
当语音大语言模型(SLLM)在英语等核心语言中流畅执行语音指令时,日语、法语等非核心语言场景却因语音 - 文本配对的指令跟随数据稀缺与多语言推理能力局限,面临响应质量显著下降的挑战。传统跨语言方法多聚焦文本领域,而 SLLM 以语音信号为输入,仍需适配的推理框架突破这一挑战。
近期,西工大音频语音与语言处理研究组(ASLP@NPU)联合字节跳动、南洋理工大学合作的论文 “Enhancing Non-Core Language Instruction-Following in Speech LLMs via Semi-Implicit Cross-Lingual CoT Reasoning” 被多媒体领域顶级会议 ACM MM 2025 接收。该研究提出了半隐式跨语言语音思维链框架(Semi-Implicit Cross-Lingual Speech Chain-of-Thought, XS-CoT)的推理框架,通过四阶段标记生成实现核心语言的推理能力迁移:目标语言指令转录 → 核心语言(英语)指令翻译 → 核心语言响应生成 → 目标语言响应回译。同时,团队创新提出「句子分割 + 词块保留」半隐式压缩策略,在训练中逐步内化中间推理标记,既完整保留跨语言推理的全局逻辑,又将目标语言响应的首标记生成延迟减少 50% 以上。

论文题目:Enhancing Non-Core Language Instruction-Following in Speech LLMs via Semi-Implicit Cross-Lingual CoT Reasoning
作者列表:薛鸿飞,唐玉峰,刘和鑫,张骏,耿雪龙,谢磊
合作单位:字节跳动,南洋理工大学

论文原文:https://arxiv.org/abs/2504.20835

发表论文截图

扫码直接看论文
背景动机
语音大语言模型(SLLM)在英语等核心语言的语音指令跟随任务中已展现出强劲性能[1,2,3],但在日语、法语等非核心语言场景下,受限于两方面关键挑战:一是非核心语言的语音 - 文本配对的指令跟随数据稀缺,二是 SLLM 的多语言语义推理能力有限(其 LLM 组件预训练主要依赖核心语言数据),导致模型响应质量显著下降。现有 SLLM 在处理非核心语言时,既面临声学模态与非核心语言表征的对齐难题,又因训练数据稀疏性难以支撑复杂推理 —— 例如,直接监督微调(SFT)在日语语音指令跟随任务中,GPT-4 评分较英语场景降低超 50%,直观反映出非核心语言下推理能力的退化。
针对上述痛点,本文提出半隐式跨语言语音思维链框架(XS-CoT),其核心贡献在于:
