
编者按
本篇为ArangoDB入门基本操作类文章,将会从实用性角度出发,介绍ArangoDB基本概念及特性,ArangoDB安装,以及如何使用web端,命令集, Rest API进行ArangoDB基本操作,满足我们日常工作所需,提高工作效率。

关于ArangoDB
ArangoDB是一个开源的分布式原生多模型的NoSQL数据库。支持图 (graph)、文档 (document)和键/值对 (key/value) 三种数据模型,将数据存储在文档中,文档是由键值对组成的任意数据结构,且该值可以是任何数据类型,甚至另一个文档。且提供了涵盖三种数据模型的统一的数据库查询语言AQL。
以下引用于cnblogs的ArangoDB相关特性。➀
多模型数据库:可以灵活的使用键值对、文档、图及其组合构建你的数据模型。
查询便利:ArangoDB有类SQL的AQL查询语言,还可以通过REST方式进行查询。
可通过JavaScript进行扩展:无语言范围的限制,可以从前端到后端都使用同一种语言。
高性能:ArangoDB速度极快
Foxx- 构建自己的API:用JavaScript和ArangoDB构建应用,Foxx运行在DB内部,可快速访问数据。
空间利用率高:跟其它文档型数据库相比,ArangoDB占用的存储空间更少,因为ArangoDB是模式自由的元数据模式。
简单易用:ArangoDB可以在几秒内启动运行,同时可使用图形界面来管理你的ArangoDB。
多OS支持:ArangoDB支持Windows、Linux和OSX等操作系统,还支持树莓派。
开源且免费:ArangoDB开源免费,它采用了Apache 2许可证协议。
复制:ArangoDB支持主从集群。
而以下为个人理解ArangoDB更为具象性的优点。
ArangoDB包含键值对、文档、图三种数据模型,我们而无需再学习redis,MongoDB,Neo4j等等单一数据模型数据库;可减少大量学习及开发,运维成本。
作为NoSQL数据库,ArangoDB无需预先定义数据结构,可轻松存储和结合任何结构的数据,而无需开发人员花费大量时间优化表结构;
更具灵活性,快速响应需求变化(新功能,数据模型的变化等);做到不停服状况下,更改数据模型。
支持水平扩展,而无需每添加一个节点,都要手动将完整数据集复制到每台机器。
拥有MMfiles及RocksDB➁,两种存储方式;RocksDB偏向于支持超过内存的大数据集的存储,高速、稳定的写入性能;内存映射文件存储引擎为适合存放于内存的数据而优化设计,能够支持快速的并发读。用户能根据项目偏向读系统或写系统自由选择存储方式。(ArangoDB3.4版本默认存储方式为RocksDB,过往版本默认为MMfiles)
拥有可涵盖三种数据模型的统一查询语言AQL,AQL类似于函数,有编程背景的人都能快速接受。
安装ArangoDB for mac
在MacOS上安装ArangoDB,可选方式有三种,命令行应用程序(tar包),图形应用程序(dmg包)及brew安装。
包下载地址:
https://www.arangodb.com/download-major/macosx/
我平时用到较多的为brew安装。
安装:brew install arangodb
配置文件夹:/usr/local/etc/arangodb3/
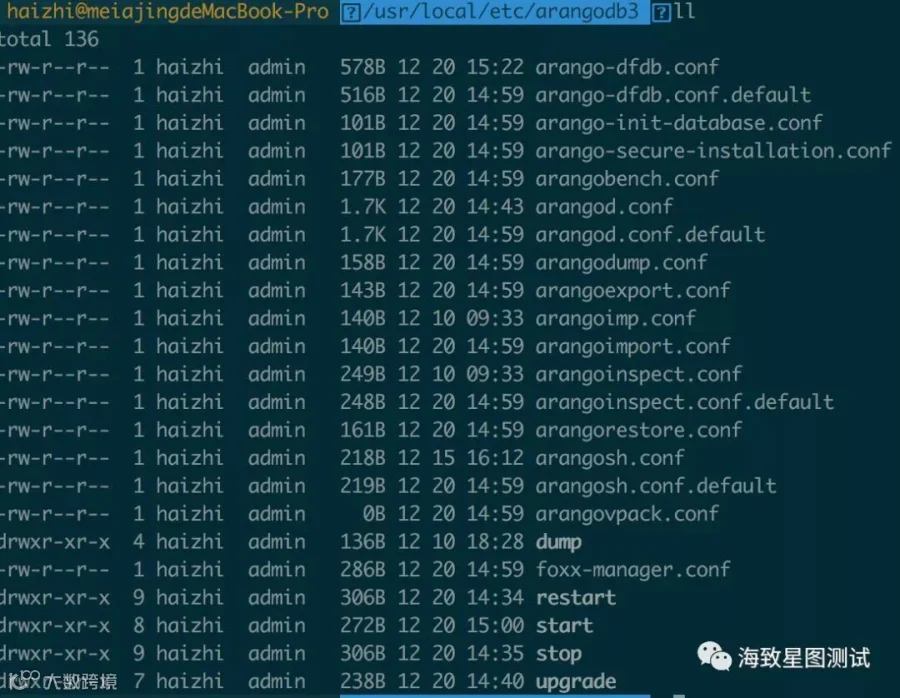
服务器文件夹:/usr/local/sbin/arangod
服务log文件夹:/usr/local/var/log/arangodb3
启动服务:/usr/local/sbin/arangod &
或 /usr/local/sbin/arangod start
停止服务:Control + C
启动过程中遇到以下类似数据库版本过低错误:
Database directory version (30320) is lower than current version (30400),
运行/usr/local/sbin/arangod --database.auto-upgrade true即可。

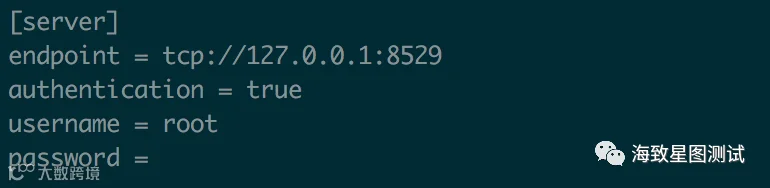
配置访问路径:
