

一、简介
1.1 什么是强制对齐(Forced Alignment)
强制对齐是将转录文本与相应的音频信号对齐以确定单词、子词或音素等单元的时间边界的过程,也叫对齐。 下图可以直观看到对齐的过程。如图1所示,这是使用praat人工给音频中每个字和音素的时间标注。
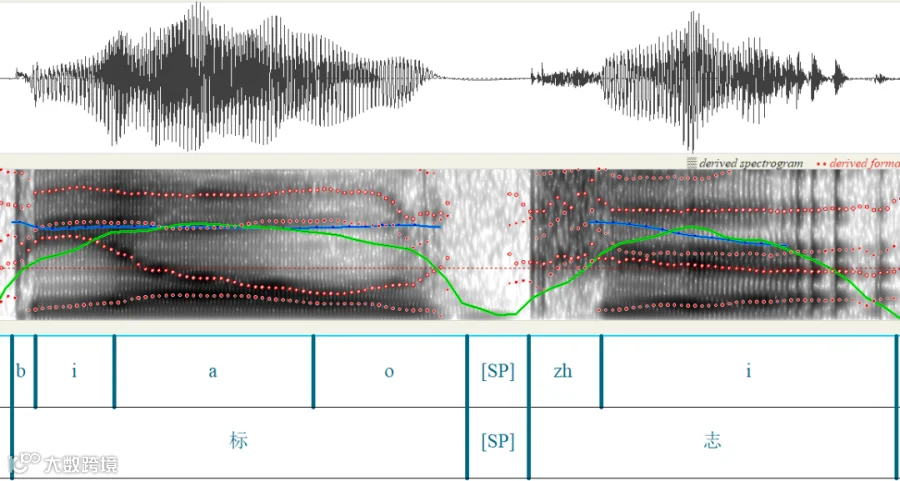
图1 使用praat人工对齐
如果将这个过程形式化,假设 是声学特征的序列T是时间, 是所有可能的词序列 , 目的是找到最合适的一个词序列 , 在下图中,最佳时间对齐序列是 序列,因为它和声学特征完美地对齐了。其对齐过程的数学表示为
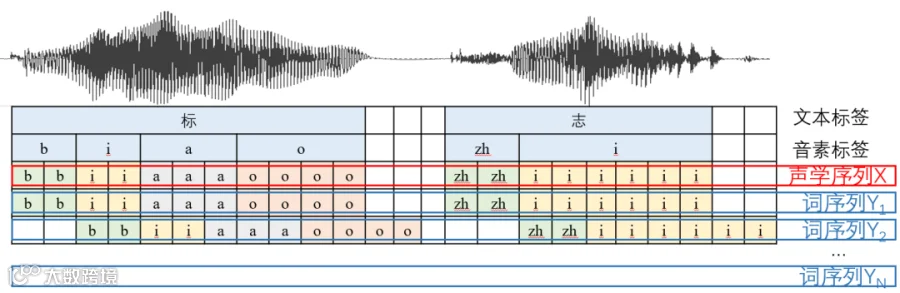
ASR形式化如下: 假设 是声学特征的序列T是时间, 是所有可能的词序列 , 目的是找到最合适的一个词序列 。
注意这里的公式和强制对齐非常类似,这也是为什么强制对齐一般基于ASR的原因,但是此处的词序列的长度为 , 是文本的长度而我上文提到的 的长度为 , 要小于 . 所以ASR的目标和强制对齐的目标并不完全一致,比如上图中序列 和序列 对ASR结果没有区别,但是对强制对齐效果就不一样了。
-
ACC和F1[8]
-
对齐分数(Alignment score)[9]
边界位移(BD)[10]
重叠率(OVR)[11]
Common_Dur=最新时间戳和最早时间戳之间的持续时间
Dur_ref=手动对齐段的持续时间
Dur_auto=自动对齐段的持续时间
1.3 强制对齐用途
A. 处理语音任务中不等长任务训练问题
-
在以HMM,CTC和RNN-T架构为基础的ASR中,对齐是训练过程中的一环。 -
比如在Glow-TTS和VITS为例的TTS中使用了单调对齐搜索(Monotonic Alignment Search,MAS)方法。
B. 时间戳 (歌曲电影字幕、口语评测等)
-
