

歌曲结构标注(MSA)是一种能够识别歌曲中具有功能意义的段落(如前奏、主歌、副歌)并精准检测其边界的技术,正日益成为音乐理解和可控音乐生成的重要支撑技术。然而,现有的 MSA 方法通常由于训练数据规模有限、标注不一致、依赖复杂预处理流程等原因,在泛化能力和实用性上受到制约。
近期,西北工业大学音频语音与语言处理研究组(ASLP@NPU)联合香港科技大学、美国西北大学、康奈尔大学、新南威尔士大学以及 M-A-P 的合作论文"SongFormer: Scaling Music Structure Analysis with Heterogeneous Supervision"被 ICME 2026 接收。SongFormer 通过融合多分辨率的自监督学习(Self-Supervised Learning, SSL)表征,并引入可学习的来源嵌入,在严格边界检测(HR.5F)和功能标签准确率上均达到当前最优水平。同时发布的训练集 SongFormDB(超 14,000 首多语言多流派歌曲)和专家标注评测基准 SongFormBench(300 首),弥补了该领域长期缺乏大规模训练数据和标准化评测基准的不足。在实用性方面,SongFormer 同时支持云端在线体验与本地部署,开箱即用,在单卡 NVIDIA L40 上每首歌仅需 2~4 秒即可完成推理。目前模型和代码均已开源,以下对该论文进行简要的解读与分享。

论文题目:SongFormer: Scaling Music Structure Analysis with Heterogeneous Supervision
作者列表:郝春博*,袁锐斌*,姚继珣,邓棋心,Xinyi Bai,王彦博,雪巍,谢磊†
合作单位:香港科技大学,美国西北大学,康奈尔大学,新南威尔士大学,M-A-P
在线体验:https://huggingface.co/spaces/ASLP-lab/SongFormer
Github:https://github.com/ASLP-lab/SongFormer
Hugging Face:https://huggingface.co/ASLP-lab/SongFormer
SongFormDB:https://huggingface.co/datasets/ASLP-lab/SongFormDB
SongFormBench:https://huggingface.co/datasets/ASLP-lab/SongFormBench

发表论文截图

扫码直接看论文
背景动机