endpoint = tcp://127.0.0.1:8529
启动成功后我们可以通过以下地址,访问web端:http://127.0.0.1:8529
ArangoDB web端基本操作
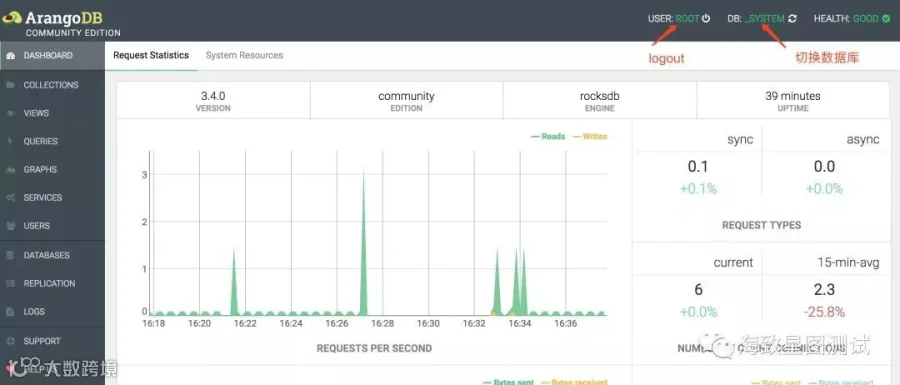
打开web页面,先需登录,mac版ArangoDB,默认用户root,密码为空,数据库为_system;_system 是 ArangoDB 系统级的数据库,通过该数据库来管理用户及数据库数据。 不建议直接在该库存储业务数据,应要为每个业务创建单独用户和数据库。登录成功后,我们可以看到以下界面。
DASHBOARD栏:定期轮询ArangoDB服务器的统计信息仪表盘
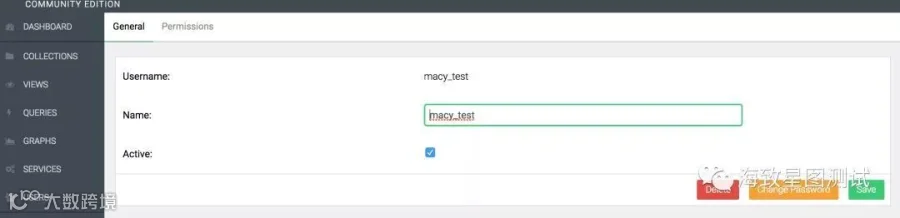
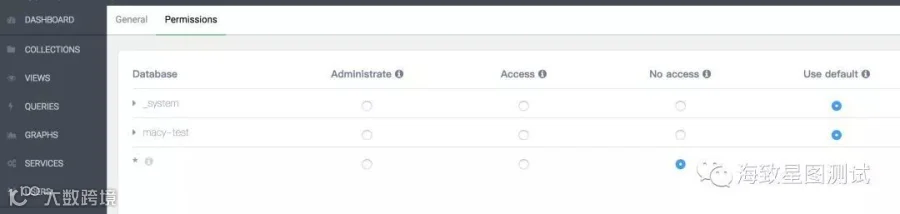
USER栏:可新增用户,删除用户,修改用户密码,为用户分配权限(新建用户使用默认权限,不能访问任意库,需root用户手动设置权限级别)
DATABASES栏:可新建数据库,删除数据库,为数据库分配所属用户,设置数据库排列方式。
COLLECTIONS栏:可新建集合,删除集合,清空集合,更改集合属性;创建新文档,删除文档,修改单个文档数据,创建索引;且支持单个集合数据的导入导出(小数据量),筛选功能等等。(集合类似于RDBMS中的表)
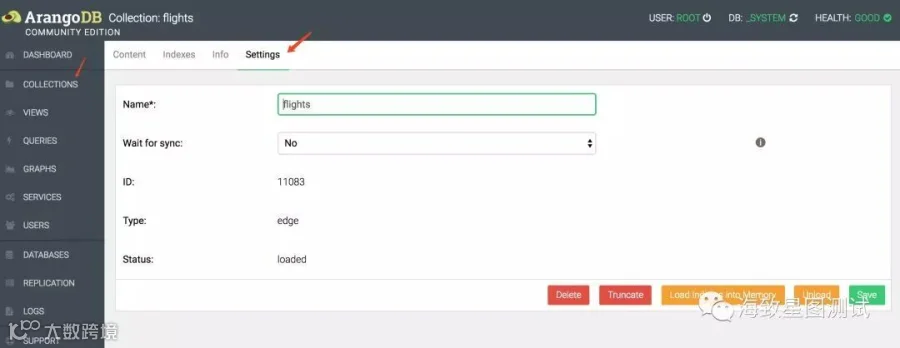
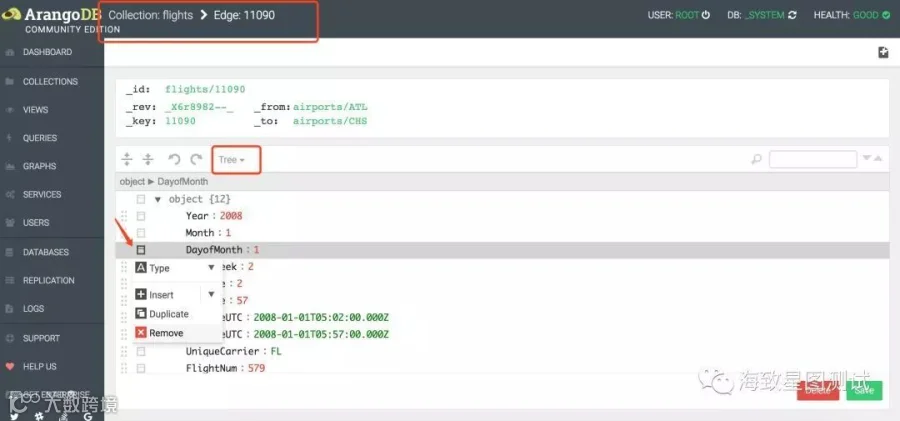
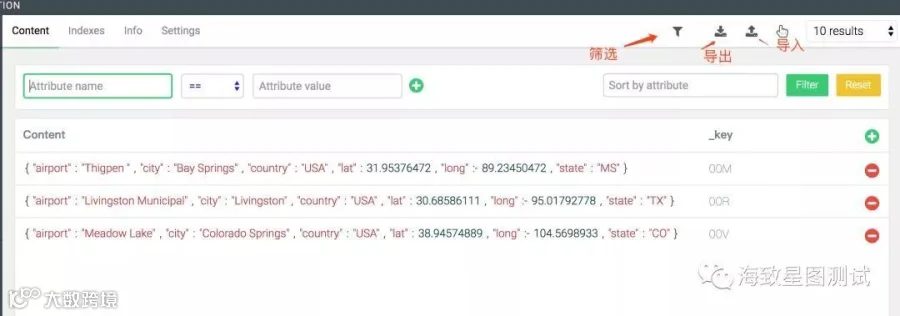
Collection:分为document collection、edge collection两种类型。ArangoDB的document数据(类似于RDBMS中的行数据)在展现层使用JSON格式,document collection由一个主键(_key)、_id、_rev、0个或者多个属性组成。edge collection则要比document collection多两个特殊的属性(_from、_to)。其中document collection在Graph中又被称为vertex collection,edge collection只在Graph中使用。

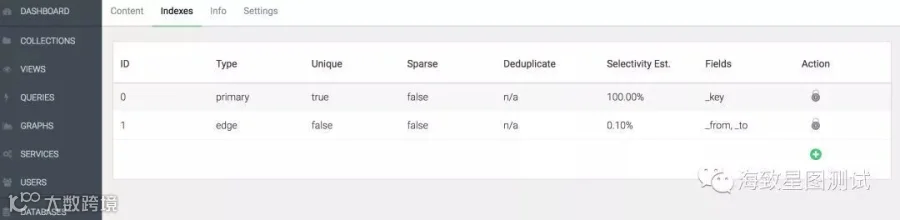
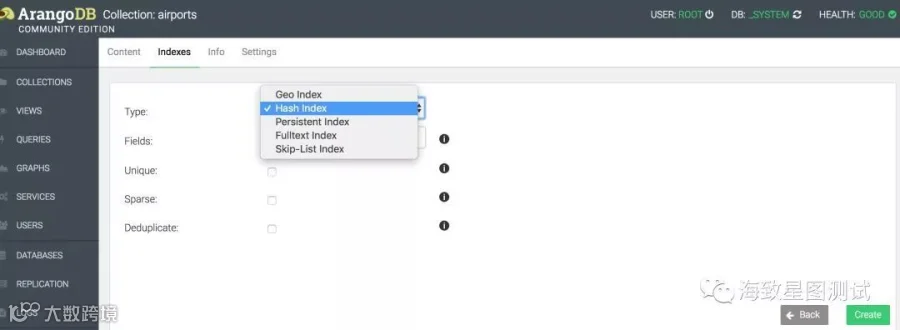
同时ArangoDB会自动对文档中的_key(primary index)、_from、_to(edge index)字段建立索引。primary index及edge index都基于Hash Index实现。
Hash Index:哈希索引可用于快速查找具有特定属性值的文档。哈希索引是未排序的,因此它支持等式查找,但不支持范围查询或排序。
Skip-List Index:是一个排序索引结构。它可用于快速查找具有特定属性值的文档,范围查询以及按排序顺序从索引返回文档
Persistent Index:是具有持久性的排序索引。可用于点查找,范围查询和排序操作,但前提是查询语句中提供完整索引属性名或左前缀。
Geo Index:地理索引存储二维坐标。涉及到经度,纬度时创建,且纬度和经度必须是数值。
Fulltext Index:全文索引支持完整匹配查询(完整单词)和前缀查询,以及基本逻辑操作。
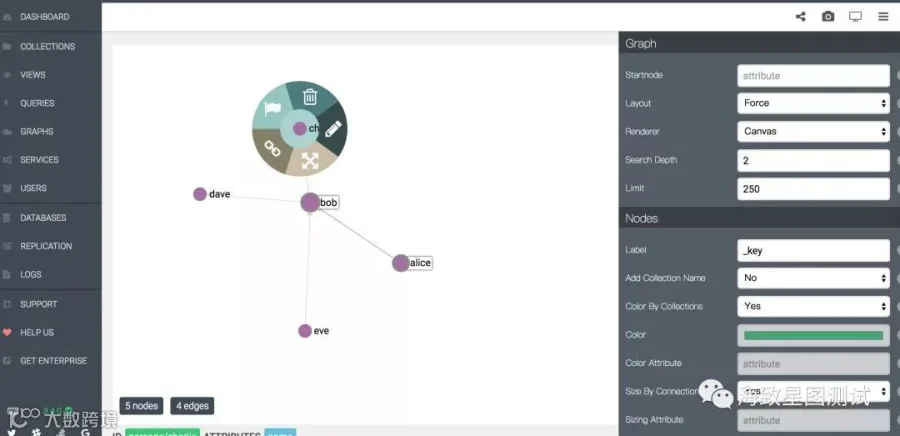
GRAPHS栏:可创建图,删除图,做图相关基本操作。
graph由边和顶点组成,且两顶点可以包含多个边,边只能为边集合(edge collection)。顶点可以是文档集合(document collection)或边集合的文档(实际创建图时,只会优先推荐文档集合)。
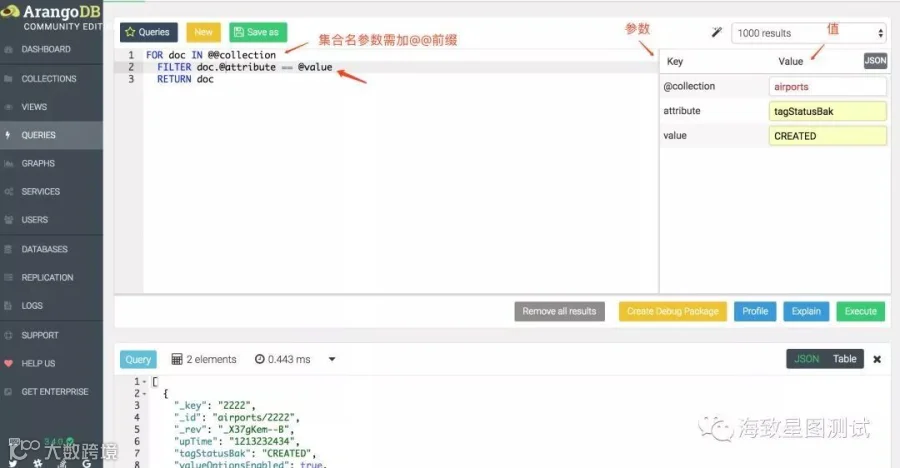
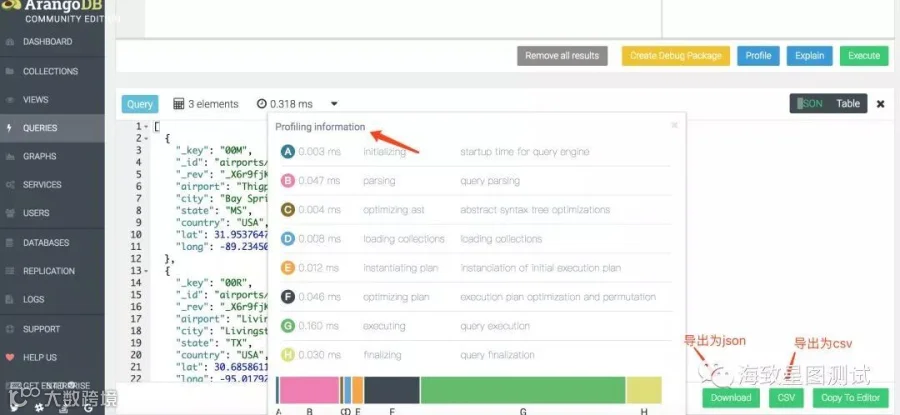
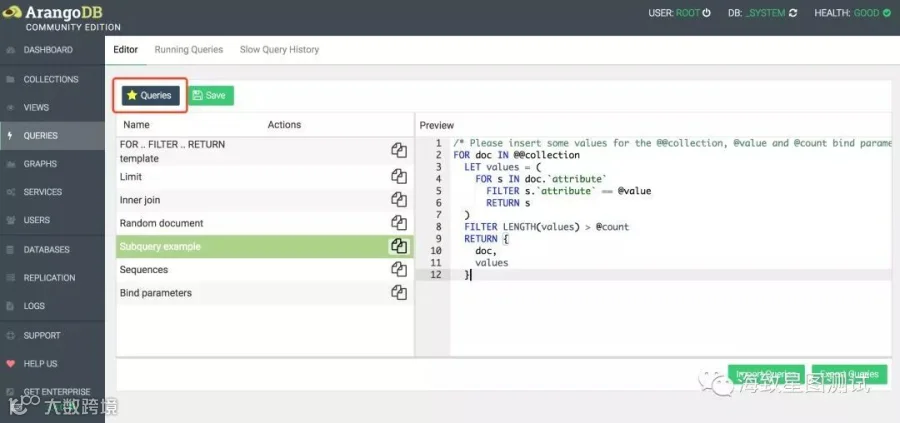
