
摘要
多模态大语言模型在临床视觉问答中具有应用潜力,但扩展至三维成像时受限于高计算成本。传统2D切片法或固定长度Token压缩会破坏3D数据连续性,丢失细微病灶等关键信息。
本研究提出可变长度Token表征框架,通过指令条件Token调度机制与代理梯度传播策略,自适应减少冗余Token,在降低计算开销的同时缓解注意力稀释问题。该框架采用带梯度恢复的自定义反向传播,确保离散Token剪枝的可微优化,并引入正则化目标弱化语言模态偏置。实验表明,在多种医学视觉问答任务中,该方法显著降低资源消耗并加速训练推理,同时保持高准确率。

图1:3D原生框架通过自适应Token压缩实现高效医疗视觉问答
论文链接:https://arxiv.org/pdf/2603.25155
引言
人工智能已在临床影像解读中发挥作用,但现有模型多面向2D图像。对于常见的3D CT、MRI数据,在保持完整3D Volume的前提下控制显存与计算量仍是难题。
传统方法依赖2D切片选取或固定长度Token压缩,虽降低序列长度,却破坏三维连续性、抹平细小病灶,并引入人工裁剪偏差。不同临床问题的信息需求差异显著,统一压缩比例难以平衡精度与效率。本文提出3D原生框架,直接以3D Patch为单元建模,通过可变长度Token序列自适应保留关键信息。
3D医学数据建模挑战
三维医学影像建模面临三大挑战:
第一,体素数量庞大。以常规胸部CT为例,划分为3D Patch后Token数量远超二维图像,直接输入将超出常规硬件配置。
第二,三维结构与局部细节关键。病灶跨层延展、器官边界形态等依赖跨切片关系,裁剪或下采样会削弱复杂任务(如肿瘤评估)所需信息。
第三,临床指令差异显著。异常筛查仅需整体判断,而病灶测量需精确定位。固定Token压缩比例无法适配不同任务的信息需求。
该框架核心目标是在3D原生表示下,按指令自适应决策Token保留量与位置。
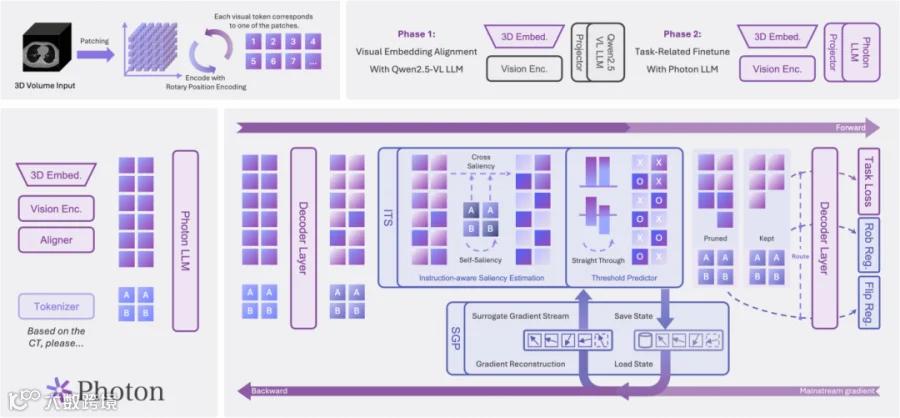
图2:工作流分为两阶段:第一阶段对齐视觉嵌入层,第二阶段微调适配任务
3D原生框架设计
指令条件Token调度(ITS)
