
在传统的音频信号处理领域,评估算法好坏通常有一套“标准答案”。比如在通信降噪任务中,我们有纯净的原始录音,只要计算处理后的音频和原始音频的差异(如 PESQ 、PEAQ 或 STOI 指标),就能得出一个客观分数。这在本质上,是在做数学上的距离度量。
但在生成式 AI时代,这个逻辑失效了。
当你让模型“生成一段下雨时的爵士钢琴”时,不存在一段“标准”的录音供你对比。模型生成的音频是全新的。这就引出了一个棘手的问题:在没有参考答案的情况下,机器如何判断一段音频的质量?
Meta 提出的 Audiobox Aesthetics,正是试图解决这个问题的框架。它并不是什么拥有“灵魂”的鉴赏家,而是一套基于深度学习的、试图将主观审美“参数化”的预测系统。
对于工程师而言,理解这个框架的核心在于理解它如何将模糊的“好听”解构为可量化的指标。
核心理念:将“质量”正交分解
如果直接训练一个模型去预测“这段音频好不好”,效果通常很差。因为人类的反馈极其嘈杂:有人打低分是因为有噪音(技术问题),有人是因为不喜欢这种音乐风格(审美问题),还有人是因为觉得太单调(内容问题)。
Meta 的做法是将“音频质量”拆解为四个尽量互不干扰(正交) 的维度。这类似于我们在做系统监控时,不会只看一个“系统健康度”,而是会拆分为 CPU、内存、IO 和 错误率分别观察。
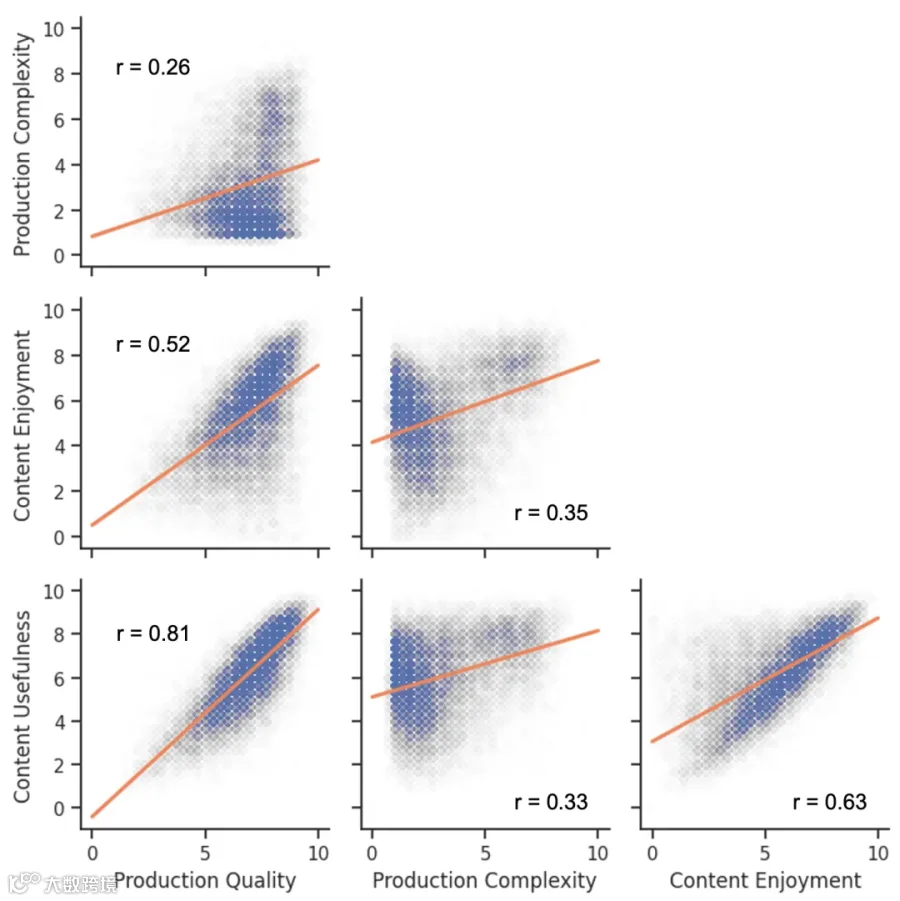
这四个轴(Axes)分别是:
-
制作质量 (Production Quality, PQ)
-
定义:只关注信号层面的技术指标。是否有底噪?是否有麦克风削波?是否有压缩伪影? -
工程视角:这最接近我们熟悉的“信噪比”或“录音保真度”。一段录制完美的“指甲刮黑板”声音,它的 PQ 应该是满分,即便它听起来很痛苦。 -
制作复杂度 (Production Complexity, PC)
-
定义:音频中包含了多少声学事件?是单人清唱(低复杂度),还是交响乐团合奏(高复杂度)? -
为什么要拆分这个? :这是一个非常聪明的“去混淆”设计。在以往的测试中,模型容易误以为“越响、越复杂 = 质量越好”。将复杂度独立出来,是为了告诉模型:极简风格不代表低质。 -
内容愉悦度 (Content Enjoyment, CE)
-
定义:纯粹的主观审美。旋律是否抓耳?音色是否讨喜? -
难点:这是最难建模的维度,因为它不仅取决于音频本身,还取决于听众的文化背景。模型在这里学习的其实是“大众审美的统计平均值”。 -
内容可用性 (Content Usefulness, CU)
-
定义:这段音频在实际生产(如视频配乐、声音设计)中是否有用? -
场景:一段充满了风噪和呼吸声的现场录音,PQ(音质)可能很低,CE(好听)也不高,但如果它真实记录了某个历史时刻,它的 CU(可用性)就是极高的。
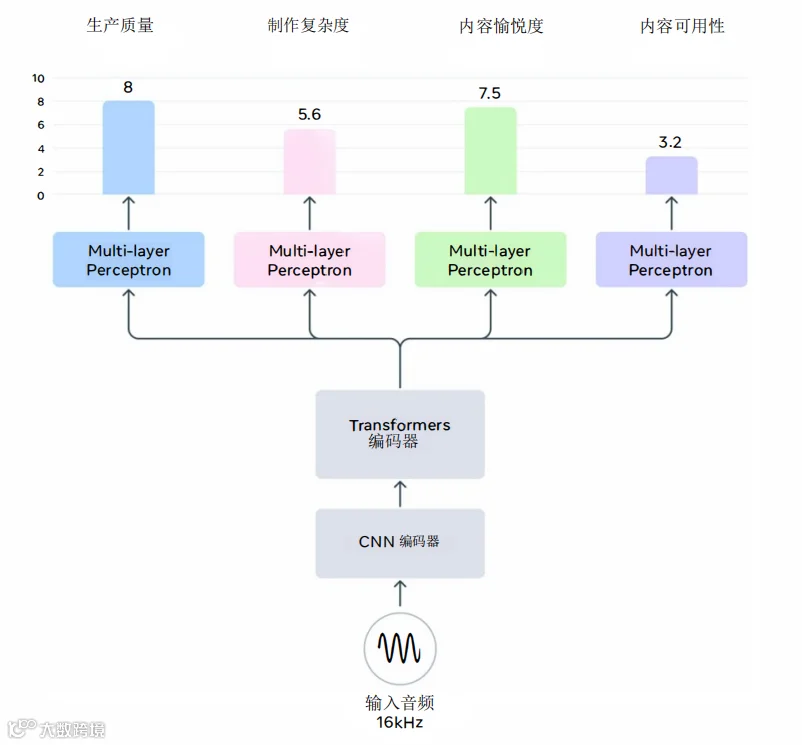
实现原理:基于 WavLM 的监督学习
Audiobox Aesthetics 不是依靠借助常规算法的规则引擎实现的,它是一个经过训练的神经网络。
-