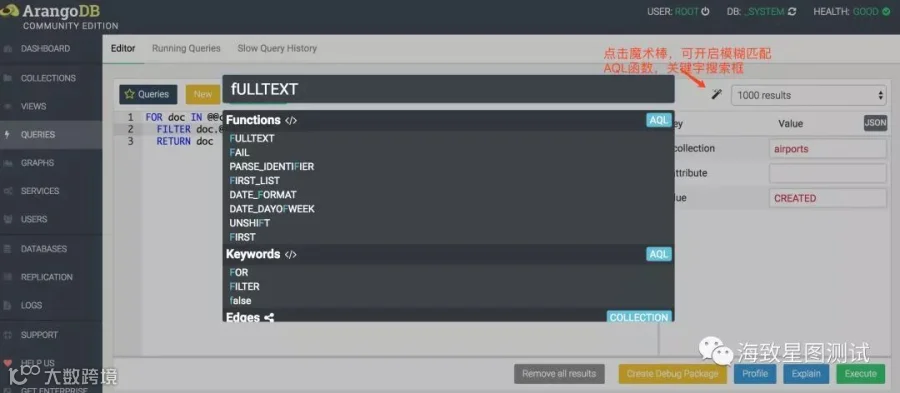
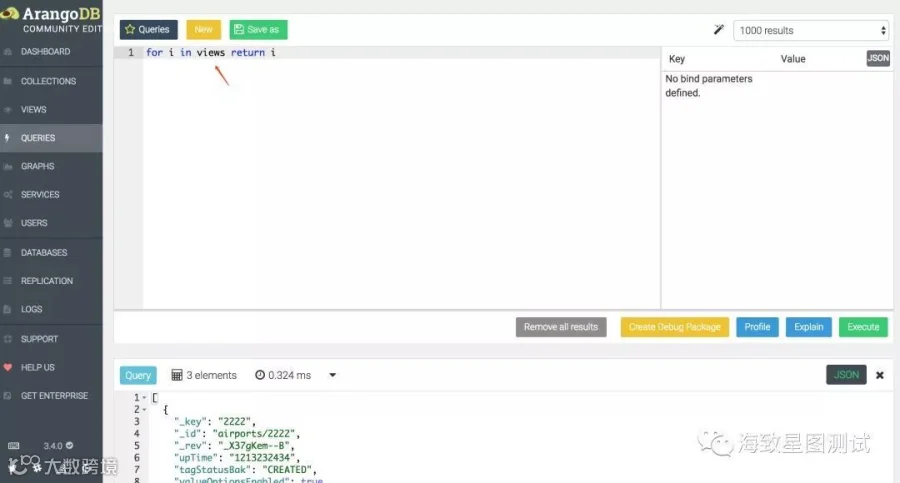
QUERYS栏:可执行AQL查询,并通过查看AQL分析信息,来优化AQL语句,也支持将查询结果导出为json或csv文档。且提供了部分query范例及全量模糊匹配AQL关键字,AQL函数和集合等插件。
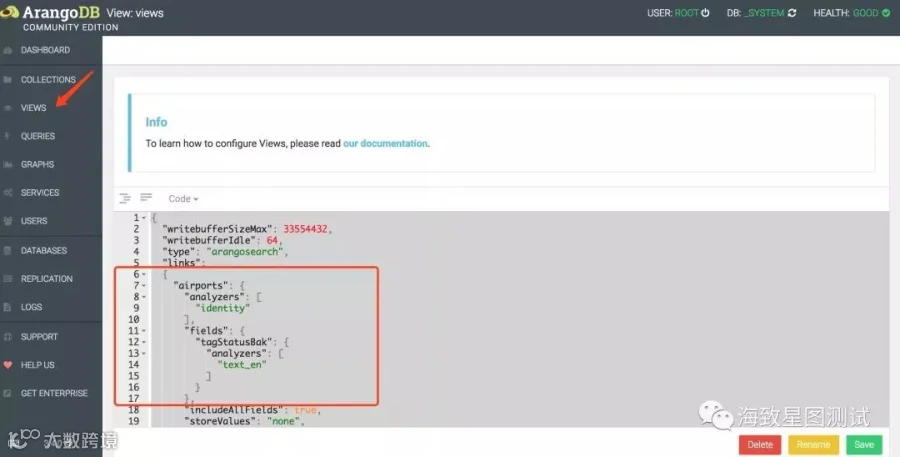
VIEWS栏:可创建视图,删除视图,编辑视图等。
修改links参数,用以链接至相关集合,并添加索引;一个视图可包含零个或多个链接,来指向不同集合。平时我们需经常进行多表操作时,即可创建视图,后续直接对视图做操作,而无需重复单表操作。
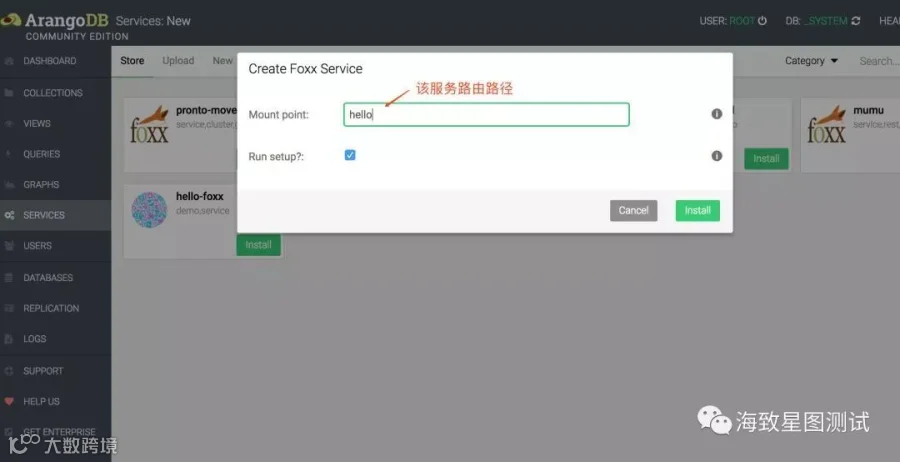
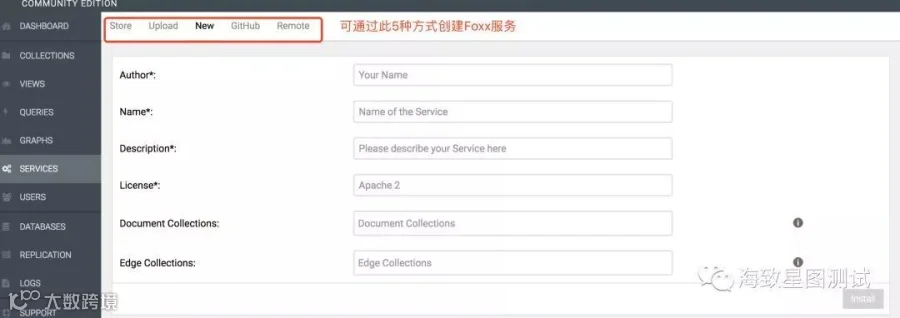
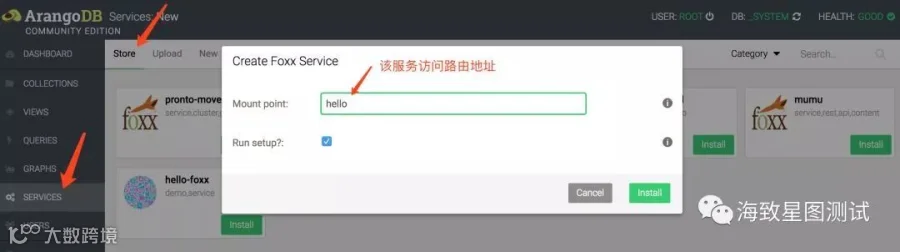
SERVICES栏:可根据个人需求,定制化的创建Foxx服务或查看所选服务详细视图。
ArangoDB 命令集操作
arangosh:ArangoDB命令行客户端,在此我们可以JavaScript脚本来管理ArangoDB服务器。
输入arangosh,即可进入shell环境。
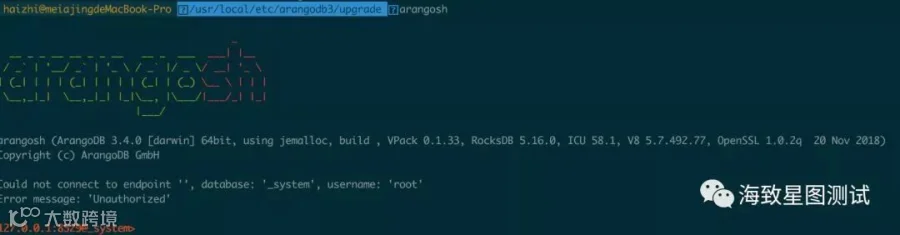
解决以上无权限问题:修改arangosh.conf,将用户名及密码,注释去除并修改为实际密码即可或关闭鉴权,将authentication置为false,这里更推荐前者。
修改root用户密码:
require("@arangodb/users").replace("root", "new-password")
新建用户及密码:
require("@arangodb/users").save("macy", "password")
赋予用户数据库权限(用户,数据库两者顺序可换):
require("@arangodb/users").grantDatabase("macy", "macyDB")
创建数据库:db._createDatabase("macyDB")
罗列数据库:db._databases()
删除数据库:db._dropDatabase("macyDB")
切换数据库:db._useDatabase("macyDB")
创建集合:db._create("macyCollections")
删除集合:db._drop("macyCollections")
罗列集合:db._collections()
创建点集合:
db._createDocumentCollection("macyDocumentCollection")
创建边集合:
db._createEdgeCollection("macyEdgeCollection")
插入数据db.macyCollection.save({"title":"test"})
根据_id或_key查询数据:
db.macyCollection.document("macyCollection_id/_key")
更新数据:db.macyCollection.update()
替换数据:
删除数据:
使用AQL:db._query("FOR doc IN macyCollection RETURN doc").toArray()
输入exit,即可退出arangosh窗口
ArangoDB工具集:
服务器参数:
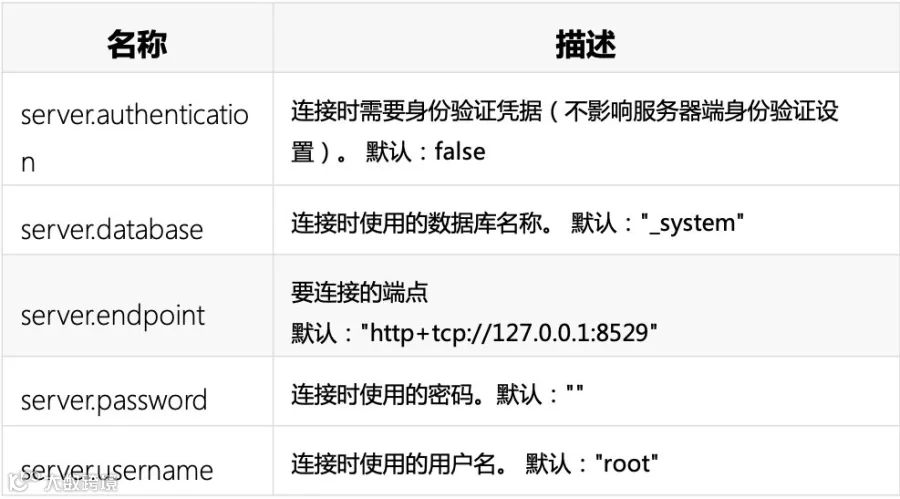
arangodump:用于备份ArangoDB中的数据和结构
全局参数:
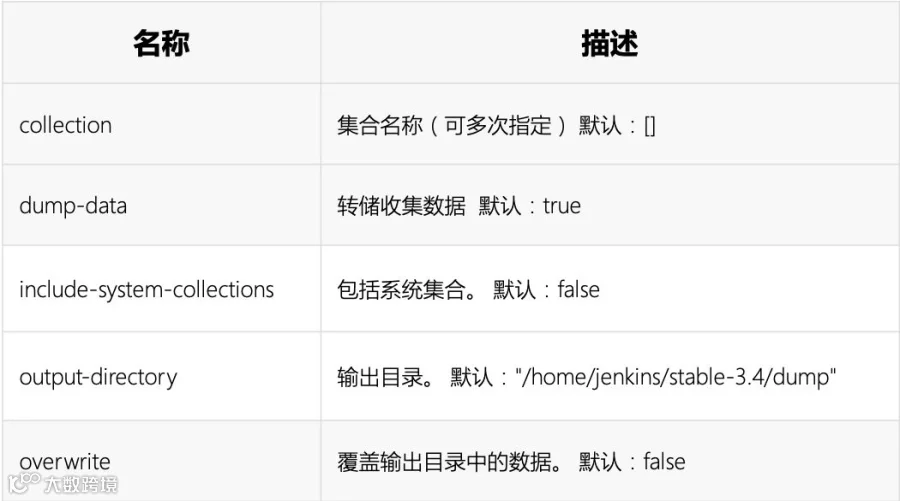
例:备份airports,mycollection两集合中数据及数据结构到dump文件夹
arangodump --output-directory "dump" --overwrite true --collection airports --collection mycollection --server.username root --server.password 123 --server.database _system