歌曲结构标注(MSA)旨在将歌曲划分为功能部分(如前奏、主歌、副歌)并检测其边界,是音乐理解和可控生成的重要支撑技术。随着音乐生成系统的快速发展 [1, 2, 3],利用 MSA 提供结构先验变得愈发重要。目前,现有方法在性能和泛化能力上仍有明显不足,公开音乐数据集稀少(例如 HarmonixSet [4] 仅有 912 首歌曲),且不同数据集之间标注标准差异较大,获取受限,导致许多研究只能基于小规模数据训练,模型泛化能力受限。从方法上看,许多系统仍从零开始训练,而非利用强大的自监督或音频基础模型,一些流程还依赖复杂的预处理步骤如节拍追踪和音源分离,增加了系统复杂性并限制了扩展性。尽管通用多模态大语言模型(如 Gemini 2.5 Pro)也能生成歌曲结构标注,但其时间分辨率较低,难以精确检测边界,且存在标注对齐和格式问题。为此,我们提出了 SongFormer,一种简单且可扩展的框架,能利用异构监督信息并保持高时间精度。SongFormer 融合来自 MuQ 和 MusicFM 的短窗口(30 秒)与长窗口(420 秒)的自监督学习(Self-Supervised Learning, SSL)表征,以同时捕捉细粒度和长距离依赖关系,并引入可学习的来源嵌入(source embedding)以考虑不同数据集的来源信息,使其能在部分标注、含噪声且标注规范不一致的数据上有效训练。为支持大规模训练与公平评估,我们还发布了包含超过 14,000 首的大型多语言多流派结构标注数据集 SongFormDB,以及由专家验证的含有 300 首歌曲的结构标注评测基准 SongFormBench。实验表明,SongFormer 在 SongFormBench 上取得了当前最优的严格边界检测(HR.5F)与功能标签准确率,超越了多个强基线方法和 Gemini 2.5 Pro,同时保持较高的计算效率。

通义千问团队最新推出的 Qwen3.5-Omni 也已在其官方音频理解评测中将 SongFormBench 纳入评测基准之一(图1),详见通义实验室推文 215项SOTA + 自然涌现Vibe Coding!Qwen3.5-Omni发布
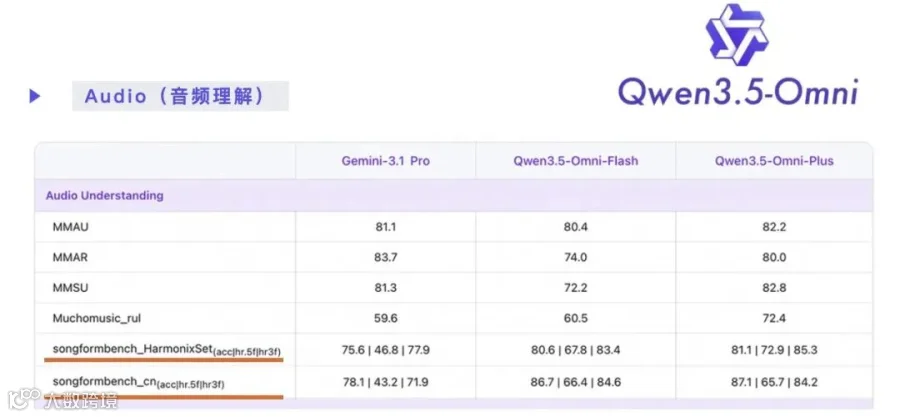
图1 Qwen3.5-Omni 技术报告中的音频理解评测结果
模型架构
SongFormer 的整体架构如图2所示。模型从输入音频中提取多分辨率的 SSL 表征,经过融合和下采样后送入 Transformer 编码器,最终通过两个任务头分别输出边界 logits 和功能标签 logits。
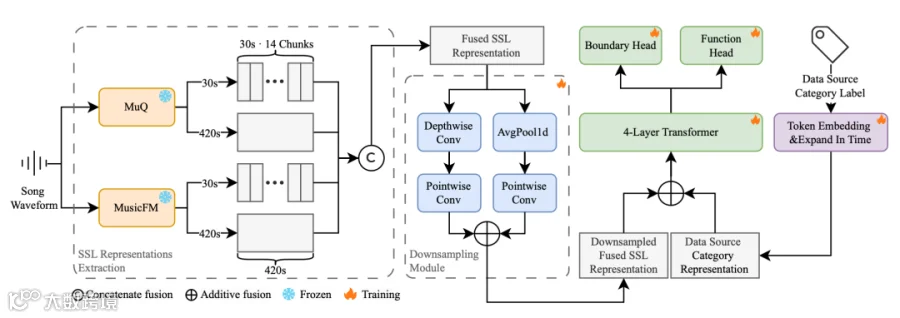
图2 SongFormer 总体架构
推理时,后处理沿用了 All-In-One [5] 的方案:对边界 logits 依次做 sigmoid 激活、局部极大值滤波和峰值拾取,得到边界时间戳,将歌曲切分为若干片段;再对每个片段内的功能标签 logits 取 softmax 后按帧平均,选概率最高的类别作为该片段的标签。最终输出是一组有序的 (起始时间, 标签) 对:
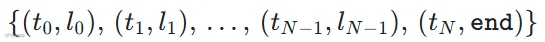
其中标签集合为:

多分辨率 SSL 表征的融合
