
导语
在2025年12月的第18届SIGGRAPH Asia(亚洲计算机图形和互动技术会议)上,腾讯游戏前沿渲染团队负责人李超在研讨会上表示,MagicDawn即将上线空间音频新技术——该技术通过AI与光线追踪技术的深度融合,像计算光线一样计算声音,利用AI与先进的光线追踪技术(GPU raytracing),将光学研究成果迁移至声学模拟。

在正式分享干货之前,先让大家感受一下,当前MagicDawn空间化音频技术的效果,一段30秒的游戏画面声音,划重点,记得戴上耳机感受!
OK,接下来是干货!当前空间化音频技术的现状和未来的发展趋势几何?本文为您奉上!
空间化音频技术(Spatial Audio)是近年来游戏工业中一项关键的技术革新,与传统立体声仅提供左右声道平面感知不同,空间化音频技术通过模拟声音随距离的衰减、遇到障碍物的反射、衍射与阻挡以及声源的方向性变化等声学传播效果,使得玩家不仅能听声辨位,还能感知虚拟环境的声学特性,如房间大小、材质和空间布局,从而获得全方位的沉浸式体验,显著提升了游戏的沉浸感、真实感和交互性。
此外,空间化音频技术本身也在逐渐发展成为游戏机制的一部分:在FPS游戏中,玩家能通过脚步声、枪声或技能音效精准判断敌人的方位、距离甚至动作意图;在恐怖冒险游戏中,来自不同方向的细微环境音效能极大地增强紧张感和氛围感;一些游戏还通过空间化音频来引导玩家走向期望目标,推动剧情发展。例如下面就是一段微软空间化音频方案Project Acoustics的演示视频,从视频的前后对比可以明显感受到空间化音频给游戏体验带来的巨大差异(推荐戴上耳机感受):
声学原理 -- 空间化音频关键技术
空间化音频技术主要包含下面这些声音传播现象的模拟:
(图源1:声障、声笼及 Game-defined Auxiliary Sends)
(图源2:Project Triton - Immersive sound propagation - Microsoft Research)
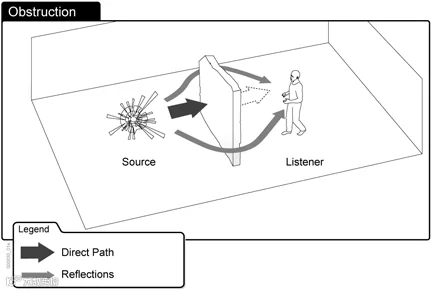
1)声障(Obstruction)
声障是指游戏中的对象(如墙壁或柱子)部分挡住了声源和听者之间的空间。比如,在特工游戏中,即便玩家躲在柱子后面,照样能听到前方的枪声。 (来源:wwise)
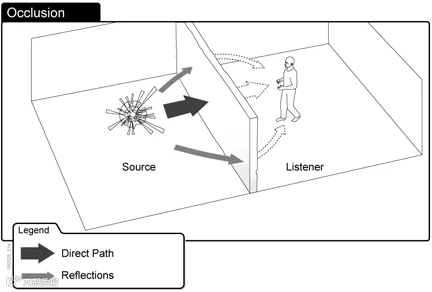
2)声笼(Occlusion)
声笼是指游戏中的对象完全挡住了声源和听者之间的空间。比如,在特工游戏中,即便隔着一堵墙,玩家仍有可能听到隔壁房间的枪声。 (来源:wwise)
3)声音的门效应(Portaling)
与光线不同,声波的波长更大,因此波动现象更明显,当声波遇到与波长相近的物体或物体边缘会发生衍射现象,从而绕过物体传播。
听感效果:
听者即使在声源看不见的区域(如墙角或门后),仍能听到声音,但感觉声音较弱且音质较暗淡;
声音穿过门缝、墙角等位置时产生衍射效应,使声音传递自然、不发生突然消失。
4)声音的混响(Reverberance)
混响是声源停止发声后,声音在封闭或半封闭空间内多次反射或散射而持续存在的声音残响。
听感效果:
决定空间感和大小感;
声音更圆润丰满,减少干声干涩感;
有助于分辨不同空间的声学特性(教堂、剧院、室外等)。
5)声音的衰减(Decay)
衰减指声音传播距离增加时,声压级逐渐降低的现象,更大的房间,混响时间更长。
听感效果:
远距离听声音变得更弱和暗淡;
高频率成分因吸收衰减而减少,声音听起来更“浑浊”;