arangorestore:与arangodump配套使用,将备份还原至ArangoDB服务器
全局参数:
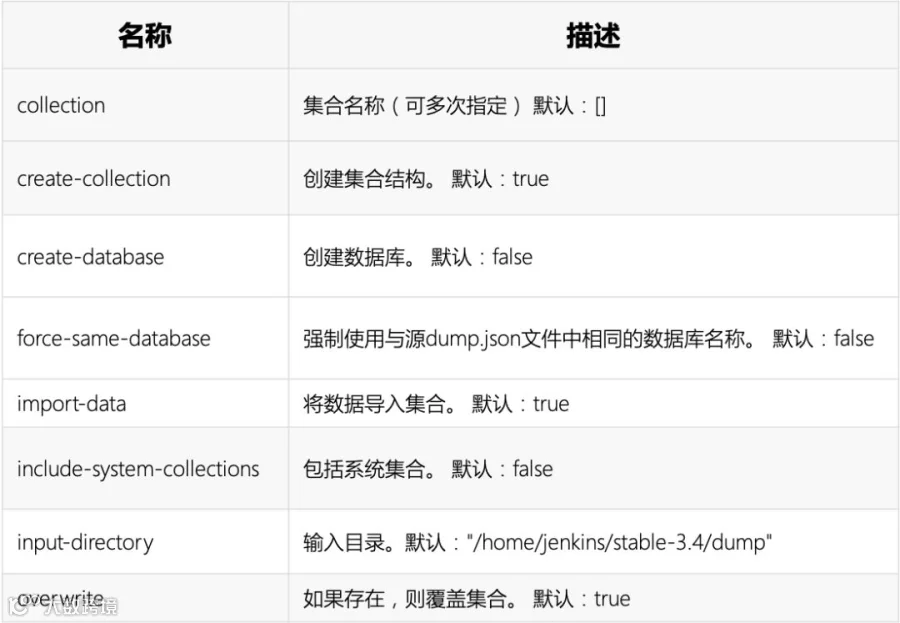
例:将该集合dump文件夹下airports数据恢复至对应数据库
arangorestore --input-directory "dump" --overwrite true --collection airports --server.username root --server.password 123 --server.database _system
arangoimport:将JSON,CSV和TSV等格式数据导入ArangoDB服务器
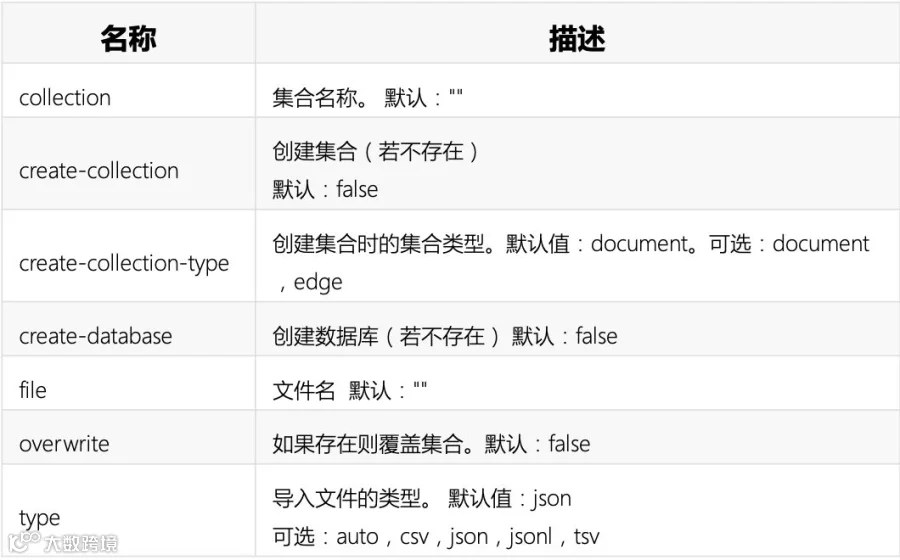
例:将flights.csv边数据导入至对应数据库,且创建集合
arangoimp --file "./flights.csv" --collection flights --create-collection true --type csv --create-collection-type edge
arangoexport:将数据导出为JSON,CSV或XML等格式
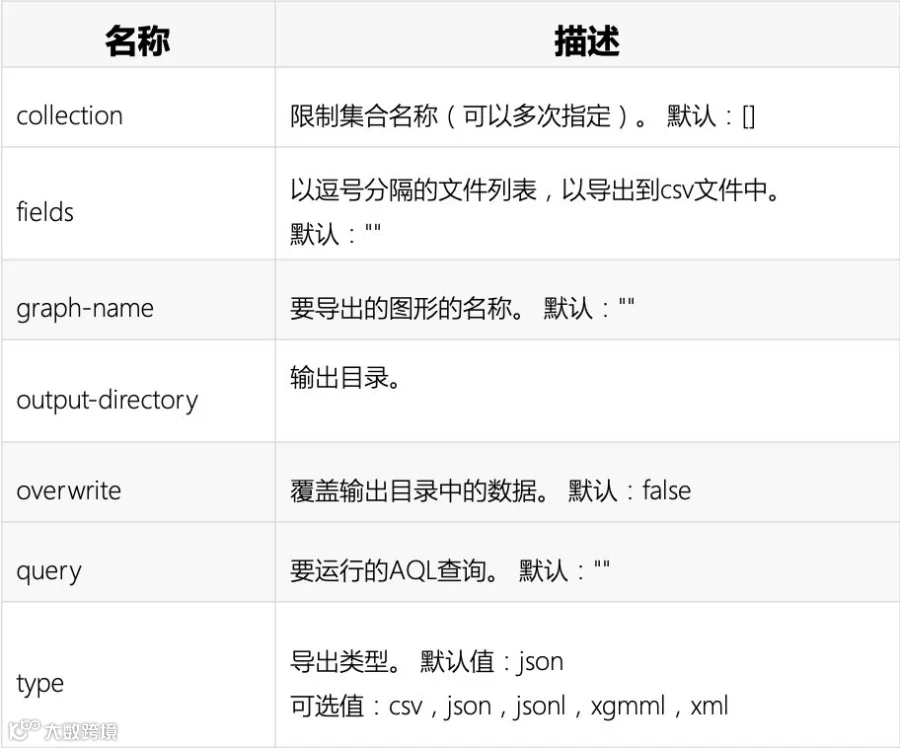
例:将airports集合数据导出至dump文件夹下,可指定按集合方式或aql查询方式导出
arangoexport --output-directory "dump" --overwrite true --type json --query "for i in airports return i"
arangoexport --collection airports --output-directory "dump" --overwrite true --type json
ArangoDB Rest API 操作
import sys,os
import requests
import json,re
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
workDir= os.path.abspath(os.path.join(os.getcwd(),"../../.."))
sys.path.append(workDir)
from src.utils.file.file_process import FileProcess
from src.utils.conf.conf import get_arango_info
from src.utils.log.logger import Logger
from src.utils.except_.except_ import Except_
class ArangoDB(object):
def __init__(self,):
arango_info=get_arango_info()
self.base="{0}://{1}:{2}/_db/{3}".format(arango_info["protocol"],
\arango_info["host"],arango_info["port"],arango_info["db"])
self.usr=arango_info["usr"]
self.pwd=arango_info["pwd"]
self.headers=self.get_headers()
def get_authorization(self):
with Except_(type_="debug"):
auth_url=self.base+"/_open/auth"
params_body={"username":self.usr,"password":self.pwd}
authorization=json.loads(requests.post(auth_url,data=json.dumps(params_body)).text)["jwt"]
return authorization