已有工作 [5] 表明,用整首歌进行歌曲结构标注的效果优于分片段进行标注,因为更长的上下文有助于捕捉结构依赖。但 MuQ 和 MusicFM 均在 30 秒窗口上进行预训练,直接拉长推理窗口会因上下文不匹配导致性能下降。为了既用上强力的预训练表征又规避退化问题,我们采用了两种互补的时间分辨率来提取 SSL 表征。
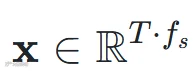 切成
切成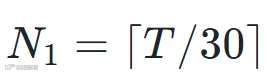 个 30 秒的片段,逐段过预训练编码器
个 30 秒的片段,逐段过预训练编码器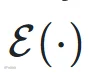 (MuQ 或 MusicFM),得到局部特征
(MuQ 或 MusicFM),得到局部特征 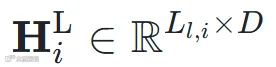 ,其中D=1024。
,其中D=1024。
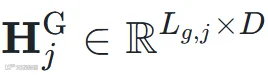 。
。
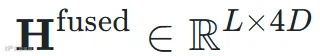 :
:
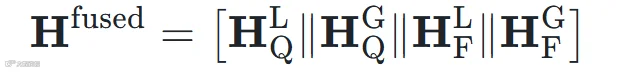
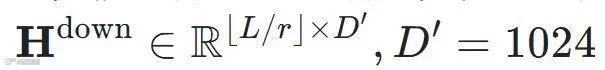 。
。
异构监督策略
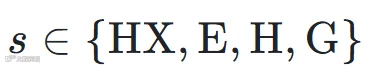 通过嵌入层映射为向量
通过嵌入层映射为向量 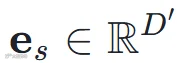 ,然后逐元素加到下采样后的表征上:
,然后逐元素加到下采样后的表征上:
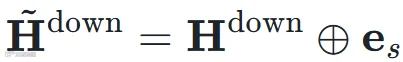
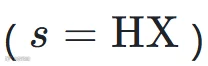 ,因为它有完整的八类标注,避免标签不匹配的问题。
,因为它有完整的八类标注,避免标签不匹配的问题。
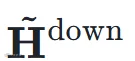 经 4 层 Transformer 编码器(隐藏维度512)建模长程依赖后,分别通过两个任务头预测帧级边界概率
经 4 层 Transformer 编码器(隐藏维度512)建模长程依赖后,分别通过两个任务头预测帧级边界概率 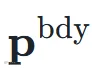 和功能标签概率
和功能标签概率 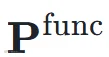 (共 8 类)。
(共 8 类)。
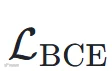 ,并引入边界感知的 1D 全变分损失
,并引入边界感知的 1D 全变分损失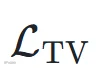 来抑制非边界位置的预测波动:对帧间差分施加