跨语言推理迁移:通过生成目标非核心语言指令、核心语言指令、核心语言响应、目标非核心语言响应四类令牌,构建从核心语言到非核心语言的推理能力迁移路径,借助核心语言强大的推理基础,解决非核心语言因数据稀缺导致的推理能力不足问题;
动态延迟优化:引入半隐式 CoT 方案,训练中逐步压缩前三类中间推理令牌的局部细节(保留全局推理逻辑),在确保响应质量的同时将目标语言响应的令牌延迟减少 50% 以上,平衡推理质量与实时交互需求;
低资源数据适配:开发专用数据管道,基于 Alpaca 文本数据通过翻译、TTS 合成及 ASR 筛选生成高质量非核心语言指令数据,仅需少量标注样本即可借助核心语言推理能力提升性能,缓解非核心语言数据稀缺困境。
如图 1 所示,在日语指令推理任务中,直接 SFT 输出错误答案 “2019”,而 XS-CoT 通过核心语言推理链得到正确答案 “2016”。实验表明,XS-CoT 在 Qwen2-Audio 和 SALMONN 模型上实现非核心语言响应质量 45% 的提升,半隐式方案在 GPT-4 评分轻微下降的情况下大幅降低推理延迟,为多语言语音交互提供了可扩展的高效解决方案。
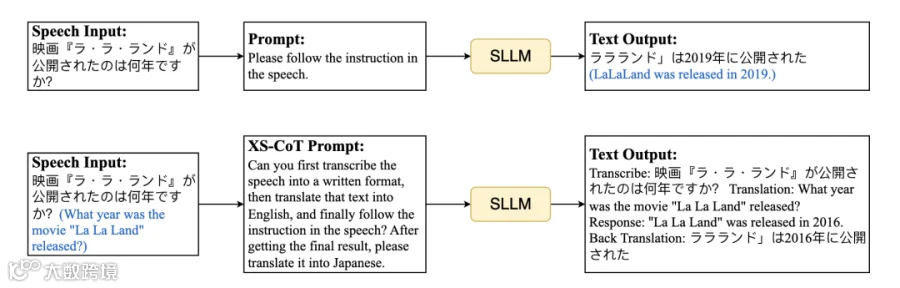
图1 直接 SFT 目标语言 (ja) 输出(上)vs XS-CoT 输出(下)。蓝色文字为辅助理解的翻译,非 SLLM 输出。
提出的方案
XS-CoT:跨语言推理的四令牌生成机制
针对非核心语言语义推理能力薄弱的问题,XS-CoT 框架将语音 - 文本翻译过程嵌入 SLLM 的推理链,通过生成四类顺序令牌实现核心语言推理能力向非核心语言的迁移,其流程如图 2 所示:
目标语言指令令牌:将输入的非核心语言语音指令(如日语语音)转录为对应文本指令,完成语音模态到目标语言文本的对齐 —— 这一步依赖模型对目标语言语音的准确识别,为后续跨语言推理奠定基础。
核心语言指令令牌:将目标语言文本指令翻译为核心语言(如英语),借助 LLM 在核心语言上的强语义推理能力(源于大规模预训练数据),突破非核心语言推理瓶颈。
核心语言响应令牌:基于核心语言指令,利用 LLM 核心语言的强大推理能力生成高质量响应(如英语回答),这一步是跨语言迁移的核心,直接决定推理逻辑的准确性。
目标语言响应令牌:将核心语言响应翻译回目标非核心语言,输出最终结果。
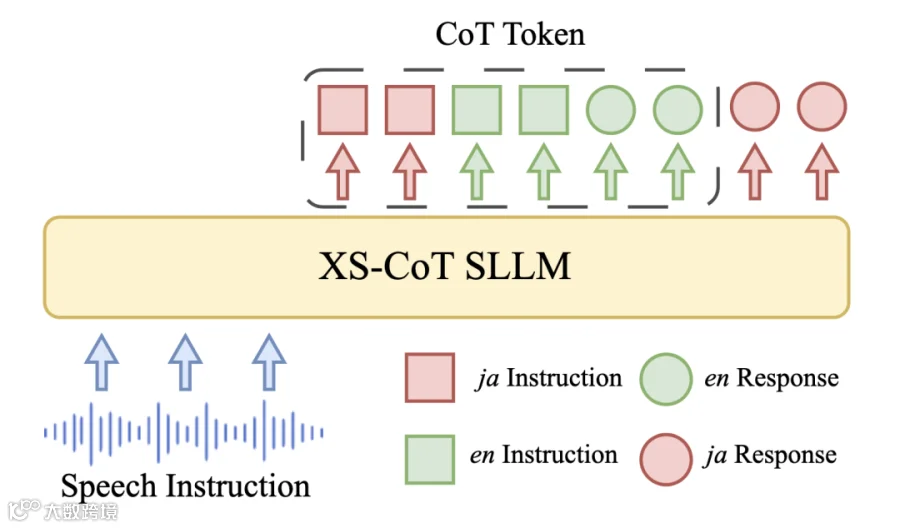
图2 XS-CoT SLLM 框架概览:语音指令作为输入,文本标记作为输出,红色表示目标非核心语言(ja),绿色表示核心语言(en)。
半隐式 CoT:延迟与推理质量的平衡策略
显式 CoT 虽提升响应质量,但生成大量中间令牌导致推理延迟,难以满足实时交互需求。为此,XS-CoT 提出半隐式 CoT 方案,通过 “保留全局逻辑 + 压缩局部细节” 平衡性能与效率,其过程如图3所示:
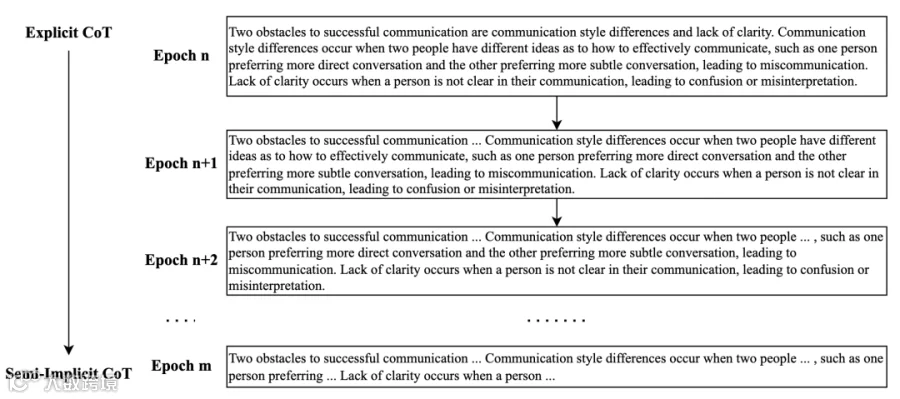
图3 核心语言响应标记中半隐式推理的逐步内化。该过程在训练过程中逐步减少标记数量,从而降低推理延迟。
两级分割与压缩:
句子级分割:将完整推理链按句子拆分,保留全局语义结构;
词组分段压缩:每句仅保留前 k 个核心词组(如 k=3),剩余细节用省略号(...)表示 —— 既维持局部语义的完整性,又减少冗余令牌。
渐进式内化训练:
设推理链包含 x 个句子,训练 epoch n 时,内化前 min (x, n) 句的局部细节;训练至预设 epoch m 时,完全内化所有CoT句子(如 m=7 时,1 epoch 内化目标语言指令令牌,1 epoch 内化核心语言指令令牌,5 epoch 内化核心语言响应令牌);
引入概率 p(如 p=0.1)随机额外内化句子,配合 optimizer reset 策略避免梯度突变,确保训练稳定。
两种内部化策略:
策略 2:仅内部化最长且最复杂的核心语言响应令牌,保留其他令牌完整以强化指令理解。
三阶段训练策略与数据生成方案
为使 SLLM 逐步掌握跨语言推理与高效响应能力,采用三阶段训练策略:
Stage 1:模态对齐:针对 SLLM 不支持的目标语言,用一定目标语言 ASR 数据微调,同时保留部分原始任务数据,确保模型既能准确转录目标语言语音,又不退化原有能力。
Stage 2:XS-CoT 微调:
基于生成的四令牌数据集训练,强化 “转录→翻译→推理→回译” 的完整逻辑;
混入少量原始任务数据维持平衡,使模型在跨语言迁移的同时,不丢失基础语音理解能力。
Stage 3:半隐式 CoT 训练:用压缩后的中间令牌数据微调,使模型适应 “全局逻辑 + 局部省略” 的推理模式,在减少延迟的同时保留核心推理能力。
数据生成方案:
基于 Alpaca 文本数据,通过 “翻译→TTS 合成→ASR 筛选” 生成高质量语音指令数据,仅保留 WER<5% 的样本;
开源日语、德语、法语的 Multilingual-Alpaca-Speech 数据集(https://huggingface.co/datasets/ASLP-lab/Multilingual-Alpaca-Speech),缓解非核心语言数据稀缺问题。
实验
实验设置
核心数据集构成
核心语言(英语):使用 LibriSpeech进行 ASR 基础训练,LibriSpeech (Salmonn) [2] 进行SQA,PR,GR 等其它任务训练,Multilingual Alpaca Speech 用于指令跟随(SI)微调。
非核心语言(日 / 德 / 法):