def get_headers(self):
"""构造headers"""
headers={
"accept":"application/json",
"Content-Type":"application/json",
"Authorization":"bearer "+self.get_authorization()
}
return headers
def requests_(self,method,url,params=None,params_body=None):
with requests.Session() as s:
if params_body==None:
response = s.request(method,url,headers=self.headers,params=params)
else:
response= s.request(method,url,headers=self.headers,params=params
,\data=json.dumps(params_body))
return json.loads(response.text)
def create_database(self,database_name):
"""
创建数据库
:param database_name:需创建的数据库名
:return result:操作结果
"""
with Except_(type_="debug"):
url=self.base+"/_api/database"
params_body={
"name": database_name
}
result=self.requests_("POST",url,params_body=params_body)
return result
def delete_database(self,database_name):
"""
删除数据库
:param database_name:需删除的数据库名
:return result:操作结果
"""
with Except_(type_="debug"):
url=self.base+"/_api/database/"+database_name
result=self.requests_("DELETE",url)
return result
def create_collection(self,collection_name,type_=2):
"""
创建集合
:param collection_name:需创建的集合名
:param type_:集合类型,2: document collection;3: edges collection
:return result:操作结果
"""
with Except_(type_="debug"):
url=self.base+"/_api/collection"
params_body={
"name": collection_name,
"type": type_
}
result=self.requests_("POST",url,params_body=params_body)
return result
def delete_collection(self,collection_name):
"""
删除集合
:param collection_name:需创建的集合名
:return result:操作结果
"""
with Except_(type_="debug"):
url=self.base+"/_api/collection/"+collection_name
result=self.requests_("DELETE",url)
return result
def truncate_collection(self,collection_name):
"""
清空集合
:param collection_name:需清空的集合名
:return result:操作结果
"""
with Except_(type_="debug"):
url=self.base+"/_api/collection/"+collection_name+"/truncate"