来抑制非边界位置的预测波动:对帧间差分施加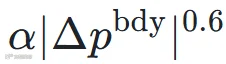 惩罚,边界区域附近
惩罚,边界区域附近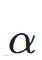 权重降为 0.1,其余为 1。功能标签预测则结合帧级交叉熵
权重降为 0.1,其余为 1。功能标签预测则结合帧级交叉熵 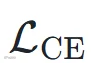 与 softmax focal loss
与 softmax focal loss 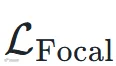 ,使模型更关注不确定帧。总损失为:
,使模型更关注不确定帧。总损失为:
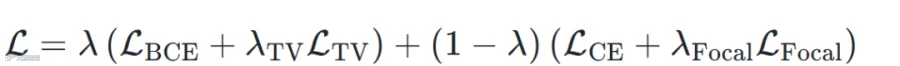
此外,针对不同数据集的标注差异,我们引入帧级任务 mask:SongFormDB-Hook 中功能标签损失仅在有效片段内计算,边界检测损失对应的有效窗口向两侧各扩展 5 秒;SongFormDB-Gem 则只计算功能标签损失,避免不准确的边界标注影响训练。
综上,SongFormer 通过融合多分辨率 SSL 表征、引入来源嵌入支持异构训练,结合高效且合理的训练目标和损失设计,实现了在大型异构数据上训练的歌曲结构标注模型,能够精确检测边界并准确预测功能标签,具备良好的泛化能力和计算效率。
数据集
我们采用了 [6] 中的映射规则,并保留了预副歌(pre-chorus)标签以更好地刻画歌曲结构之间的过渡关系。为了进一步缓解训练数据不足的问题,我们构建了 SongFormDB——一个大规模的歌曲结构标注训练集;以及 SongFormBench——一个配套的高质量评测基准。具体来说,从 HarmonixSet 中的 912 首歌曲中,我们随机选取 512 首用于训练,200 首用于验证,剩下的 200 首经过人工精细标注,形成了 SongFormBench-HarmonixSet。数据划分信息在发布时一并提供,以确保实验的可复现性。
表1 数据集统计。上半部分为 SongFormDB,下半部分为 SongFormBench。在 SongForm-Hook 中,仅有小部分歌曲片段被标注。
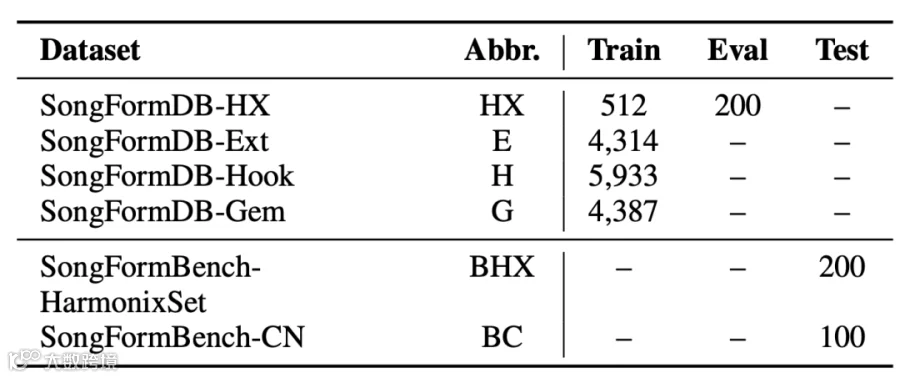
SongFormDB
SongFormDB-HX 从 HarmonixSet 中选取 512 首歌曲用于训练、200 首用于验证,并通过规则修正了一些标注错误(如将歌曲开头误标的 "尾奏" 改为 "前奏"、校准静音段时长等)。
SongFormDB-Ext 的结构标签基于文本-音频对齐的元数据生成,我们用 SOFA(Singing-Oriented Forced Aligner)检测对齐偏差,丢弃错误率超过 10% 的数据,最终保留 4,314 首对齐良好的歌曲。
