

导读
本文主题为 DeepSeek 不懂 MCTS?一文看懂大模型训练的“烧鸡与烧酒”困局。
1. 风头无两的开端
2. 先天不足的遗憾
3. 一时瑜亮的方法
4. 路径融合的样例
分享嘉宾|梁天新博士
出品社区|DataFun
01
风头无两的开端
常做领域模型的算法工程师常会提出这样的疑问:为什么自家训练出来的模型,回答效果没有豆包好?明明自家实际掌握了更多领域的关键知识,比如上万份领域问答,无论通过 RAG 还是 SFT,都已经将领域信息注入了模型。
实际上,所谓的训练 SFT 是将问题和答案分别对应种子和果实两端。如果单纯将这两者放在 SFT 的两端进行训练,那只是一种函数映射。真正要做的应该是从输出中提炼摘要作为答案,而 CoT(Chain of Thought)正是连接种子和果实的树干。想做出好的回答,必须在 CoT 阶段有足够的信息为 answer 打基础。CoT prompting 是 Google 发明的(2022),长推理+RL 强化是 OpenAI o1 率先商用的(2024),但 DeepSeek-R1 是开源社区第一个大规模、可复现地把“长 CoT”玩到顶级水平、还把流程全公开的。
那么问题就回到:如何构建一个最好的 CoT 模型?2025 年的 DeepSeek 给我们做了最详尽的解答,下面笔者将按照自己的理解简述 DeepSeek 的做法。
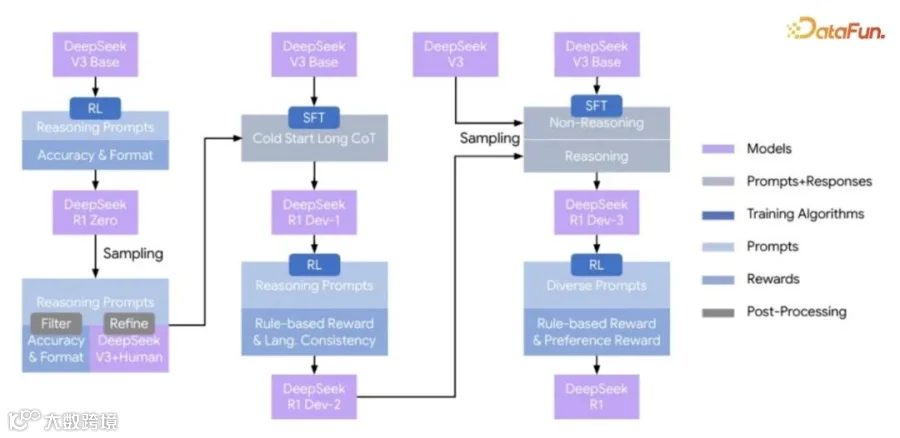
首先看看 DeepSeek 是怎么点石成金的。从论文中看到,原始的 DeepSeek V3 Base 是一个掌握领域知识、具备理解提示词指令的 SFT 模型,勉强能生成 CoT,但不够“积极”。因此他们对模型使用了 GRPO 增熵方法,迫使模型多思考,然后择优录用,最终使模型养成爱思考的能力。以笔者的实验来看,只要训练 1000 步 GRPO,无论给出怎样的 answer 限制,模型都会“积极”地输出思考过程,并且对已经进行过 SFT 训练的模型依然有效。只要经过 GRPO 训练,模型就能成为 CoT 产出模型。DeepSeek R1 Zero 就是这样的产物,具备被激活的 CoT 能力,但其 CoT 组织常常缺少逻辑。比如 DeepSeekMath 的 GRPO 主要基于最终结果(答案正确与否)来给奖励,问题在于:如果推理过程有一步错了,但运气好蒙对了答案(False Positive),GRPO 可能会错误地强化这个过程,模型就学会了“蒙”而不是“推”。
按理说这个环节应该引入 PRM 过程奖励优化,但 DeepSeek 没有这么做,而是采用了 RFT 拒绝采样微调。拒绝采样的大白话解释是:
1. 生成:同一个问题,用模型生成 N 条推理回答;
2. 验证:把这 N 个回答拿去验证(通常通过结果对错验证,因为推理过程难以自动化验证);
3. 拒绝:答案错的全部扔掉;
4. 保留:如果剩下 M 个答案是对的(且推理看起来合理),就把这 M 个作为训练数据。因此从上图看到,被激活的 DeepSeek R1 Zero 成了一个发动机,不停制作新的 CoT 数据来满足拒绝采样微调的数据收集。根据笔者的经验,尽量使用 DeepSeek R1 Zero 生成的 CoT 数据作为下一次 cold start long CoT 的数据,而不是人为编撰的 CoT。笔者将其命名为“大模型的反刍”,好比牛会将未消化的草重新咀嚼后再次进入胃里。大模型在冷启动训练中更喜欢自己构造的正确 CoT,而不是人工编撰的。至此,DeepSeek 将原始的 20 万训练数据扩展到了 80 万的 CoT 数据。
然后他们开启了第二段训练。既然已经有了更好的 CoT,就先做 2 个 epoch 的 SFT。以笔者的工程经验看,最好就是 2 个 epoch,因为过多 epoch 会导致模型熵过分塌缩,使后续的 GRPO 无法激活。从中间这幅图看到,经过两个 epoch 的模型再次使用 GRPO 进行激活,这次训练获得的 DeepSeek R1 Dev-2 具备了更好的语言一致性,讲话更有条理。