常见的音频相关概念
本文面向的是工程师群体,可能会有很多工程师对声学相关的一些概念不是特别熟悉,所以这里把后面会遇到的一些常见音频相关概念做详细的介绍:
1)ImpulseResponse (IR)
想象一下,你在一个空荡荡的大教堂里拍一下手。
你拍手的那一刻: 这就是一个非常短促、非常突然的声音事件,类似于一个“声音脉冲”。在理想情况下,我们可以把它想象成一个极短、极强的“砰”的一声(技术上称为“狄拉克脉冲”),它包含了我们能听到的所有频率的声音。
声音在教堂里传播: 这个“砰”的声音从你拍手的地方(声源位置)向四面八方扩散开来:
首先,直接声音 (Direct Sound) 几乎直线传到你的耳朵(听者位置)。
然后,声音撞到墙壁、柱子、天花板,你会继续听到下面两类声音:
早期反射 (Early Reflections):这些是声音发出后几十毫秒内,从墙壁、家具等主要表面反射回来的、相对清晰可辨的短促回音集合。
晚期混响 (Late Reverberation):代表声音发出几百毫秒后,经过无数次散射和反射形成的、绵长密集、像“余音”一样的混响声场。它越来越弱,直到消失。那么这里还涉及到一个概念是混响时间(Reverberation Time,简称RT60):指声源停止发声后,房间内声能衰减60分贝(dB)所需的时间(单位:秒)。通俗来说,它描述的是声音在房间里“残留”的时间长短。
把这三部分随时间的声压变化画出来就是下面这个样子:
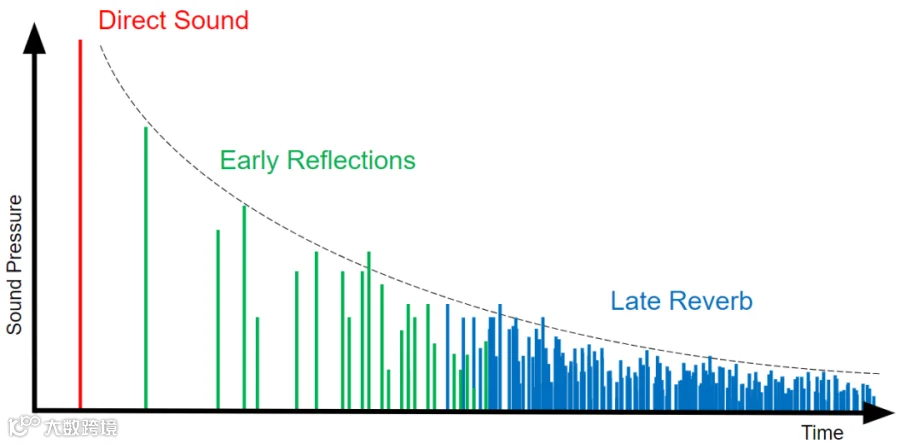
图源:Wwise文档
现在,把这个过程录音下来!那么,这个录音设备记录下来的整个声音序列——从那个“砰”声开始,到所有的回声和最后的混响完全消失为止——就是这个特定的声源位置和特定的听者位置在这个特定的教堂环境下的 声音指纹。
这个“声音指纹”,就是 Impulse Response (IR)。
那么为什么Impulse Response如此重要呢?因为一旦你知道了某个环境在特定位置A对点B产生的 IR,你就能预测任何其他声音在这个环境里从 A 点到 B 点听起来会是什么样!具体方法就是使用这个Impulse Response对其他的声音做卷积就可以了!
2)双耳效应(Binaural Effect)
双耳效应就是我们的大脑利用两只耳朵听到的声音在时间、响度和音色上的细微差别,来精确定位声源方向的“超能力”。 就像你用两只眼睛看东西才能产生立体感一样,两只耳朵让你听到的声音也具有“立体感”。
双耳效应的实现,依赖于头部相关传递函数(HRTF:Head-Related Transfer Function):
假设有一个声音来自左边:
它到达你左耳的时间会比到达右耳稍早一点( Interaural Time Difference, ITD)。
它到达你左耳的音量会比到达右耳的稍大一点,因为你的头挡住了部分声波(Interaural Level Difference, ILD)。
最重要的是,你的耳廓会对声音进行复杂的反射和过滤,这种改变高度依赖于声音的来源方向。
HRTF就是精确地测量和记录了任意方向上所有这些变化(ITD, ILD, 耳廓滤波)的函数。
有了HRTF,我们就可以将一段单声道音频,比如游戏中敌人的脚步声,应用特定方向的HRTF函数;处理得到的音频再通过耳机播放的时候,你的大脑就会上当,认为声音是从这个特定的虚拟方向传过来的。
既然HRTF是要记录任意方向上的声音传播变化,数据量肯定要爆棚了,我们应该如何存储这个各向的数据呢?