日语:Reazonspeech + Multilingual Alpaca Speech(30k 样本);
德语 / 法语:Multilingual LibriSpeech + Multilingual Alpaca Speech(各 10k 样本)。
评估指标
使用 AudioBench 基准测试,覆盖 ASR、语音问答(SQA)、指令跟随(SI)等任务;
核心指标:GPT-4 评分(0-100)、生成令牌长度(估算延迟)、WER(语音识别错误率)。
实验结果
单语言(日语)对比 在 SALMONN 和 Qwen2Audio 两种 SLLM 上的实验显示,XS-CoT 框架显著提升非核心语言指令跟随能力:
相比直接监督微调(SFT,e5),XS-CoT(e6)使日语 GPT-4 评分平均提升 45%:SALMONN 在 OpenHermes 测试集从 26.3 分升至 49.4 分,Qwen2Audio 在 OpenHermes 测试集从 39.4 分升至 46.5 分(表 1)。
与级联系统对比:XS-CoT(平均 50.3 分)性能接近 “Whisper ASR + 日语 LLM” 级联系统(53.9 分)(表 2)。
表 1 GPT-4 得分↑和平均生成 token 长度↓的主要结果。“Tin”表示文本指令 token,“Tout”表示文本响应 token,“S”表示语音。()表示 LLM 生成总 token 的平均数量。
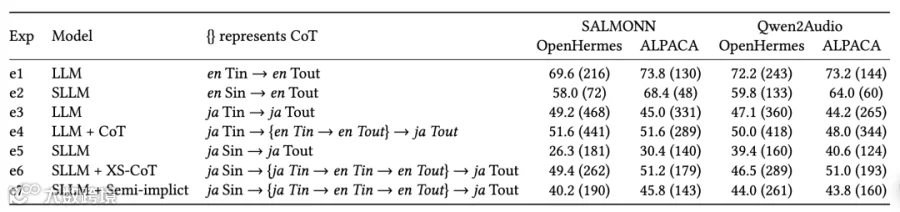
表 2 通过 GPT-4 得分↑和生成的 CoT 标记长度↓测量的潜在推理结果。<> 表示 CoT 标记的数量。注意,CoT 标记不包含目标语言的响应。↑ 以及生成的 CoT 标记长度 ↓。<> 表示 CoT 标记的数量。注意,CoT 标记不包含目标语言的响应。
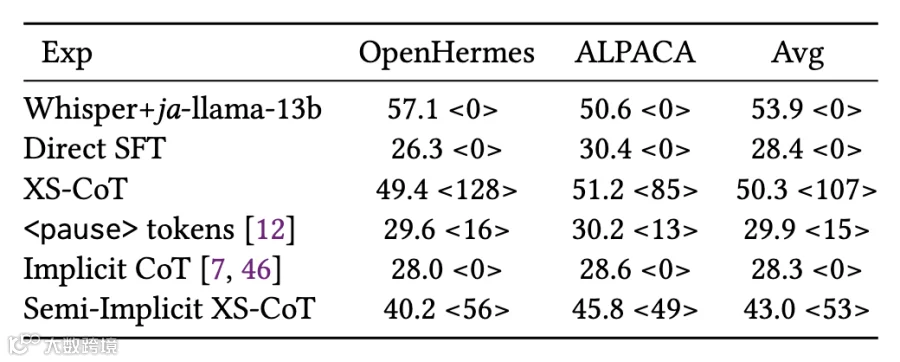
半隐式方案通过压缩中间令牌,在延迟与性能间实现 trade-off:
延迟优化:CoT 令牌数从 107(显式 XS-CoT)降至 53(半隐式),减少 50%;目标语言响应的首令牌延迟降低超 50%(表 3)。
性能保留:GPT-4 评分相对下降 14.5%(从 50.3 分降至 43.0 分),远优于完全隐式 CoT(28.3 分)和<pause>令牌方法(29.9 分),证明 “保留全局逻辑” 的必要性(表 3)。
多语言扩展性验证 在德语、法语、日语上的实验验证了 XS-CoT 的跨语言通用性,如表 3 所示,XS-CoT 训练后 GPT-4 评分平均提升 19 分:
德语 OpenHermes 任务从 31.2 分提升至 51.2 分,法语 ALPACA 任务从 35.6 分提升至 52.4 分;
