
Google发布了Gemini 3.1 Flash Live,这是其目前最好的语音和音频AI模型。 它提供更快的响应速度、更自然的对话体验,以及可供开发者配置的思考级别。Google表示,该模型在检测音调和情绪方面表现更出色,在嘈杂环境中也更加可靠。该模型现已成为Gemini应用中实时模式的驱动力。

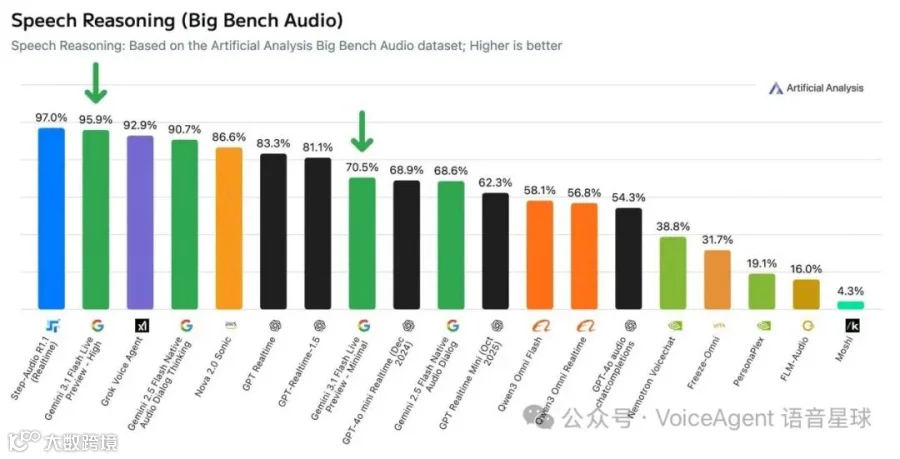
据Artificial Analysis的数据,该模型在"高"思考级别下在Big Bench Audio基准测试中得分95.9%,仅次于Step-Audio R1.1 Realtime(97.0%),响应时间为2.98秒。在"最低"思考级别下,质量降至70.5%,但响应时间缩短至0.96秒。
该模型通过Gemini Live API、Google AI Studio、Gemini Live以及Search Live在200多个国家可用。定价与其前代产品Gemini 2.5相同,音频输入每小时0.35美元,音频输出每小时1.40美元,使其成为市面上最便宜的音频AI模型之一。性能略优的Step Audio模型在输入价格上更便宜,但在输出价格上更高。
END
内容来源:VoiceAgent_AI