SongFormDB-Hook 包含 5,933 首带有精确但不完整结构标注的歌曲,标注仅覆盖歌曲的部分段落,每个结构片段可能对应一个或多个功能标签,训练时随机选取其一。
SongFormDB-Gem 跨 47 种语言采样,覆盖多种风格,利用 Gemini 2.5 Pro Preview 生成结构标注。生成结果经过严格过滤(去除格式错误、时间戳非单调、总时长异常的样本),最终得到 4,387 条标注。我们观察到 Gemini 的边界预测较粗(误差可达 2 秒),但功能标签总体准确。因此我们只利用其功能标签,通过来源嵌入和禁用边界检测损失来处理这一特性,从而提升模型泛化能力。
SongFormBench
为了给未来的 MSA 研究提供公平的比较基准,我们构建了 SongFormBench,包含 HarmonixSet 的 200 首歌曲和 100 首中文歌曲。所有标注均由专家标注者基于原始音频和数据集标签进行严格交叉审核,同时参考了 MusixMatch、Genius 等公开元数据平台。此外通过音频指纹比对确保测试集与训练集无重叠。
实验
评测指标主要包括:
HR.5F,在 0.5 秒范围内边界检测正确的 F 值;
HR3F,在 3 秒范围内边界检测正确的 F 值;
Accuracy(ACC),衡量逐帧功能标签预测的准确率。
实验设置
训练集为 SongFormDB,测试集为 SongFormBench 和 RWC-Pop。预处理时,超过 420 秒的歌曲被切分为 420 秒片段,较短的保持原长。两个 SSL 模型均使用官方开源实现和默认预训练权重(MusicFM 使用 MSD 变体)。边界标签用覆盖前后各 10 帧(约 2.4 秒)的高斯核平滑。Transformer 编码器为 4 层、隐藏维度 512,训练 batch size 为 8,采用余弦学习率调度(峰值 1×10-4,300 步预热,12,000 步衰减至零)。若 HR.5F 或 ACC 连续三次验证未提升则触发早停。所有实验在单卡 NVIDIA L40 上以三个随机种子重复,报告平均结果。
评估方案
为了公平比较,我们将所有模型输出统一为 (起始时间, 标签) 格式,并沿用主流的七类评估方案。虽然 SongFormer 保留了预副歌(pre-chorus)作为第八类,但评估时将其合并入主歌(verse),因为此前的方法均只报告七类结果且部分未开源推理代码。评估在 SongFormBench(200 首英文、100 首中文)和 RWC-Pop(100 首标注歌曲)上进行。对于有开源代码的模型我们统一了输出格式之后测评;无法复现的模型则引用已发表的结果。
主要结果
如表2所示,SongFormer 在 SongFormBench 和 RWC-Pop 上的 ACC 和 HR.5F 均达到 SOTA,HR3F 也保持竞争力。