第二段训练完成后,就要接近收尾工作:让 DeepSeek R1 Dev-2 作为发动机,不停制作具有良好语言一致性的 CoT 数据,同时使用原始的 DeepSeek V3 Base 提供更精准的问答数据。在这两类大数据下,再次从 DeepSeek V3 Base 蒸馏出既具备原始知识、也具备 CoT 输出的模型,至此知识注入正式完成。即便如此,我们回到了 SFT 模型,想将其在线上应用,还需要第三次 GRPO 激活,让其具备更好的指令遵循能力。这最后一次 GRPO 训练获得了 DeepSeek R1。
02
先天不足的遗憾
尽管带有可验证奖励的强化学习(RLVR)已成为开发语言模型高级推理能力的关键组成部分,但当代研究表明,经过数千次优化步骤后会出现训练瓶颈:计算投入不断增加,性能提升却显著放缓。这一局限性源于当前 RLVR 实践中固有的稀疏探索模式——模型依赖有限的回溯,常常错过关键推理路径,无法对解决方案空间进行系统性覆盖。
DeepSeek 虽然采用 RL 训练出强推理模型去做拒绝采样,生成 60 万条高质量 CoT,再混入 20 万非推理数据进行 SFT,以此巩固推理能力并防止模型崩坏,但这种方法仍然存在“蒙”的可能。没有经历过过程验证的模型,始终存在缺憾。同时,60 万条高质量 CoT 的构建过程中包含了大量人工挑选,离端到端地制作出领域模型还很远。那么,DeepSeek 为什么不采用具备自我验证能力的蒙特卡洛树搜索(MCTS)作为数据生成的方法呢?原因在于他们尚未掌握这一技术。DeepSeek 在论文中大方地承认了这一点:“Monte Carlo Tree Search (MCTS) failed to deliver results in general reasoning tasks”;“these two routes (MCTS and PRM) were the hottest research directions in the industry in the past year. The result was that they didn’t work, at least not in general reasoning tasks。”他们坦言,与国际象棋等棋类游戏不同,LLM 的 token 生成呈现指数级搜索空间,无法像 AlphaGo 那样高效展开。MCTS 依赖好的价值模型来指导搜索,但训练这样的价值模型本身极具挑战,难以形成“搜索→改进模型→更好搜索”的正向循环。
笔者认为所谓“拒绝采样微调”的说法是有待商榷的。因为在大规模采样中我们仅仅是过滤掉部分数据,而非整体拒绝,因此称为“过滤采样微调”似乎更加合理。为保持前后一致,本文依然使用“拒绝采样微调”。
03
一时瑜亮的方法
正所谓,死店活人盘。DeepSeek 不懂如何用 MCTS 构造数据,但 Google 懂。自从收购 DeepMind 后,Google 自然成为了 MCTS 方法的大宗门。Google 在 PRM 的探索中便公布了如何将 MCTS 应用于数学问题的采样中(论文:Improve Mathematical Reasoning in Language Models by Automated Process Supervision)。在不需要任何人工干预的情况下,将指令微调后的 Gemini Pro 模型在 MATH 基准测试上的准确率从 51% 提升至 69.4%(相对提升 36%)。在 GSM8K 上,准确率从 86.4% 提升至 93.6%。
Google 的研究人员提出了名为 OmegaPRM 的算法,其核心创新在于将 MCTS 用作一个离线的数据生成引擎,而非在线推理工具,自动生成用于训练过程奖励模型(Process Reward Model, PRM)的“过程监督数据”。
方法:采用“分而治之”的 MCTS 算法。
- 二分搜索找错:对于一条思维链(CoT),通过二分搜索快速定位第一个逻辑错误的步骤。
- 平衡正负样本:在搜索树中,算法会自动平衡正确推理路径和错误推理路径的收集,保证训练数据的质量。