result=self.requests_("PUT",url)
return result
def count_collection(self,collection_name):
"""
统计集合中文档数
:param collection_name:需统计的集合名
:return result:统计数
"""
with Except_(type_="debug"):
url=self.base+"/_api/collection/"+collection_name+"/count"
result=self.requests_("GET",url)
count=result["count"]
return count
def query_all(self,collection_name,fields=None,type_=None,OUTPUT=None,limit=0):
"""
根据集合名查询/导出数据
:param collection_name:需操作的集合名
:param fields:需筛选的字段集合,以逗号分隔
:param type_:为筛选过滤方式,可选:include/exclude
:return result:操作结果
"""
with Except_(type_="debug"):
url=self.base+"/_api/export"
params={"collection":collection_name}
params_body={"count": False,"flush": True,"flushWait": 10,"limit": limit,"ttl": 0}
if fields and type_:
restrict = {"restrict": {
"fields": [fields],
"type": type_
}}
params_body.update(restrict)
result=self.requests_("POST",url,params=params,params_body=params_body)
if OUTPUT:
FileProcess(OUTPUT).dump_json(result["result"],"w")
return result["result"]
def import_json(self,collection_name,INPUT=None,params_body=None,overwrite=False):
"""
增量或全量导入数据及更新数据
:param collection_name:需操作数据的集合名
:param INPUT:当以文件导入时,文件名
:param params_body:直接写入时的数据json体
:param overwrite:为True时,覆盖式导入
:return result:操作结果
"""
with Except_(type_="debug"):
url=self.base+"/_api/import#json"
if INPUT:
params_body=FileProcess(INPUT).load_json()
params={
"type":"auto",
"collection":collection_name,
"overwrite":overwrite,
"onDuplicate":"update"
}
result=self.requests_("POST",url,params=params,params_body=params_body)
return result
def get_document_byid(self,_id):
"""
根据id查询数据
:param _id:所要查询的id
:return result:查询操作结果
"""
with Except_(type_="debug"):
url=self.base+"/_api/document/"+_id
result=self.requests_("GET",url)
return result
def delete_document_byid(self,_id):
"""
根据id删除数据
:param _id:所要删除数据的id