表2 模型在 SongFormBench 上的性能。* 表示来自原始论文的结果;(HX, E, H, G) 表示表1 中的训练数据集。
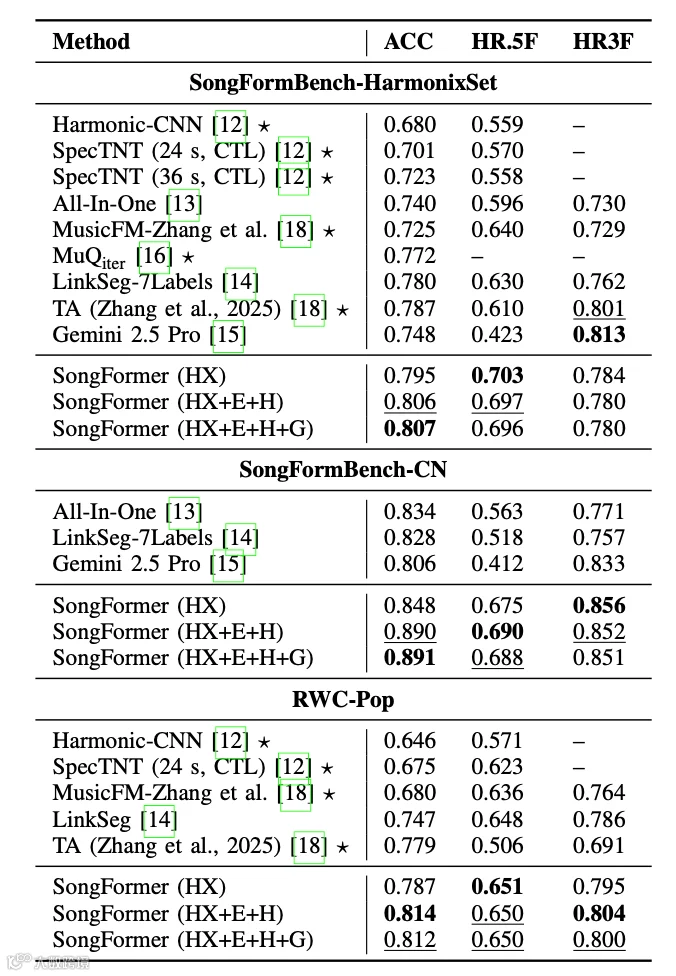
在 SongFormBench-HarmonixSet 上,SongFormer (HX+E+H+G) 的 ACC 达到 0.807,超过 TA (0.787) 和 LinkSeg (0.780);SongFormer (HX) 的 HR.5F 达到 0.703,大幅领先 LinkSeg (0.630) 和 All-In-One (0.596)。Gemini 2.5 Pro 虽然在宽松边界指标 HR3F 上略高 (0.813),但其严格边界精度仅 0.423,说明边界定位较粗。
在 SongFormBench-CN 上优势更加明显:ACC 最高达 0.891,HR.5F 最高 0.690,显著超越 All-In-One (0.563) 和 LinkSeg (0.518)。在完全未包含在训练数据中的 RWC-Pop,所有 SongFormer 变体也在全部指标上达到 SOTA,验证了泛化能力。
这些结果表明几个关键点:
SongFormer 的功能标签准确率和边界检测精度均优于现有方法。
仅用 512 首人工标注数据训练的 SongFormer (HX) 就已超越 Gemini 2.5 Pro 及所有基线,证实了性能提升源于架构设计本身,而非仅靠大规模数据堆叠。
从 HX 扩展到 HX+E+H+G 进一步提升了 ACC,但 HR.5F 因外部数据的时间戳不精确而略有下降——这正是来源嵌入所要缓解的问题。
尽管推理时固定使用 HarmonixSet 嵌入,模型在 RWC-Pop 和中文测试集上同样达到 SOTA,说明 HX 嵌入并非注入了"HarmonixSet 风格"的先验来刷分,而是实现了真正的跨数据集泛化。
同时如图3,得益于高效的架构设计与简洁的预处理流程,SongFormer 在所有对比方法中推理速度最快,具备良好的实用潜力。
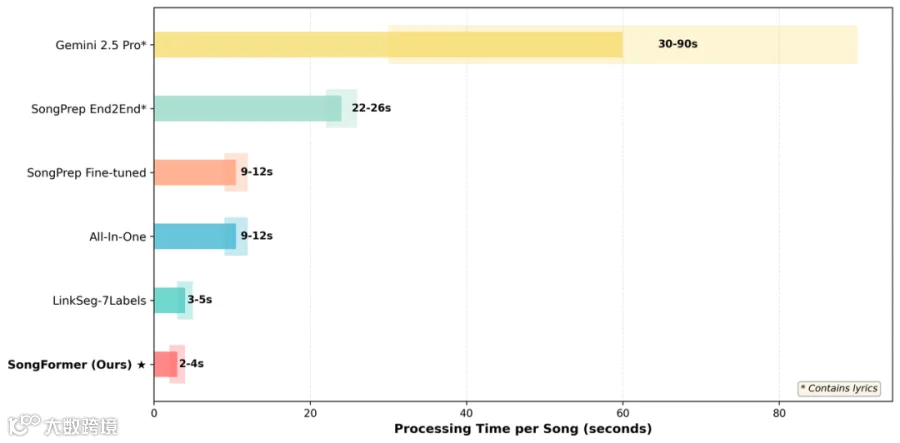
图3 每首歌曲在 SongFormBench-HarmonixSet 上的端到端平均推理时间,在单个 NVIDIA L40 GPU 上测量,涵盖从原始波形输入到最终结构化输出的完整处理流程。
消融实验
在图4(a) 中,我们在各 SSL 编码器的不同层特征上训练简单的 MLP + 任务头,发现 MuQ 和 MusicFM 均在第 10 层达到最佳性能,后续实验统一采用该层。图4(b) 通过调整下采样模块的 hop size 考察时间分辨率的影响:随着下采样因子增大,HR 持续下降,ACC 则先升后降,下采样因子为 3 时在效率和精度之间取得最佳平衡。
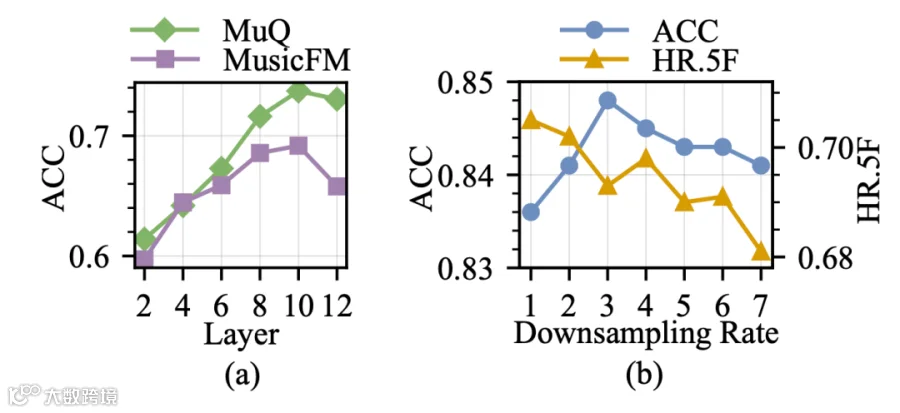