这个时候,球谐系数(Spherical Harmonics)就登场了。(经常做GI的朋友立刻就明白是怎么回事了)。
球谐函数是一组定义在球面上的正交基函数,可以把它理解为 “球面上的傅里叶变换”。任何定义在球面上的函数(例如:各个方向上的全局光照强度、HRTF等)都可以由一系列不同阶的球谐函数叠加而成。所以,HRTF就可以使用SH来编码了。
3)Ambisonics
Ambisonics 是一种基于球谐函数(Spherical Harmonics) 的全包围三维声场格式,是声音世界的“360度全景录音技术”。注意他与播放无关,是一种“声场描述”技术:Ambisonics 麦克风在录音时,并不关心你最终会用多少个喇叭或耳机来回放。它只做一件事:尽可能完整地记录下当时环境中来自四面八方所有方向的声音信息。
当你回放这段 Ambisonics 录音时,即可通过SH的解码,根据你音箱的实际摆放位置,把声音信息正确地分配出去;或者通过 HRTF,根据个人听觉特性将Ambisonics 声场正确的解码为与你耳机匹配的声音。
4)衍射
由于声波的波长通常与日常生活中许多障碍物的尺寸相近,因此相比光波,声波更容易发生明显的衍射现象,即能够绕过障碍物或通过孔洞传播到其后面的几何阴影区。
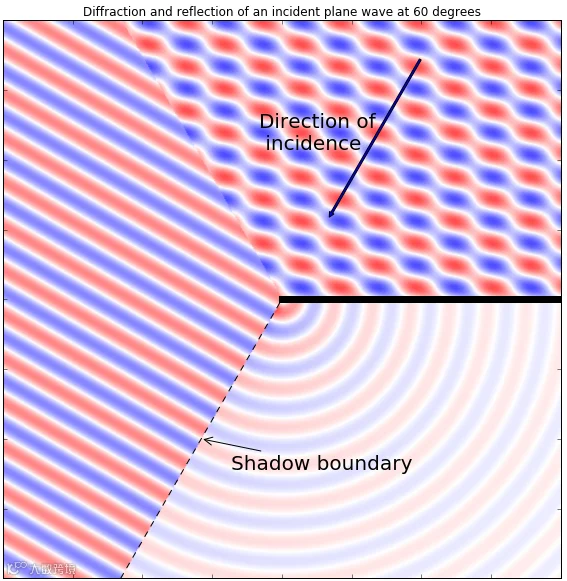
例如下面这张图,(图源:Spatial Audio 概念)
在以下声场图中,平面波从右上方入射,并在传播过程中遇到有限面(图中表示为从中央向外延伸的黑线)。此边缘造成的扰动即称为“衍射”。左侧区域为 View Region(可视区)。在此,平面波直接穿过,不发生任何改变。右上区域为 Reflection Region。在此,平面波遇到表面发生反射,并与入射波混合,呈现锯齿状。右下区域为 Shadow Region。在此,衍射发挥主导作用。
空间化音频方案介绍
目前主流的空间化音频方案主要分为两类,一类是几何声学模拟,一类是波动声学模拟。
几何声学模拟方案通常使用射线检测、光线追踪等方式来确定声学传播路线,目前大部分的方案都是几何声学模拟方案,包括Steam Audio、Wwise、育碧的Snow Drop引擎声学方案、彩虹6号、Overwatch等。
波动声学模拟方案目前最有影响力的就只有微软的Project Acoustics了。
下面从这两类方案入手分别介绍各自的优缺点。
1)几何声学模拟方案介绍
1.1)Steam Audio
说起几何声学模拟方案,那么不得不提的一定是Steam Audio了:
开源免费,Apache 2.0协议,广泛的平台支持(PC、移动)和引擎支持(Unity、Unreal Engine),与FMod、Wwise的集成,开箱即用,这些听上去就对开发者非常友好了。
除此之外,Steam Audio在声学方面也有很多亮点:
支持声音的遮挡、反射、透射、多路径传播。
支持动态可移动模型影响声音的遮挡、反射、混响等效果。
