

想象一下,你正坐在人声鼎沸的咖啡馆参加一场紧急的远程面试。背景里不仅有咖啡豆研磨机的轰鸣,还有邻座机械键盘那极其尖锐的敲击声——这种物理学上典型的“非稳态噪声”,往往是传统通信设备的噩梦。但在对方听来,你的声音却如同身处专业录音室般纯净。
这种“听觉奇迹”并非巧合,而是源于一场发生在语音机器人前端的“静音”革命。
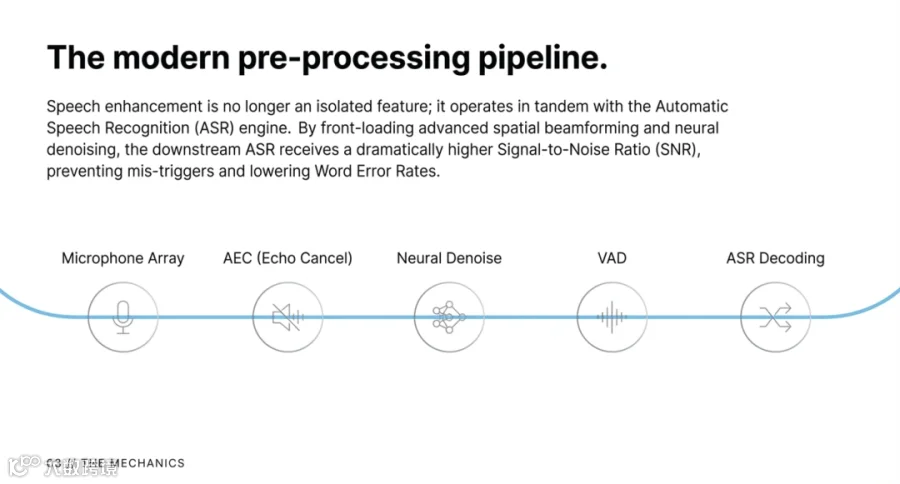
在你的声音进入语音转文字(STT)引擎之前,必须经过一套极度复杂的音频预处理流水线(Audio Pre-processing Pipeline)。这不仅是语音机器人的“耳朵”,更是决定人机交互能否在真实物理世界落地的核心技术护城河。

从“一半是科学,一半是艺术”到精准算法的跨越
在深度学习全面介入之前,音频降噪是传统数字信号处理(DSP)的领地。
其经典路径非常直观:通过语音活动检测(VAD)判断说话时机,在非说话间隙估算背景噪声的光谱,再利用谱减法(Spectral Subtraction)或维纳滤波将噪声频率从信号中“抠掉”。
然而,传统 DSP 存在一个致命的局限:它假设噪声是平稳的(如空调风扇声)。面对突然响起的狗吠、键盘声或鸣笛,传统算法因无法在短时间内准确建模噪声谱而彻底失效。
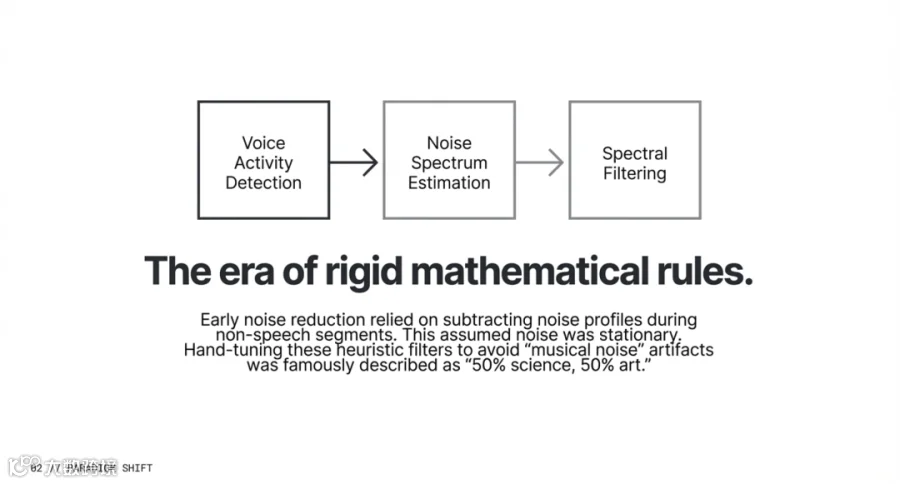
更棘手的是,传统方法的调试极其依赖人工经验,工程师需要针对成百上千个启发式参数进行微调。这种过程在行业内被戏称为“50% 的科学,加上 50% 的艺术”——参数稍重,人声就会产生诡异的“潜水音”失真;参数过轻,背景杂音又如影随形。
高效的秘密:当神经网络遇见经典物理学
AI 的介入彻底改写了游戏规则。但令人意外的是,最顶尖的系统并非昂贵的“全盘 AI 化”,而是选择了神经网络与经典物理学并行的“混合动力”模式。

这种模式的代表是 Jean-Marc Valin 提出的 RNNoise 架构。它摒弃了操纵每一个 FFT 频段的笨办法,而是采用 Bark 尺度(Bark-scale)增益(Gains)。