- 高效产出:通过这种方式,Google 完全自动化地收集了超过 150 万个过程监督标注。
在这种模式下,MCTS 不是为了在推理时现场搜索最佳答案(那是 AlphaGo 的做法),而是利用 MCTS 的搜索能力,探索出高质量的分步推理路径,将这些路径作为标准答案(Ground Truth)去训练一个更轻量的 PRM 或直接微调模型。可以说 Google 在 2024 年 6 月部分解决了数学问题下如何构建无人工干预的拒绝采样数据,而此时的 DeepSeek 仍在用人工标注构建拒绝采样数据。但是谷歌也未发现 GRPO 算法,导致其在构建 CoT 时缺乏“多想一步”的能力。好比吃饭,Google 是有烧鸡没烧酒,DeepSeek 是有烧酒没烧鸡。至于 2025 年 1 月之后 Google 是否有所突破,则不得而知。
为什么我们在构建 CoT 模型时需要拒绝采样数据?为什么我们不能只看结果?我们来看两个例子:
- DeepSeekMath 的 GRPO:主要基于最终结果(答案正确与否)来给奖励。问题:如果推理过程有一步错了,但运气好蒙对了答案(False Positive),GRPO 可能会错误地强化这个过程。模型就学会了“蒙”,而不是“推”。
- OmegaPRM 的过程奖励模型(PRM):给每一步打分。厉害之处:它能精确地揪出“过程错误”,显著减少了“运气好蒙对”的情况。对于复杂的长链条推理(如奥数题),这种步步为营的反馈远比只看结果有效。
这正是我们强调“拒绝采样”的深层原因——我们要的是每一步都正确的推理,而不是侥幸的答案。只有通过过程监督,才能杜绝“熵塌缩”——那种模型输出越来越随机、越来越敷衍的退化现象。
04
路径融合的样例
若想探究 MCTS 的成功案例,笔者建议大家下载 KataGo 的开源代码。此代码复现了 AlphaGo 的 MCTS 精髓,能让我们在理解 MCTS 时有现实基础。再深究 KataGo 中的自博弈训练时,你会发现 MCTS 是深度参与的。也就是说,MCTS 充当了数据构建的关键部分。蒙特卡洛树搜索通过模拟多条路径、评估每个节点的价值,天然地产生多样化的思考轨迹。
我们可以用 MCTS 来替代传统拒绝采样中的数据生成:
- 对于同一个问题,MCTS 探索不同的推理路径,记录下每个分支的思考过程和最终结果。
- 通过剪枝和回溯,我们能筛选出那些真正导向正确答案的路径——而且这些路径往往不是最短的,也不是最容易的,而是经过了充分权衡的。
- 蒙特卡洛剪枝(即 MCTS 中的剪枝策略)实际上契合了“拒绝采样”的思想:保留高价值分支,剪掉低价值分支。
这样构建出来的数据,天然包含了多条正确的推理路径。用它来训练模型,模型就能学会从多个角度思考问题,而不是死记硬背单一线索。
具体操作上,DeepSeek R1 Dev-2 符合我们的要求。此处我们可以将图一中的第二步骤重新做一遍:在解决复杂问题时,使用 MCTS + DeepSeek R1 Dev-2 的方式构建拒绝采样数据。具体来说,强制 DeepSeek R1 Dev-2 作为大脑,列出解决问题的几个步骤,然后让 MCTS 不断检查推理的结果是否正确。如果不正确,则进行回溯生成,最终获得多条直通答案的 CoT 思考路径。这将同时满足两个需求:第一,大模型反刍,即大模型用自己思考的数据训练自己;第二,无人工干预,生成推理路径。通过二者的结合,在构建领域模型时我们将采用如下办法:
- 获得一个 DeepSeek R1 Dev-2;
- 构建问答对,问题中可以包含提示词,答案选择自己最满意的;
- 使用 MCTS + DeepSeek R1 Dev-2 的方式构建拒绝采样数据;
- 先进行 2 个 epoch 的 SFT 训练;
- 使用获得的全部数据进行 GRPO 训练,获得自己的领域 DeepSeek R1。
最后,笔者建议各位算法工程师,既然 DeepSeek 已经向我们证明:拒绝采样+SFT+GRPO 是可行的,那么在现实的项目中可以在不满意的情况下反复使用这种方式,通过迭代达到自己心中的最优标准。

往期推荐

点个在看你最好看
SPRING HAS ARRIVED