静态场景支持烘焙的方式,提前烘焙好能量场,实时转换为IR来与声音卷积;也可以在Probe上烘焙声音的传播路径,用来实时更快的找到动态音源和动态听者之间的声音传播路径。
带GPU加速功能,不仅仅是光线追踪有GPU加速,卷积、反射和混响模拟也可以在GPU上进行。
1.2)Wwise
Wwise作为业界标准的音频中间件,同样有着空间化相关的模拟技术。
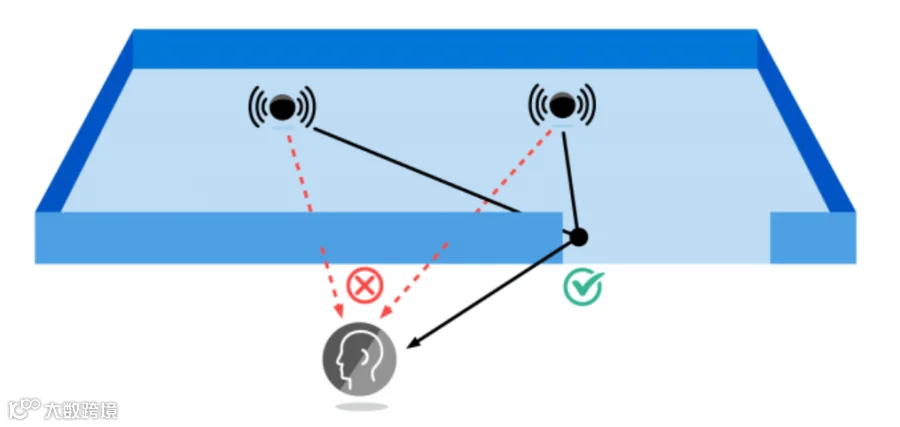
Wwise主要通过简单的上层几何抽象概念(即 Room 和 Portal)对其他 Room 内发声体的声音传播进行准确建模。例如下图中,Emitter通过两次衍射路径,最终声音传播到Listener。
对于相邻 Room 内的每个发声体,Spatial Audio 都会计算相连 Portal 最近边缘与 Shadow Boundary(阴影边界)的衍射角。然后,将此衍射角(最大 180 度)映射为衍射系数 (0 ~ 100%),并提供给 Wwise 用户。
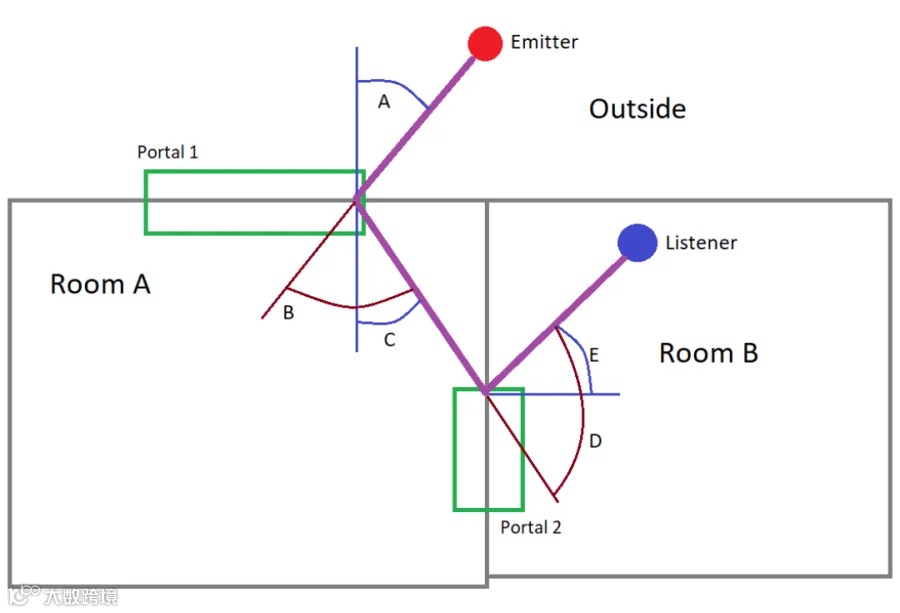
Wwise这种方案的优点是比直接通过光线追踪来做音频传播模拟的效率会更高一些,缺点当然也很明显,音频设计师需要花很多的时间来摆放Room、Portal,非常不方便。
1.3)育碧SnowDrop引擎
育碧的SnowDrop引擎从全境封锁开始就已经有自己的声学引擎,并在GDC上做了一系列的分享:
GDC2020 | Finding Space For Sound: Environmental Acoustics in 'Tom Clancy's The Division 2'
GDC2024 | Finding Space for Sound: Acoustics in 'Avatar: Frontiers of Pandora'
GDC2025 | GPU Raytracing for Audio in Snowdrop
育碧在GDC2020全境封锁中的方案:
首先,他们的理念是:声学效果与空间相关,对空间的预估可以帮助生成与玩家视角相匹配的声学效果。因此,他们提出了Bubble Space的概念,会围绕玩家用一些射线持续跟踪检测玩家所处空间的大小,并使用这个大小来影响声音的效果,包括枪械的尾音、街道的回声、环境音等等。
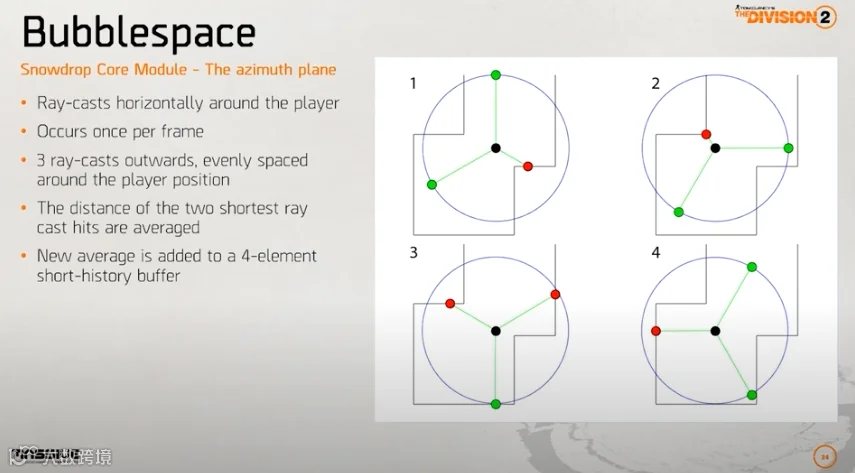
另外还有一个概念是Slapback,Slapback系统主要是为了生成清晰的早期反射,同样也是围绕玩家做射线检测,击中声学材质的射线会使用表面法线计算出虚像的位置,来模拟出反射声音的效果。
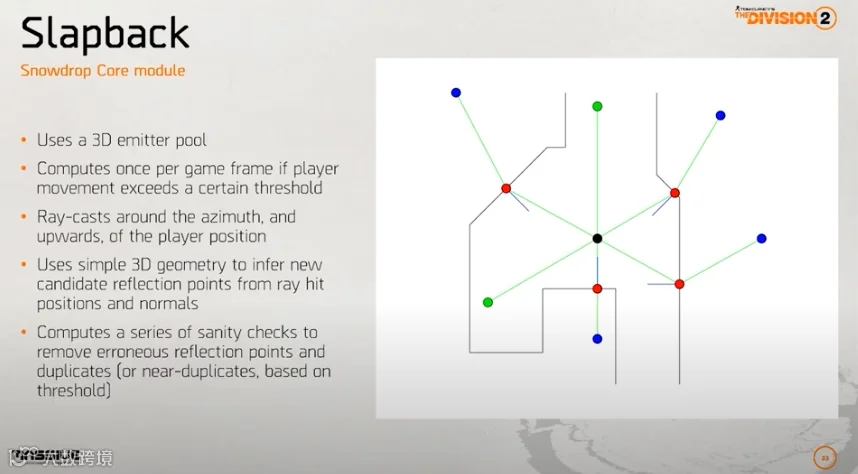
育碧在GDC2024关于《阿凡达:潘多拉的边境》的讲座中介绍他们进一步升级了Bubble Space和Slapback系统:
新的Bubble Space调整了空间的计算方式,不会在某些极端情况下出现极端的效果;新的Slapback系统不仅仅可以生成早期反射,还可以进一步生成晚期回响;支持地形和一些自然现象。整体上听上去是对全境封锁中方案的修修补补。