半隐式方法将中间令牌数从 137 减少至 30,实现 平衡。
表 3 GPT-4 得分 ↑ 衡量的多语言能力结果。<> 表示 CoT 标记 ↓ 的数量,包含前三类中间标记。超参数 𝑘 设置为 3。

超参数 k 的影响 k(保留词组数)越大,性能越好但令牌数越多,如图 4 所示:k=7 时 GPT-4 分数最高,但 k=3 时在分数下降 10% 的情况下,令牌数减少 60%,更适合延迟要求场景。
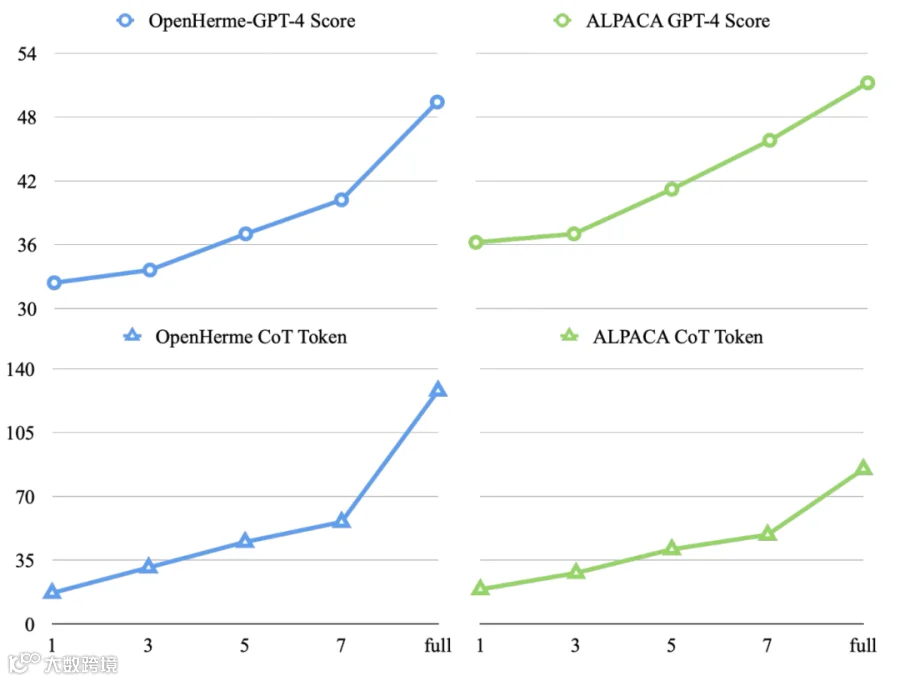
图 4 超参数𝑘对半隐式CoT方法的影响。横轴表示不同的𝑘值(1、3、5、7和完整推理链)
图5 呈现了对半隐式 CoT 的定性分析结果,显示其可保留全局推理逻辑,有效推断被压缩的局部信息(如补全 IPv4 与 IPv6 区别的省略内容);但在非核心语言场景下,复杂句式易导致输出类似,多样性欠佳。

图 5 半隐式核心语言响应标记与目标语言响应标记的比较。蓝色单词是为了方便理解而进行的翻译,并非 SLLM 的输出。
参考文献
[1] Y. Chu, J. Xu, Q. Yang, H. Wei, X. Wei, Z. Guo, Y. Leng, Y. Lv, J. He, J. Lin, C. Zhou, and J. Zhou, “Qwen2-audio technical report,” arXiv preprint arXiv:2407.10759, 2024.
[2] Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, and Chao Zhang. 2024. SALMONN: Towards Generic Hearing Abilities for Large Language Models. In ICLR.
[3] S. Hu, L. Zhou, S. Liu, S. Chen, L. Meng, H. Hao, J. Pan, X. Liu, J. Li, S. Sivasankaran, L. Liu, and F. Wei, “Wavllm: Towards robust and adaptive speech large language model,” in EMNLP. Association for Computational Linguistics, 2024, pp. 4552–4572.
内容来源:音频语音与语言处理研究组
:本文章不代表声学楼赞同其观点或证实其内容的真实性。版权归原作者所有,如转载稿涉及版权等问题,请立即联系我们,我们会予以更改或删除相关文章,保证您的权利!