:return result:删除操作结果
"""
with Except_(type_="debug"):
url=self.base+"/_api/document/"+_id
result=self.requests_("DELETE",url)
return result
def load_all(self):
"""
加载所有集合,将集合都置为load状态
:return Flag:操作结果
"""
get_all_collection_url=self.base+"/_api/collection?excludeSystem=true"
all_collection=self.requests_("GET",get_all_collection_url)["result"]
Flag=True
for collection in all_collection:
load_url=self.base+"/_api/collection/"+collection["name"]+"/load"
result=self.requests_("PUT",load_url)
if result["code"] != 200:
Flag=False
return Flag
def simple_query_getall(self,collection_name,skip=0,limit=None,ttl=0,stream=True):
"""Return all documents
FOR doc IN collection RETURN doc
根据集合名查询数据
:param collection_name:所要查询数据的集合名
:param skip:查询中要跳过的文档数
:param limit:要返回的最大文档数量
:param ttl:光标的生存时间(以秒为单位)
:param stream:将此游标创建为流查询
:return result:查询操作结果
"""
with Except_(type_="debug"):
url=self.base+"/_api/simple/all"
params_body={
"collection":collection_name,
"skip":skip,
"limit":limit,
"ttl":ttl,
"stream":stream
}
result=self.requests_("PUT",url,params_body=params_body)
return result["result"]
def simple_query_get_byexample(self,collection_name,example,\
skip=0,limit=None,ttl=0,stream=True):
"""Simple query by-example
FOR doc IN collection FILTER doc.key == value RETURN doc
简单查询根据任意键值匹配,支持嵌套
:param collection_name:所要查询数据的集合名
:param skip:查询中要跳过的文档数
:param limit:要返回的最大文档数量
:param example:要匹配的条件({"_source.opt_user_id":"-1"}/{"_key":"3893615"})
:return result:查询操作结果
"""
with Except_(type_="debug"):
url=self.base+"/_api/simple/by-example"
params_body={
"collection":collection_name,
"skip":skip,
"limit":limit,
"example":example
#{key:value}
}
result=self.requests_("PUT",url,params_body=params_body)
return result["result"]
def simple_query_get_bykeys(self,collection_name,keys):
"""Find documents by their keys