而在2025年的GDC中,育碧公开了GPU raytracing的方案。新的GPU方案相比之前的声学系统,主要为了实现3个目标:声音听上去更加真实、可以支持更复杂的场景(之前的方案更适合城市环境)、减少音频设计师手动给每个物体标记衍射和遮挡属性的操作。为了减少GPU延迟对声音效果的影响,引入了深度缓存,可以加快衍射预测。
但是在这个方案中,仍然是要求设计师对Room和Portal有标记的。
1.4)彩虹6号的动态破坏方案
彩虹6号方案中为了支持整个建筑墙体的破坏对声音传播的影响,需要在墙体中放置 Propagation Node。当墙体产生破坏时,最近的 Propogation Node 会参与计算声音传播路径,将声源移动到衍射路径上的虚像点上来模拟衍射效果。

1.5)几何声学方案总结
几何声学方案的优点是显而易见的,动态环境、动态障碍更容易支持;
而缺点也不是没有:
从上述方案中可以看到,为了加速射线计算或者模拟,一些几何声学方案需要一定的人工标记;
射线检测、光线追踪本身会带来一定的开销;
模拟的效果总体上是不如预烘焙的IR更加精确的,有一些方案的模拟多少有点 trick:比如关于声波的衍射,一些方案在用反射射线比例来模拟声波的衍射,这个结果是不准确的。像 SteamAudio 也有音频同事试用过,主要对声音传播路径模拟这部分不是很满意,也反馈容易在高衍射环境下产生虚像。
2)波动声学模拟方案介绍
2.1)微软 Project Acoustics
波动声学模拟方案中影响力最大的就是微软Project Acoustics了(早期名字叫Project Triton),这个方案会在离线穷举烘焙出场景中所有可能的音源-听者对的声音传播IR,然后创新的通过一种“可感知编码”方式来将TB级别的离线烘焙数据压缩到仅有百兆级别,并且实时卷积开销固定,不会随音源数量的上升而增加。最终在运行时,支持音源和听者的移动,以及非常准确的波动声学模拟效果。
这个方法仅需要生成一些probe,并不需要音频设计师像Wwise一样去手动做盒子、开口的标记,因此整体对设计师是比较友好的。
微软的Project Acoustics在研发中公开了一系列的重量级论文成果,例如:
Parametric Wave Field Coding for Precomputed Sound Propagation,Siggraph 2014
Parametric Directional Coding for Precomputed Sound Propagation,Siggraph 2018
Adaptive Sampling for Sound Propagation,TVCG 2019
Ambient Sound Propagation,Siggraph 2019
Efficient and Accurate Sound Propagation using Adaptive Rectangular Decomposition (ARD), TVCG 2009
