

随着智能座舱的发展,语音已成为车载交互的重要入口。传统顶棚或中控布置的麦克风在静态环境下表现尚可,但在高速行驶、开窗或敞篷等场景中,风噪、路噪以及车内人声会降低识别率。这一长期存在的问题促使产业界不断寻找替代或补充的技术路径。

美国哈曼国际工业公司在今年早些时候授权公告了一项名为“座椅嵌入式语音传感器”的专利(US12233752B2),提供了一种与传统空气声拾音路径不同的解决方案。
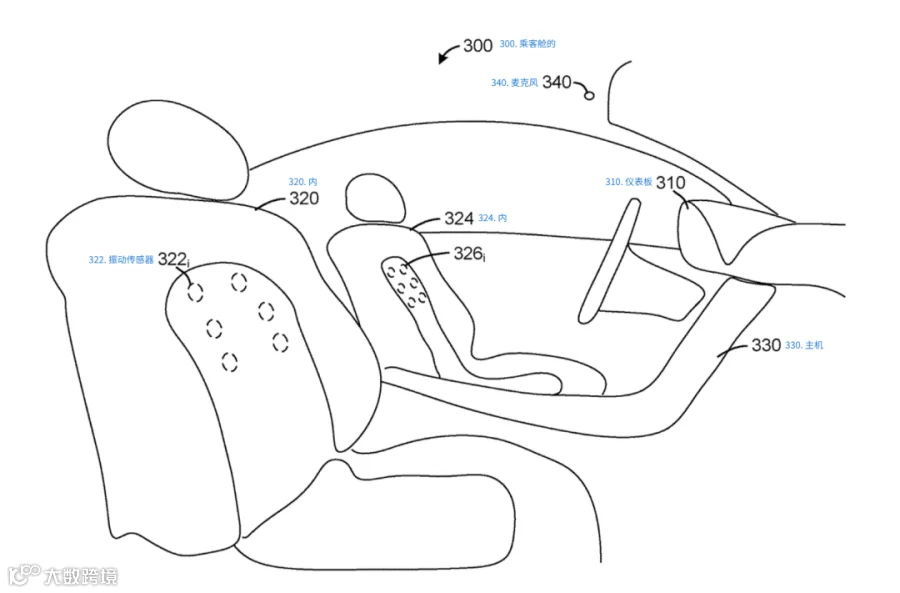
该专利的核心思想是将振动传感器嵌入座椅靠背的泡沫层中,传感器在结构上与乘员背部保持紧密接触,从而能够捕捉到语音产生过程中通过骨骼与软组织传导的振动信号。与空气传播声波不同,骨传导信号具有更高的抗噪性,其主要频率成分集中在2 kHz以下。
专利中提出,振动传感器可以采用压电元件(如PZT陶瓷、PVDF薄膜)、MEMS加速度计或应变计等形式。这些传感器通过腔体嵌入方式固定在座椅泡沫中,腔体形状和尺寸可以根据人体工学设计成圆形、椭圆形或矩形,直径范围从5 - 50mm,以适应不同体型和姿态的乘员。部分设计甚至允许传感器表面略微凸出座椅,以增强接触质量。
|
|
|
|
|
信号采集后,系统会进入多级处理阶段。首先是滤波处理:通过高通滤波器剔除低于200–300 Hz的车辆行驶振动信号,同时利用低通滤波器去除超过4 kHz的无效成分,从而保留语音主要频带。
其次是信号增强与重建:由于骨传导信号天然缺乏高频细节,专利提出结合语音重建算法或基于机器学习的预测模型对信号进行补偿,以恢复更自然的语音质感。此外,系统还可配备放大电路与专用信号处理单元(PCBA),以确保采集信号在传输至车辆主机前保持稳定。
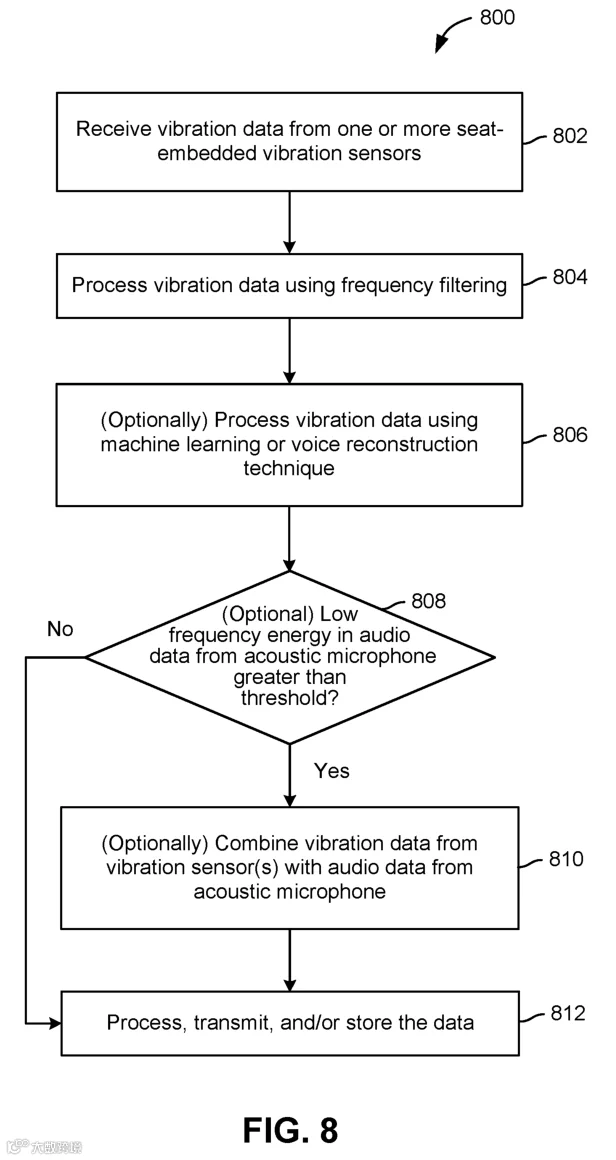
图8为处理振动传感器信号的方法流程图,步骤包括接收振动数据、频率滤波、可选的机器学习或语音重建处理、判断声学麦克风声音数据低频能量与阈值关系、可选的数据融合,最后对数据进行处理、传输或存储。
专利还强调了多源融合机制。车辆内通常仍然配置有空气声麦克风,例如位于顶棚或中控区域。当外部噪声较轻时,系统可以将空气声信号与座椅传感器信号结合,以获得更高保真度的语音;而当检测到空气声信号的低频能量过强(表明风噪严重)时,系统则优先使用骨传导信号。通过这种动态切换或加权融合,方案能够在不同环境下兼顾语音清晰度与自然度。
