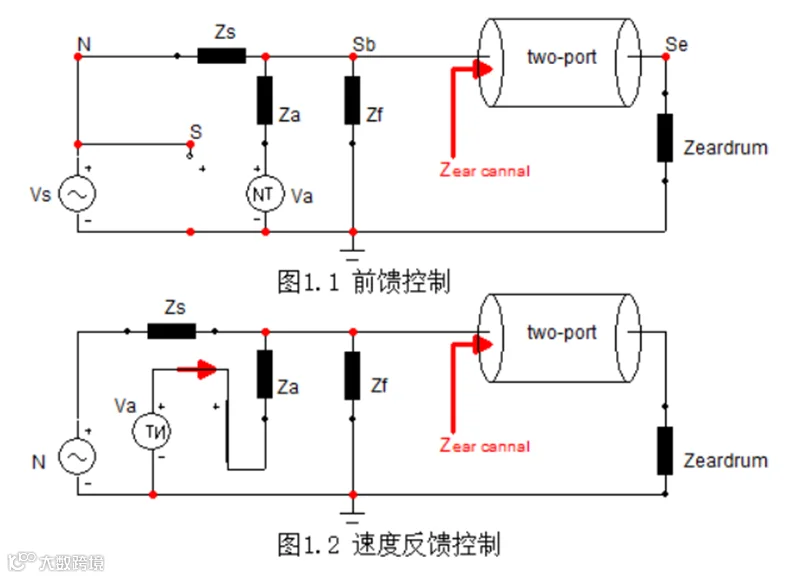
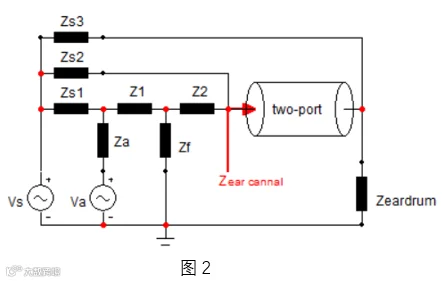
前一节中我们给出的目标是喇叭表面的声阻抗为零时可以实现降噪。但这个条件在宽频带内无源条件下几乎是不可实现的,有源的控制则简单很多。如图1所示给出一类有源框架,我们把Zm替换成三块:Zf:前腔容抗;Za:喇叭表面无源声阻抗;Va:主动声源,它既可以从预测声源而来(图1.1,前馈),也可以通过反馈获得(图1.2,速度反馈)。但实际问题中,我们的声传递路径可能不是单一的,而喇叭表面和耳道入口声压并不相同(如图2所示),问题的复杂性将稍有提高。
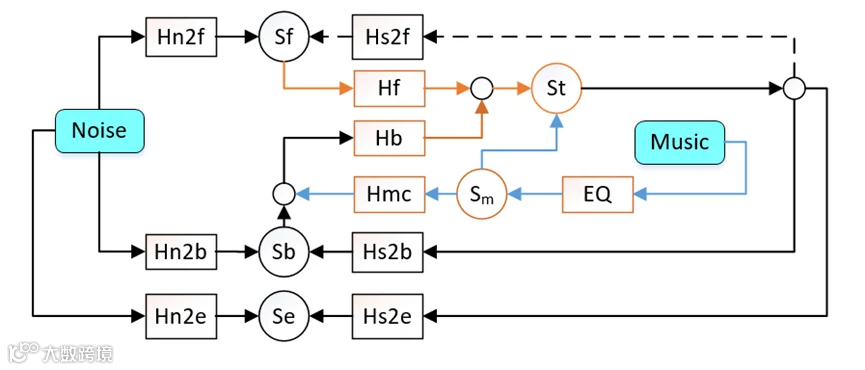
下面给出降噪耳机的一个基础性框架,其中小写下标n代表噪声,f代表前馈,b代表反馈,e代表鼓膜(虚拟麦克风),s代表喇叭;Sf:前馈麦克风信号,Sb:反馈麦克风信号,Se:鼓膜处的声信号,St:给喇叭的电信号。所谓降噪就是剔除音乐信号后Se→0。这个框架下有几个值得注意的问题:
1、噪声源到几颗麦克风的传递函数是准线性时不变的,这意味着不应该出现非线性失真,同时滤波器更新速度应快于系统变化速度;
2、多个噪声源多个方向的噪声源到几颗麦克风的传递函数可能会有差异的,这意味着移动声源降噪难度会加大。
3、振动、咀嚼、风等干扰因素的存在会影响到性能。
4、耳内的参考点有两个:反馈麦克风和鼓膜处虚拟麦克风,这将导致我们的前反馈系统不是简单的降噪量叠加。
针对于如上框架,可以定义三个新的参数:
1、ε ≡ HfHs2f,代表了喇叭发声被前馈麦克风收到形成了一条微弱的反馈回路,如果处理得当,一般满足ε <<1;
2、μ ≡ Hn2e-1Hn2bHs2b-1Hs2e-1,代表反馈麦克风处被动降噪和鼓膜处被动降噪的差异性,一般也满足μ <<1;
3、Gb≡-HbHs2b,表示反馈系统的开环增益,在反馈降噪区间一般是一个较大值。
可以得到反馈麦克风和耳内虚拟麦克风处的声压分别为:
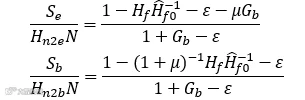