图4 表征层与下采样对模型性能的影响。(a) MuQ与MusicFM各层准确率对比。(b) 不同下采样率下的准确率与HR.5F指标。
表3逐一移除 SongFormer 的各组件,结果表明多分辨率表征融合、下采样模块、来源嵌入以及双编码器融合均对性能有显著贡献,每个组件都不可或缺。其中来源嵌入的作用尤为关键:面对异构训练数据中的标注噪声和质量差异,它让模型在训练时区分不同数据源,推理时则固定使用标注精确的 HarmonixSet 嵌入,从而既利用多源数据的泛化优势,又不受低质量标注的拖累。
表3 不同组件对模型性能的影响。Q:MuQ;F:MusicFM;M:多分辨率 SSL 表征;D:下采样策略;B:主干网络(T:Transformer,M:线性层);S:可学习的来源嵌入。
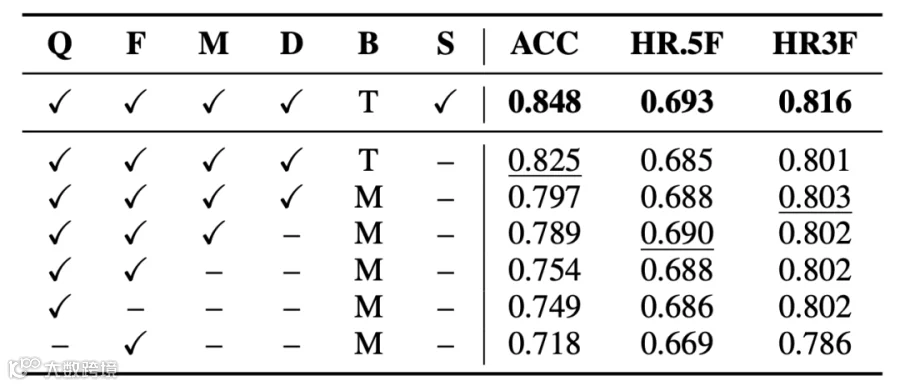
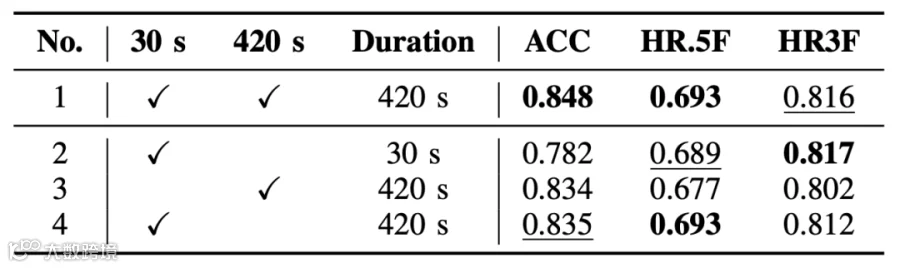
表4进一步分析了多分辨率 SSL 表征的效果。仅用 30 秒窗口的 SSL 嵌入输入 30 秒 SongFormer 时 ACC 最低,因为短窗口无法捕捉整曲上下文;将 SSL 窗口直接扩展到 420 秒虽然提升了 ACC,但 HR 下降,反映了推理窗口与 SSL 表征预训练窗口的不匹配。而将 30 秒嵌入拼接为 420 秒输入则带来显著提升——既保持了 SSL 推理与训练窗口的一致性,又支持长序列建模。在此基础上再融合 420 秒嵌入取得了最佳性能,验证了多分辨率策略的优势。
表4 SSL 表征(MuQ 和 MusicFM)在不同时间窗口配置下的性能。30 秒与 420 秒表示使用 30 秒或 420 秒的 SSL 表征,而时长则指 SongFormer 的输入时长。
总结
SongFormer 是一个可扩展且高效的 MSA 框架,融合了多分辨率 SSL 表征与异构监督策略。充分的实验和消融验证了模型的泛化能力及各组件的有效性。为缓解数据稀缺问题,我们同时发布了迄今最大的训练语料 SongFormDB 以及精心策划的评测基准 SongFormBench(200 首修订的 HarmonixSet + 100 首中文歌曲),推动 MSA 在音乐信息检索和可控音乐生成中的应用。
效果展示
体验地址:https://huggingface.co/spaces/ASLP-lab/SongFormer
输入: 完整歌曲音频(支持上传或录制)
输出: 歌曲结构标注结果(表格、JSON、MSA TXT 三种格式)
使用流程:上传或录制音频 → 点击"分析" → 2~4 秒内获取结果。页面底部还提供边界检测与功能标签的概率图,便于直观理解模型预测依据。
参考文献