同时,上述主要思路被微软申请了专利,这可能也是波动声学模拟这条技术路线上没有其他有影响力的方案的原因了(当然本身微软方案做的也很棒)但是比较可惜的是,2024年初,这个项目关停了,公开的说法是目前仅给内部工作室使用。
Project Acoustics是使用Probe来承载声学信息的,包含两种Probe:Audio Source Probe和Listener Probe。Audio Source Probe用来覆盖所有音源可能出现的位置,Listener Probe要覆盖所有Listener可能走到的位置,通常使用寻路网格来辅助生成。
如下图所示(图源自微软GDC2019:Project Acoustics),左图中蓝色的box就是Listener Probe,主要覆盖角色可能会走到的位置,右图棕色的box就是Audio Source Probe,基本上需要覆盖到所有动态Audio Source可能会出现的位置。

有了Probe之后,就需要对每一对音源-听者对记录声音波动传播的模拟结果。
常规的声学波动模拟需要使用有限元方法,但是这种方法离线模拟是非常慢的,一个17m × 15m × 5m的房子都需要跑上3天。因此,微软团队在Efficient and Accurate Sound Propagation using Adaptive Rectangular Decomposition (ARD), TVCG 2009 一文中介绍了他们使用的波动模拟方法,主要的思路是这样的:
对于一个复杂的房间模型,不存在数学上的解析解来直接快速生成波动模拟的结果,需要使用FDTD方法来步进模拟,速度非常慢。
但是!在矩形子域内,波动方程存在解析解且形式为三维余弦驻波的线性叠加,因此在一个矩形子域内,可以将声压场通过DCT(离散余弦变换)转换到模态空间来快速迭代更新,再通过iDCT来得到更新后的声压场。
所以,我们只需要将复杂的房间模型,拆分成多个矩形子域的集合,就可以在这些矩形子域中用更快的速度来迭代更新了。如下图所示,一个房间,先做体素化,然后对体素化之后的结果分解为多个矩形子域的集合。
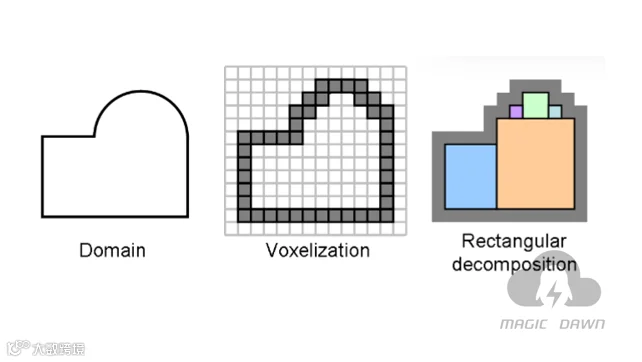
然后在这些子域中对声压场做DCT变换,模态更新迭代,再用iDCT转换为迭代后的声压场。
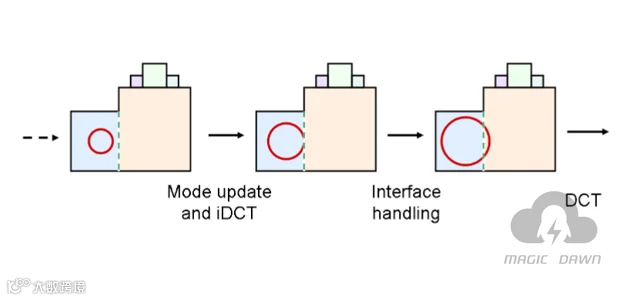
通过上面的这个方法,离线的模拟速度可以被提高到几个小时。原文的数据显示,对于一个有200万面的358×169×31m的场景,使用一个140台机器组成的集群,烘焙20个小时可以得到结果。
烘焙得到的,是每个音源Probe,对所有相关的听者Probe的IR数据,数据量是非常大的,例如上面这个场景得到的数据有66TB。显然,这样的数据是不可能直接拿到游戏里面去使用的。
因此,微软Project Acoustics在Parametric Wave Field Coding for Precomputed Sound Propagation,Siggraph 2014中创新提出了一个“可感知参数”的编码方案。