在字幕标注中需要短语及词级别的时间戳,而口语评测则需要音素级别的时间戳。
二、目前对齐方法
目前主流的对齐方法都是基于ASR. 现在主流的ASR架构有:HMM, CTC, RNN-T, LAS. 但是并非所有的ASR模型都适合做强制对齐。 其中LAS是Seq2seq结构,使用Attension进行全局对齐,如果不添加位置信息其对齐结果很难保持单调。而且其对齐成本较高一般很少用来做强制对齐。
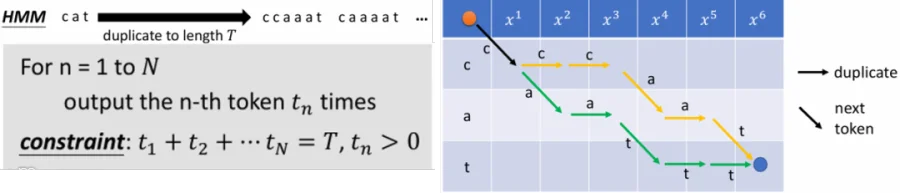
在此处李弘毅老师的课讲得很好。其中cat是给定的文本,
是输入的声学特征。其中T是时间,
为第
个token重复的时间。对齐的过程是在横轴为
,纵轴为给定文本token的图中搜索出一条最佳路径。
2.1 HMM的对齐:
2.2 CTC的对齐:
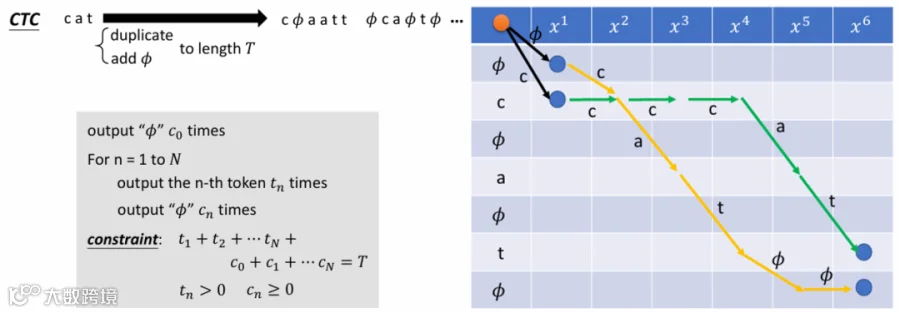
其中Φ为插入符号,用于标记token之间的边界。
2.3 RNN-T的对齐:
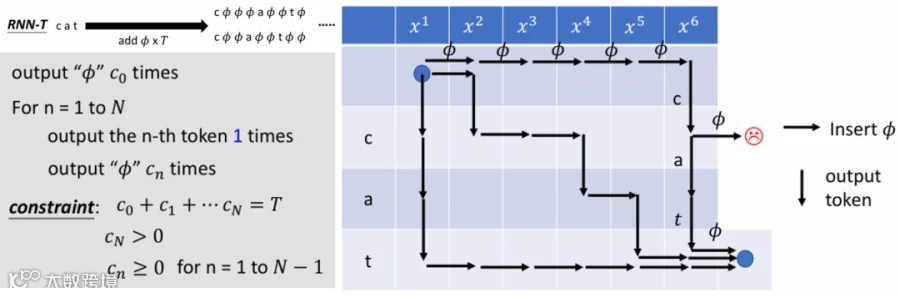
RNN-T中的Φ设计的目的则只是为了对齐特征和文本之间的总长度,并没有标记边界的目的。虽然一般情况下可以标定边界,但是不排除某一个语音特征块可以解出一个以上的token,因此也不会被用于强制对齐。
2.4 其他方法
其他方法很多都是以上三种的改进和延申:
-
WhisperX:按照他们的说法:“训练了一个音素识别模型,然后用动态时间规整搜索最优路径” 。这个感觉和HMM方法差别不大,因为都需要训练音素识别模型。其效果略低于HMM方法。 -
Wav2Vec2-FS: 用 Librispeech 数据集的对齐结果作为训练标签,训练模型对每一帧进行音素分类。推理时,既可以直接通过模型预测得到音素对齐,也可以用动态时间规整算法结合转录文本得到. 如果这么做岂不是说明其他工具的对齐能力是提出方法的上限?