框架将3D Volume划分为非重叠Patch,通过3D编码器生成视觉Token序列,并与语言Token序列拼接。ITS机制包含两步:
1. 指令显著性估计:分析指令内部Token重要性,计算各视觉Token与关键指令成分的对齐程度,生成显著性分数。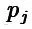
2. 自适应阈值预测:轻量感知机基于整体显著性分布与指令语义,动态确定样本级保留比例。在简单任务中保留较少Token,复杂任务中保留更多关键区域Token。
代理梯度传播(SGP)
SGP解决硬剪枝导致的梯度中断问题:
前向计算采用硬剪枝,剔除未保留Token及其缓存,真实降低计算量;反向传播时,通过一阶泰勒估计构造Token任务重要性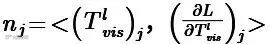 ,驱动保留概率更新。该机制使Token选择与任务损失紧密耦合。
,驱动保留概率更新。该机制使Token选择与任务损失紧密耦合。
实验结果与分析
框架采用两阶段训练:
第一阶段:对齐3D视觉表示与语言空间,轻量训练3D patch嵌入层。
第二阶段:在3D-RAD、DeepTumorVQA等基准任务上微调,优化Token选择策略。
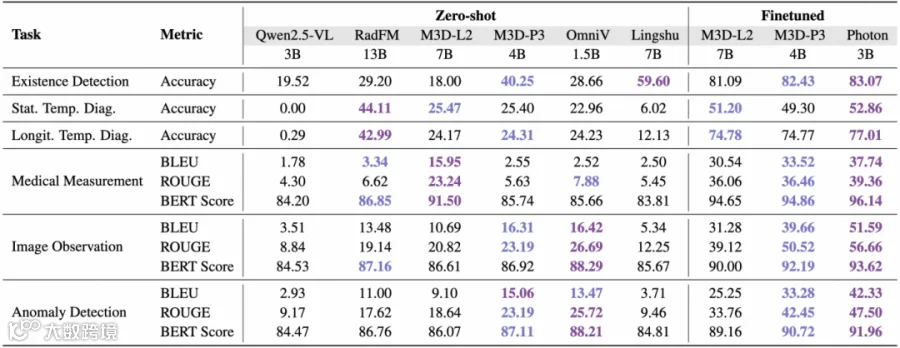
表1:3D-RAD基准测试性能(紫色/靛蓝标最优/次优结果)
在3D-RAD与DeepTumorVQA多任务测试中,该框架优于现有3D医学多模态基线模型(含更大参数规模模型),尤其在肿瘤检测、测量及纵向变化分析任务中表现突出。
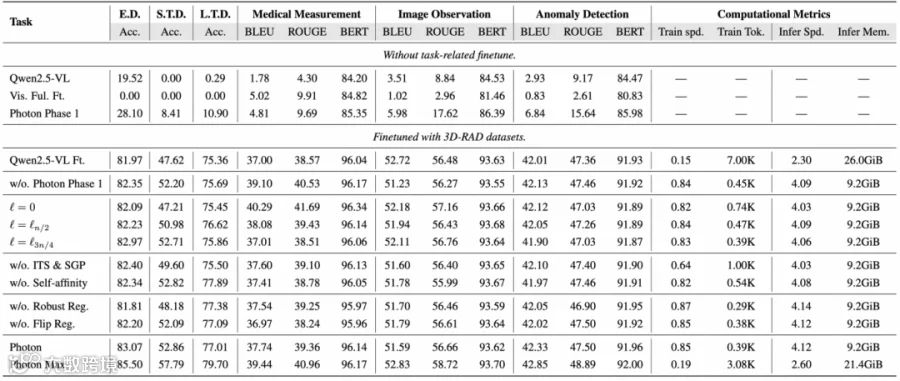
表3:消融实验显示显存占用降低38%,推理速度提升42%
通过指令自适应Token裁剪,在保持高精度的同时,训练迭代速度提升35%,推理时GPU峰值内存降低38%。可视化分析证实剪枝行为精准保留临床关键区域(图3),非盲目压缩。
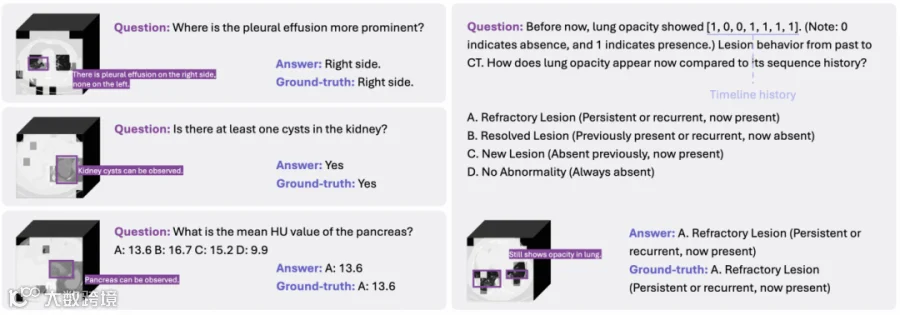
图3:白色区域为裁剪Token,紫色框突出保留的关键临床区域