“保留所有基础的信号处理逻辑,但让神经网络去学习那些需要无止境手动微调的棘手部分。”
在这种哲学指导下,Amazon 的 PercepNet 更是将效率推向了极致。
它利用传统 DSP 的基音同步梳状滤波器(Pitch-tuned comb filter)来剔除谐波间的噪声,并通过 Viterbi 解码在极高噪声环境下锁定人声的基频(F0)。
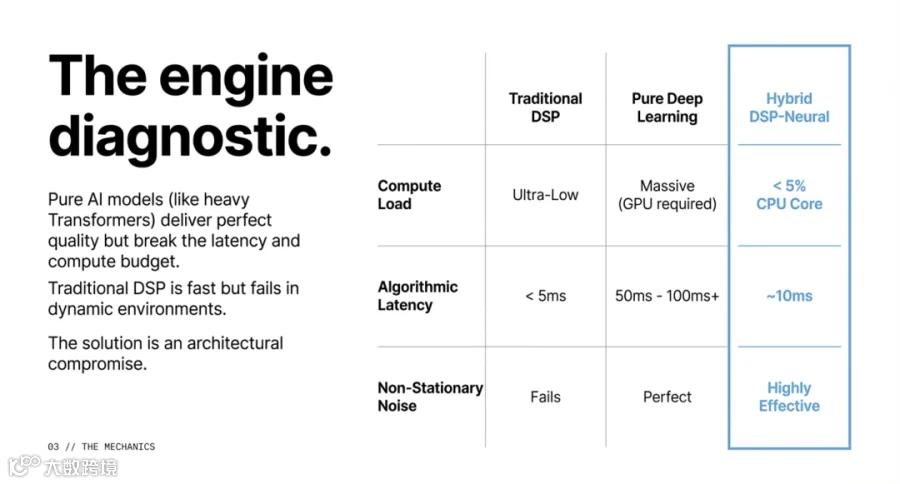
由于神经网络只需要处理复杂的非平稳特征,这种算法在移动设备上仅需消耗不到 5% 的 CPU 单核性能。与此同时,像 DeepFilterNet 这样更现代的框架,通过 ERB 尺度(ERB-scaled)的增益预测,实现了对频谱包络更精细的清洗。

与时间赛跑:200 毫秒的生死时速
对于语音机器人而言,降噪质量只是门槛,真正的挑战在于“毫秒级”的实时交互。

在实时交互中,端到端延迟的“生死线”是 200 毫秒。一旦超过这个数值,人类就会感知到明显的停顿,导致尴尬的“抢话”现象。
因此,音频预处理环节被压缩到了极致——算法延迟通常必须控制在 20 毫秒以内。
在这场博弈中,巨头们选择了不同的战略路径。Google Meet 偏向云端策略,通过其强大的服务器端 TPU 集群,在云端实时处理数千万用户的音频清洗;而 Microsoft Teams 则选择了客户端边缘计算策略。
为了在保护隐私的同时降低带宽成本,微软利用在 Azure GPU 集群上训练数日、涵盖了 100 多种噪声类型及数千名说话者的深度模型,直接在用户的本地设备上运行高度优化的神经网络。
巨头们的“静音”暗战:从工具到基准线
如今,降噪能力已不再是产品的“加分项”,而是衡量协作平台竞争力的基准线(Baseline)。这场看不见硝烟的军备竞赛正重塑行业版图:

Cisco(思科): 果断收购 AI 降噪先锋 BabbleLabs,将其整合进 Webex 生态。
Zoom: 从最初授权 Krisp 的技术,迅速转向自研算法,提供高精度的背景音抑制与增益控制。
NVIDIA: 凭借 GPU 算力优势推出 Maxine 平台,其 RTX Voice 技术通过张量核心(Tensor Cores)几乎能完全隔离背景中的音乐或近距离风扇声。
这种竞争背后的核心逻辑是:清晰的音频已成为企业级协同办公的数字基础设施。
不仅仅是静音:未来的“录音室级”体验
顶尖音频预处理的终极追求正从“去除噪声”转向“重塑感官”。这涉及两个硬核挑战:
回声消除(AEC)的“双讲”问题: 当机器人说话与用户说话重叠时,传统线性滤波器很难处理非线性失真。现代 AI AEC 能够消除残留的非线性回声,确保交互的流畅。
去混响(Dereverberation): 消除大房间内的声音反射。NVIDIA 的 “Studio Voice” 等技术能让廉价笔记本麦克风的声音听起来像是在吸音完美的录音室。

然而,技术专家也发现了一个有趣的心理现象:绝对的静默往往让人不安。因此,最先进的 AI 算法在清洗杂音的同时,会有意识地保留微弱的自然环境音或真实的笑声。这种“留白”艺术让远程互动保留了必要的“呼吸感”。

AI 与音频技术的深度融合,已将我们带到了一个新拐点:从“消除干扰”走向“重塑身份”。
当 AI 能够完美地捕捉并净化我们的声音,它实际上成了我们远程交互时的“数字皮肤”。随着这一技术在元宇宙和混合办公场景中的沉淀,高质量音频将不再取决于你身处的物理环境,而取决于你所使用的算法边界。

当声音技术最终消解了办公室与咖啡馆的物理区隔,我们是否已经准备好迎接一个工作与生活边界彻底模糊的清晰未来?
更多 DSP+NN 混合处理模式音频前端处理,请访问 - www.kardome.com
【免责声明】本文部分素材源自网络,版权归原作者所有,分享仅用于学习,对文中所述观点声学楼保持中立态度。若您认为本文侵权或文中描述与事实不符,请及时告知删除或修订,感谢大家的关注与支持!