FOR doc IN collection FILTER doc._key IN keys RETURN doc
通过_key(字符串格式)获取多个文档
:param collection_name:所要查询数据的集合名
:param keys:需匹配的_key的列表
:return result:查询操作结果
"""
with Except_(type_="debug"):
url=self.base+"/_api/simple/lookup-by-keys"
params_body={
"collection":collection_name,
"keys":keys
}
result=self.requests_("PUT",url,params_body=params_body)
return result["documents"]
def simple_query_remove_byexample(self,collection_name,key,value):
"""Remove documents by example
删除与示例匹配的集合的所有文档(不支持嵌套删除)
:param collection_name:所要删除数据的集合名
:param key:需匹配的key
:param key:需匹配的value值
:return result:删除操作结果
"""
with Except_(type_="debug"):
url=self.base+"/_api/simple/remove-by-example"
params_body={
"collection":collection_name,
"example":{key:value}
}
result=self.requests_("PUT",url,params_body=params_body)
return result
def simple_query_remove_byexample(self,collection_name,key,value):
"""replace documents by example
删除与示例匹配的集合的所有文档(不支持嵌套删除)
:param collection_name:所要删除数据的集合名
:param key:需匹配的key
:param key:需匹配的value值
:return result:删除操作结果
"""
with Except_(type_="debug"):
url=self.base+"/_api/simple/replace-by-example"
params_body={
"collection":collection_name,
"example":{key:value}
}
result=self.requests_("PUT",url,params_body=params_body)
return result
def query_by_aql(self,query):
"""执行aql查询数据
:param collection_name:所要删除数据的集合名
:param key:需匹配的key
:param key:需匹配的value值
:return result:删除操作结果
"""
with Except_(type_="debug"):
url=self.base+"/_api/cursor"
params_body={
"query" : query
}
result=self.requests_("POST",url,params_body=params_body)
return result["result"]
最后,以上为本人学习中所得,若有不对之处,欢迎指正,也期待大神指教。
Reference:
➀:https://www.cnblogs.com/bonelee/p/6244006.html
➁:https://blog.csdn.net/a499477783/article/details/79202272
AQL操作:https://yq.aliyun.com/ziliao/195684
ArangoDB官方文档:
https://docs.arangodb.com/3.4/Manual/