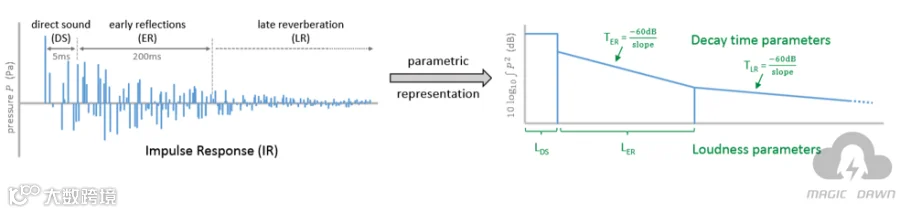
主要思路是这样的:原始的一个IR数据是比较大的,但是对于人耳来说,并不一定需要所有的细节才能对这个声学效果有正确的感知。作者认为,只需要4个浮点数就可以代表一个IR主要的特征,分别是:
声音响度参数(Loudness parameter):
○代表直接声响度的 L_DS
○代表早期回响声音响度的 L_ER
衰减时间参数(Decay time parameter):
○代表早期回响衰减时间的 T_ER
○代表晚期混响衰减时间的 T_LR
文章中有描述具体如何从一个IR提取出这4个参数的方法,这里不再详细解释。
那么实时如何从这4个参数还原出尽可能逼近离线烘焙IR的IR数据呢,这就要引出规范滤波器(Canonical Filter)的概念了。
规范滤波器是预先设计好的“声音特效模板”:
这些模板是精心设计的立体声音频片段,它们被设计用来代表特定类型的声音传播效果,特别是:
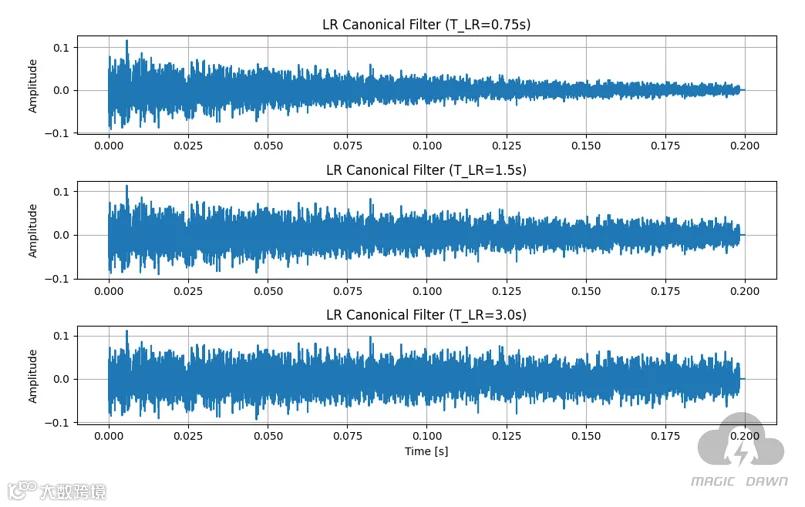
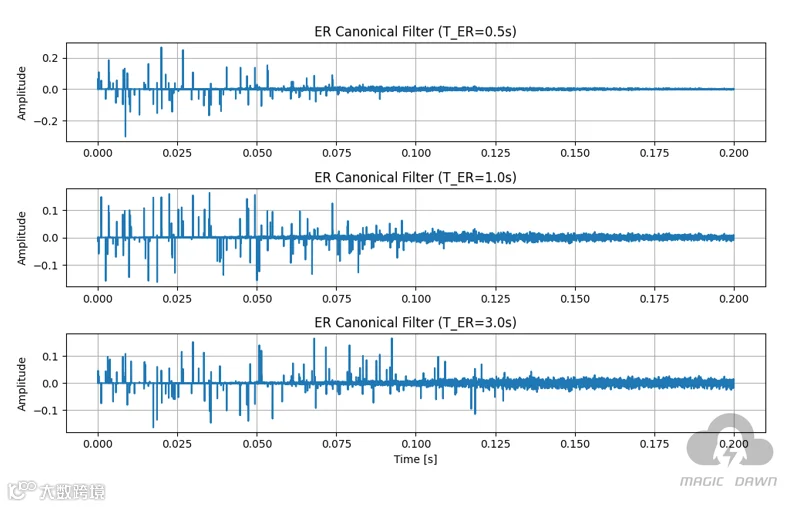
早期反射 (Early Reflections, ER):论文设计了3个ER的Canonical Filters,分别代表短(0.5秒衰减)、中(1.0秒衰减)、长(3.0秒衰减)三种不同的衰减速度。晚期混响 (Late Reverberation, LR):同样设计了3个LR的Canonical Filters,分别代表短(0.75秒)、中(1.5秒)、长(3.0秒)三种不同的混响持续时间。
这是我们复现的这篇论文的规范滤波器的样子:
那么这些规范滤波器是如何工作的呢:
在游戏运行时,系统会根据玩家和每个声源的实时位置,从预先计算好的参数场(存储了L_DS, L_ER, T_ER, T_LR等数值的地图)中快速查找到该位置对应的声学参数值,然后进行下列操作:
组合声音信号: 把这个声音源发出的原始声音信号,按照查到的响度参数 (L_ER, 隐含的L_LR) 进行缩放(调音量)。
选择模板: 根据查到的时间参数 (T_ER, T_LR),在那一小组预定义的Canonical Filters中(3个ER + 3个LR),选择两个相邻的模板(比如,对于ER,如果T_ER=1.2秒,就选T=1.0s和T=3.0s的模板)。
插值混合: 根据参数值计算权重,把声音信号用权重缩放后分别送入这两个选中的ER总线进行处理。
固定总线处理: 所有被送到同一个ER模板的不同声音源信号,会先加权和在一起,形成一个混合的信号流,然后再用这个单一的、固定的ER模板进行卷积处理。对LR模板也一样。
输出叠加: 最后,把各个模板处理后的结果(DS直接声、ER处理结果、LR处理结果)叠加起来,就得到了最终听众听到的、包含了复杂环境传播效果的声音。
为什么说这个方法很聪明?