[1] Ziqian Ning, Huakang Chen, Yuepeng Jiang, Chunbo Hao, Guobin Ma, Shuai Wang, Jixun Yao, and Lei Xie, “Diffrhythm: Blazingly fast and embarrassingly simple end-to-end full-length song generation with latent diffusion,” CoRR, vol. abs/2503.01183, 2025.
[2] Ruibin Yuan, Hanfeng Lin, Shuyue Guo, Ge Zhang, et al., “Yue: Scaling open foundation models for long-form music generation,” CoRR, vol. abs/2503.08638, 2025.
[3] Huakang Chen, Yuepeng Jiang, Guobin Ma, Chunbo Hao, Shuai Wang, Jixun Yao, Ziqian Ning, Meng Meng, Jian Luan, and Lei Xie, “Diffrhythm+: Controllable and flexible full-length song generation with preference optimization,” CoRR, vol. abs/2507.12890, 2025.
[4] Oriol Nieto, Matthew C. McCallum, Matthew E. P. Davies, Andrew Robertson, Adam M. Stark, and Eran Egozy, “The harmonix set: Beats, downbeats, and functional segment annotations of western popular music,” in ISMIR, 2019, pp. 565–572.
[5] Taejun Kim and Juhan Nam, “All-in-one metrical and functional structure analysis with neighborhood attentions on demixed audio,” in WASPAA. 2023, pp. 1–5, IEEE.
[6] Ju-Chiang Wang, Yun-Ning Hung, and Jordan BL Smith, “To catch a chorus, verse, intro, or anything else: Analyzing a song with structural functions,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 416–420.

欢迎关注ASLP实验室微信公众号,获取更多语音研究相关资讯!
“打造最开放、最前沿、最落地的人工智能实验室”