2.5 对比
目前来说基于HMM的强制对齐效果要优于基于CTC方法,有以下几个原因:
-
CTC尖峰漂移:在HMM中对齐的对象为音素,其输出序列直接是其状态的重复。而CTC对齐对象是字符,其引入了blank占位符来标记状态结束。由于blank的存在,CTC更容易产生尖峰和倾向延迟。 -
建模单元细粒度:HMM中使用的是三音素,CTC一般使用字符或者子词. 不同建模单元意味着不同的时间粒度,很显然音素级别的时间粒度更有利于精准地对齐。 -
上下文信息:CTC使用条件独立假设,其忽略了时序上的相关性,进一步削弱了其对齐精度。 根据这篇报道,目前基于HMM的对齐方法效果最好[8],这其实也符合我的日常感受,只不过我没有定量测试。
2.6 工具包
-
基于HMM的方法: Montreal Forced Aligner,gentle, Prosodylab-aligner, Penn Phonetics Forced Aligner, FAVE-align, MAUS, Forced Alignment tools
-
基于CTC的方法:NeMo, WAV2VEC2-CTC
-
基于神经网络的方法: WhisperX
三、挑战
-
准确度:目前基于ASR的强制对齐影响其效果的主要有声学模型的能力和建模单元细粒度。虽然HMM能取得较好的对齐效果但是其声学模型相较于现有的方法其建模能力已经落后。 -
效率:虽然动态规划从算法上已经节省了很多计算,但是HMM对齐工具往往依赖大量CPU计算和复杂的流程,这限制效率。 -
拓展性:对于不同的领域、词汇表中没出现的词汇、不同语言等问题HMM因其没在训练中见过表现得不好。除了重新训练没有更好的办法。导致拓展性较低。
四、讨论
-
帧级别标签:将注意力回到强制对齐需要解决的问题上 ,在ASR中对齐后会将相同token合并得到文本然后与标签计算损失,从合并之后强制对齐和ASR任务就开始有分歧了。因此,如果有帧级别的标签,然后有监督地训练强制对齐模型,将会取得更好的对齐效果。已有这种做法提出,但是帧级别标注成本较高。因此有使用HMM模型先强制对齐标注好,然后再训练专门的对齐网络的方法[4]。 -
引入对齐loss:从上文问题定义和客观评价标准可知ASR和对齐两任务是有区分的。讨论1帧级别标签“”中使用帧级别标签已经属于引入对齐的loss,但是可以进一步优化目标函数降低标注成本针对性的解决对齐问题本身,类似说话人日志专门用于区分音素边界,这可能是一个方向。 -
ASR建模细粒度:既然建模单元细粒度会影响强制对齐的效果,因此如果将更高细粒度建模目标比如音素等会更准确吗?已有一些方法这么做[5][6]。 -
缓解CTC对齐不准:如果说CTC的尖峰漂移会导致边界定位不准,那么如果想办法减轻CTC的延迟,其对齐会更准确吗?这个也会的,有手动前移的但这会影响ASR效果。另有一个方法,就是在训练时让原本对ASR无区分性的路径引入风险函数而有区分[7]。

参考文献:
[1]. https://groups.google.com/g/kaldi-help/c/78ozvyX0aeQ?pli=1
[2]. http://www.phon.ox.ac.uk/jcoleman/BAAP_ASR.pdf
[3]. https://zhuanlan.zhihu.com/p/419883319
[4]. (Jeon, Woojay. "Timestamped Embedding-Matching Acoustic-to-Word CTC ASR." arXiv preprint arXiv:2306.11473 (2023)
[5]. Bain, Max, et al. "Whisperx: Time-accurate speech transcription of long-form audio." arXiv preprint arXiv:2303.00747 (2023).
[6]. Cao, Xinwei, et al. "A Framework for Phoneme-Level Pronunciation Assessment Using CTC." 25th Interspeech Conferece 2024, Kos Island, Greece, Sep 1 2024-Sep 5 2024.
[7]. Tian, Jinchuan, et al. "Bayes risk ctc: Controllable ctc alignment in sequence-to-sequence tasks." arXiv preprint arXiv:2210.07499 (2022).
[8]. Rousso, Rotem, et al. "Tradition or innovation: A comparison of modern asr methods for forced alignment." arXiv preprint arXiv:2406.19363 (2024).
[9]. https://montreal-forced-aligner.readthedocs.io/en/v3.2.0/user_guide/implementations/alignment_evaluation.html
[10]. Williams, Samantha, Paul Foulkes, and Vincent Hughes. "Analysis of forced aligner performance on L2 English speech." Speech Communication 158 (2024): 103042.
[11]. Paulo, Sérgio, and Luís C. Oliveira. "Automatic phonetic alignment and its confidence measures." Advances in Natural Language Processing: 4th International Conference, EsTAL 2004, Alicante, Spain, October 20-22, 2004. Proceedings 4. Springer Berlin Heidelberg, 2004.
内容来源:语音算法组
来源注明为其他媒体来源的信息,均为转载自其他媒体,并不代表声学楼赞同其观点,也不代表声学楼对其真实性负责,转载请联系原出处。您若对该文章内容有任何疑问或质疑,请立即与后台小编联系,平台将迅速给您回应并做处理。