骨干网络 (Backbone) :它使用了一个预训练好的 WavLM 模型。WavLM 是目前语音/音频领域非常通用的特征提取器(类似于 NLP 里的 BERT)。它已经在海量(9.4万小时)的音频数据上“听”过各种声音,因此具备了很好的声学特征提取能力。 -
数据工程:模型的效果取决于数据。Meta 构建了一个名为 AES-Natural 的数据集,包含约 10 万条音频。 -
抗噪机制:为了防止众包人员乱打分,他们引入了“黄金集(Golden Set)”校验。只有当标注者对专家已打分样本的判断与专家高度一致(相关系数 > 0.7)时,其数据才会被采纳。这是非常典型的数据清洗手段,保证了真实标签的相对纯净。
这东西有什么用?
了解这个模型不仅仅是为了发论文,它在实际的 AI 工程链路中有两个核心用途:
A. 数据清洗
目前训练像 AudioLDM 或 MusicGen 这样的大模型,数据量通常在 TB 级别。里面混杂着大量低质量音频。依靠人工筛选是不可能的。
工程师可以使用 Audiobox Aesthetics 对原始数据进行“跑分”,设置一个阈值(例如设置制作质量评分 PQ > 8.0),自动剔除低质数据。实验证明,用高质量数据训练出的模型,生成效果会有显著提升。
B. 可控生成 (Controllable Generation)
这是个很有意思的 Trick。在训练生成模型时,可以把这四个分数作为条件喂给模型。
在推理(生成)阶段,我们可以人为地设置 Prompt:“生成一段钢琴曲,并要求 Quality = 10”。这相当于给模型施加了一个梯度的指引,强迫它去潜在空间中寻找那些被标记为高质量的特征分布。
局限性与现实
虽然 Audiobox Aesthetics 提供了一个很好的框架,但由于音频美学与质量中的主观性,其依旧有不少局限性:
-
泛用性较差:模型的结果和人主观评价的相关性并不明显,并且由于数据集的限制,其难以在细分领域代替金耳朵,如声学产品的产线质检。 -
采样率瓶颈:由于底层的 WavLM 模型主要面向语音任务,它通常工作在 16kHz 的采样率下。这意味着它无法感知 8kHz 以上的高频信息(如镲片的泛音、空气感)。对于 Hi-Fi 音乐评估,它是有生理缺陷的。 -
缺乏长时记忆:模型通常只分析 10 秒左右的片段。它无法理解一首 3 分钟歌曲的结构起伏。一段无限循环的 10 秒好旋律,模型会给高分,但人类听久了会觉得单调。 -
平均化的平庸:模型预测的是“平均审美”。过度依赖它可能会导致生成的内容越来越“像”商业流行音乐,而抹杀掉那些风格独特但小众的艺术表达。
总结
Meta Audiobox Aesthetics 本质上是将主观的听觉感知,通过大规模数据监督,映射到了四个客观的向量空间上。
对于开发者来说,它提供了一种在没有“标准答案”的情况下,自动化监控和提升生成式音频质量的有效手段。虽然它并不完美,但在目前 AIGC 评估手段匮乏的荒原上,也是一个可以利用的工具。
作者:Andros Tjandra
标题:Meta Audiobox Aesthetics: Unified Automatic Quality Assessment for Speech, Music, and Sound
原文链接:https://arxiv.org/abs/2502.05139