该专利将已有的骨传导拾音方式进行车载化、嵌入式应用的系统化设计。其特点在于:一是硬件设计上强调“无感化”,乘员无需额外佩戴设备即可使用;二是提出了完整的采集、滤波、重建与融合流程,使其能够适配复杂车内场景。
与现有方案相比,该专利提供了一种差异化的设计路径。单一空气声麦克风在强噪声场景下性能受限;麦克风阵列和波束成形方法在部分高端车型中已有应用,能够提升目标语音的方向性,但在高速风噪条件下依然存在不足;咽喉麦克风或骨传导耳机在军事和运动环境中表现优异,但需要佩戴设备,缺乏舒适性。座椅嵌入式方案避免了佩戴的不便,同时具备较强的抗噪能力。
然而,它的局限性也十分明显:骨传导信号带宽有限,语音自然度下降;不同用户的体型、姿势及衣物厚度可能影响传感器的接触效果,导致信号不稳定;此外,传感器嵌入座椅还需考虑舒适性和制造成本的平衡。
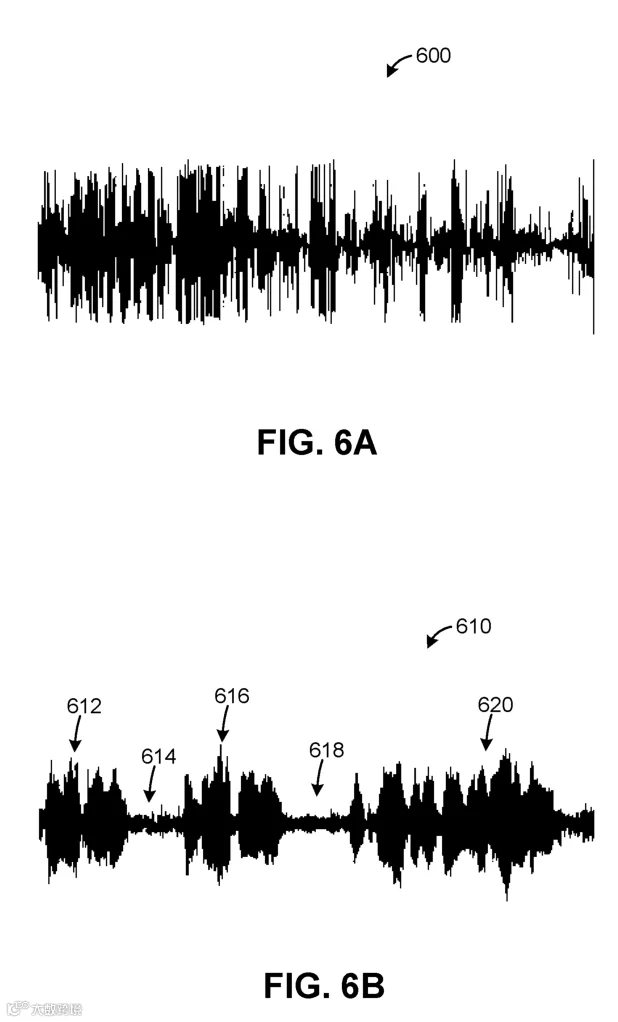
图 6A 是声学麦克风在特定车辆行驶条件下采集声音数据的波形 600,语音与风噪声混合,信号信噪比差;图 6B 是座椅内单轴加速度计采集振动数据的波形 610,含与语音和仅与风噪声相关的区域,振动数据信噪比更好,但频率分量少于声音数据 。
产业界和学术界同时在推进其他解决方案。例如,基于深度学习的语音增强方法已经在低信噪比条件下展现出较高的语音恢复质量,代表了当前车载和消费电子领域的主流方向。
多模态融合技术也逐渐兴起,通过结合空气声、口型识别、毫米波雷达胸腔振动信号等信息,提升鲁棒性和准确性。此外,头枕或安全带嵌入式传感器的研究也在探索中,这些位置距离声源更近,信号稳定性更高,但在舒适性与成本控制方面仍面临挑战。
综上,这项专利提出的座椅嵌入式语音传感器方案为车载语音采集提供了一条新的路径。它的创新在于将骨传导拾音嵌入座椅,实现了“无感化”的信号采集,并通过滤波、重建和融合机制提高了语音信号的鲁棒性。

尽管存在带宽受限、适配性差异和舒适性问题,该方案仍然可以作为现有车载语音系统的重要补充。结合深度学习语音增强和多模态融合等前沿技术,其应用潜力在未来仍具有较大的发展空间。
内容来源:21dB声学人