其中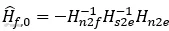 ,是ε→0时前馈系统的理想滤波器。容易发现,这时的前馈和反馈降噪并不能简单的叠加。在开了反馈的条件下,前馈的目标变为:
,是ε→0时前馈系统的理想滤波器。容易发现,这时的前馈和反馈降噪并不能简单的叠加。在开了反馈的条件下,前馈的目标变为: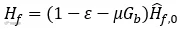 。
。
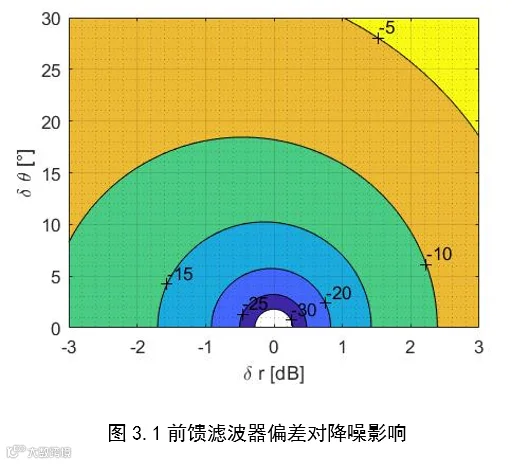
对于前馈系统,当实际滤波器偏离理想滤波器时,降噪性能会急剧下降,图3.1给出了相位和幅值的偏差对降噪性能的影响。
对于反馈系统,开环传递函数同样可以分解为最小相位系统,全通系统及延时,所以我们可以重写为: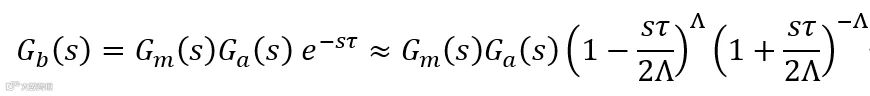
Gm(s)是最小相位系统,由于这是真实的物理,所以必然是带通滤波器,即他的极点数一定是多于零点数,Ga(s)是全通滤波器,在1kHz以下,Ga(s)这项近乎不存在,延时由两部分构成:喇叭到反馈麦克风的传播延时以及数字处理系统AD、数字滤波器及DA的总延时。Λ为自然数,其取值越大,该近似表达式精度越高。当τ=10μs,f=1kHz时,|sτ/2|=0.0314rad=1.8°,所以在1kHz以下的取值可以用总时延除以10us取整获得。波特灵敏度积分满足:
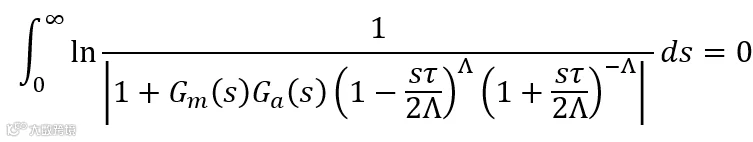
所以反馈降噪带宽和深度就有了限制,这就是我们常说的反馈系统的水床效应。
至此,我们把耳机的降噪原理基本解释清楚,后面的问题就是如何获得和设计滤波器以及如何解决文中所提的该注意的问题。
作者简介
张亚东先生
三省声学创始人,2011年硕士研究生毕业于南京大学近代声学研究所,现南京大学在读博士。曾任江西天键研发负责人,安克创新声学创新研发总监。
多年来,其曾经直接管理的耳机部门包括产品、项目、声学、结构、硬件及软件,作为主要负责人从事的研发还包括音频上行降噪算法、自适应主动降噪算法、计算机辅助设计(声学、跌落、散热等有限元仿真应用于产品开发)。擅长耳机声学仿真与设计,一些专利设计应用于不同品牌耳机产品中,是国内最早一批公开发表耳机仿真设计论文的从业人员之一。
内容来源:三省声学 (全文连载完毕)