大幅减少运行时计算量 (核心优势):
把计算量从“随声源数量线性增长”变成了“固定”。 传统方法需要为每个声音源都做一次昂贵的卷积运算。而Canonical Filter方法只需要做固定次数(6次:3个ER总线 + 3个LR总线) 的卷积运算,无论场景中有多少个声音源!每个声源只需要做简单的缩放和信号混合,所以总的计算量几乎不会随声源数量增加而暴涨。
平滑过渡:
当听众或声源移动时,参数值是渐变的。在传统IR插值方法中,如果突然切换IR,声音会不连贯(比如混响突然中断或开始)。而用Canonical Filters的权重插值,声音效果的变化是平滑过渡的,不会产生可闻的瑕疵。
内存效率高:
不需要存储海量的IR数据,只需要存储一小部分固定长度的Canonical Filter音频数据和压缩后的参数场。
灵活性:
虽然只用了几个模板,但通过权重混合,可以模拟出介于这些模板特性之间的、连续变化的声学效果。
当然,这个方案也是有一定的局限性的:
离线计算速度虽然已经优化过,但是140台机器的集群需要20小时烘焙百米场景,还是有点过慢了(之后的GDC声称在此论文基础上速度提高了3倍多)
规范滤波器基于一些假设来生成,比如早期反射的漫反射分量被强制设为总能量的10%,这是没有物理依据的。整个规范滤波器基于室内声学设计,对于开放空间的效果是不准确的。规范滤波器没有建模遮挡导致的低频衰减,因此声效会比原始结果听上去更亮。
对于动态场景的支持非常有限。
未来的方向
可以从最近的一些技术分享,看到未来音频解决方案的一些趋势:未来音频方案一定是一个尽可能减少人工标记,释放音频设计师才华的方案;次世代游戏的快速迭代需求也对静态烘焙部分的效率提出了更高的要求;游戏中越来越多的动态建造、破坏玩法也要求音频系统能够实时做出相应的响应。那么不管是几何声学方案,还是波动声学方案,都存在着诸多可以改进的技术点。
关于几何声学方案
目前大部分的几何声学方案都还是把声音当作光照一样做光线追踪来判断传播路径,而声学传播跟光线传播本身就天然存在着一些不太一样的特性。声波因为波长更大,在传播过程中会呈现非常明显的波动现象,因此使用光线追踪无法直接模拟衍射现象,只能通过路径传播节点、遮蔽比例等方法来近似衍射效果。而最近几年,波动光学有了一些比较大的进展,一系列波动光学相关的文章出现:
例如A Generalized Ray Formulation For Wave-Optical Light Transport,Siggraph 2024,提出了一种广义光线公式,从而可以将波动光学的相关物理量(波前相位、振幅等)嵌入到光线传播模型中,在几何光学的框架下渲染波动光学特性。
例如这只甲壳虫身上源于鞘翅中的多层干涉反射结构所呈现出的色彩,就是使用波动光学模拟干涉现象才能渲染得到的。

当然,在游戏中,我们不太可能会专门使用波动光学方案去模拟这一点点对整体画面影响不是很大的效果,但是,这篇文章的相关理论是不是可以扩展到波动声学,从而让我们可以使用几何光线追踪方法就可以模拟出真实的波动声学效果呢,这是一个非常值得探讨的问题。
关于波动声学方案
目前微软方案呈现的效果是比较惊艳的,但是烘焙的效率问题会使得一般的游戏项目望而却步。如何与我们目前的MagicDawn分布式GI烘焙框架结合,让项目无痛接入烘焙方案,会是一个很有价值的点;另外,如何结合最近的神经网络和机器学习技术,使得我们可以得到更高的压缩比,支持动态场景,以及让规范化滤波器能够克服微软方案的缺点,也是未来我们工作的方向。
我们的项目目标
与目前游戏项目对GI的需求类似,音频方面,游戏项目因为对实时性和性能的要求不同,也会有静态烘焙和实时两种方案。
对于静态烘焙方案,我们希望能够用机器学习的方法,实现对游戏场景声学传播结果更好的模拟,克服微软方案中模拟结果的一些不足。目前我们已经取得了一些小的进展(推荐使用耳机试听):
原始烘焙IR卷积结果:
微软方案复现结果:
我们方案的结果:
另外,我们也希望将目前波动光学的一些研究成果,迁移到波动声学传播的模拟中,这样可以使用GPU raytracing来提高波动模拟的速度,克服微软方案烘焙速度较慢的缺点;
未来,我们也希望将这个GPU raytracing方案进一步扩展到游戏实时中,实现一个音频领域的lumen。
MagicDawn 空间音频解决方案,依托光追声音传播模拟与 AI 拟合技术,打造高保真体验核心优势:
●全场景灵活适配:针对纯静态、半动态(如开关门)、全动态(如场景破碎 / UGC)场景,提供离线预计算 + 实时光追组合方案,全面覆盖各类游戏音频开发需求;
●高保真空间化效果:离线预计算声音波动传播 IR 数据,搭配神经网络压缩技术,实现低数据量下的高保真音频空间感;硬件光追精准追踪声音传播,还原其波动特性,呈现真实的反射、衍射等空间声学效果;
●高效全自动化工作流:无需手动标记或画盒子操作,全程自动化完成探针生成、数据预计算与运行时适配,大幅减少音频设计师与技术美术的重复工作量,且提供Saas化云计算服务,缩短制作周期,充分释放音频策划创意;
●生态兼容无负担:可无缝兼容行业主流音频工具 Wwise,无需改造现有开发流程,快速融入项目研发体系。
欢迎大家关注和探讨!
联系邮箱:magicdawn@tencent.com
内容来源:MagicDawn
