
henry 发自 凹非寺
量子位
DeepSeekV4技术报告详细阐述了mHC、CSA、HCA、Muon和FP4等创新技术,但未提及Engram。
这一缺失引发行业热议:Engram去哪了?
Engram由DeepSeek和北京大学今年1月联合开源,专注解决大模型记忆与效率问题。自arXiv发布以来,业内持续探讨其技术价值。
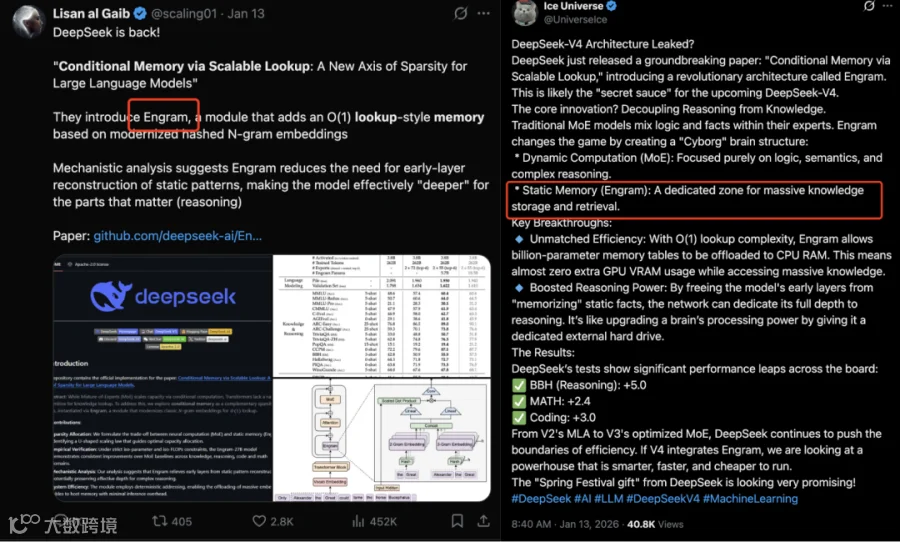
该技术的核心优势在于:面对"伦敦是英国首都"等事实性问题,模型无需调用整个深层网络重新计算,可直接查表获取结果。
此举显著降低显存占用,同时释放深层网络资源用于高阶推理。
由于Engram被视为V4的架构基础,V4发布后,研究者第一时间在论文中搜索其踪迹,却未果。部分观点认为,缺少Engram使V4存在明显缺憾。
然而,Engram的实践探索仍在延续:CXL内存池化版本解决多机存储瓶颈,无冲突热层实验验证了架构优化方向,视觉Tiny Engram则将其拓展至多模态领域。
尽管V4未集成此技术,其理念已为下一代模型奠定基础。
Engram技术解析
2026年1月12日,DeepSeek与北大团队发布33页论文《Conditional Memory via Scalable Lookup》,揭示Engram本质:为Transformer添加原生知识查表模块。

传统Transformer混淆了动态推理与静态知识检索两种任务。例如识别"Diana, Princess of Wales"时,模型需经6层计算逐步解析,效率低下。
Engram通过插入查表模块优化流程:在Transformer第2层和第15层部署哈希查询,对token序列实时匹配海量嵌入表。门控机制确保语义一致性,如精准识别"张仲景"为固定历史实体。
该技术与MoE形成互补:MoE稀疏化计算资源,Engram稀疏化存储访问。实验证明,分配20%-25%稀疏参数给Engram可达到最优模型效果。
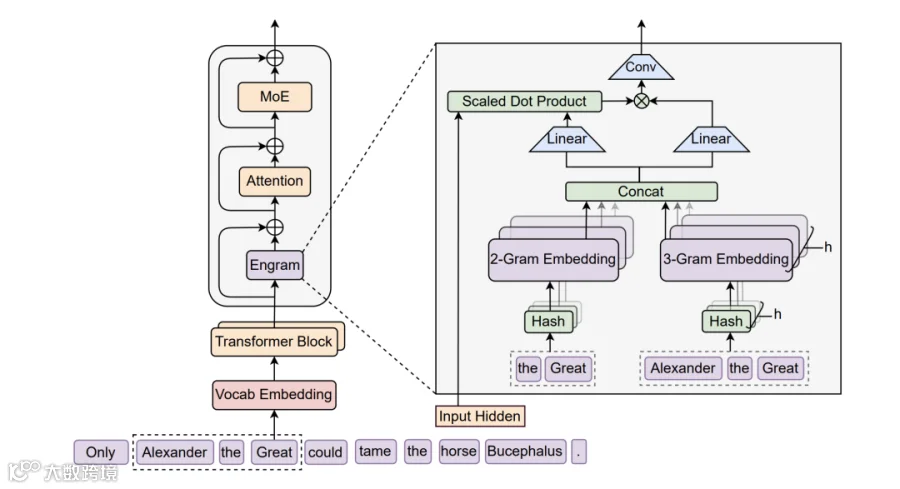
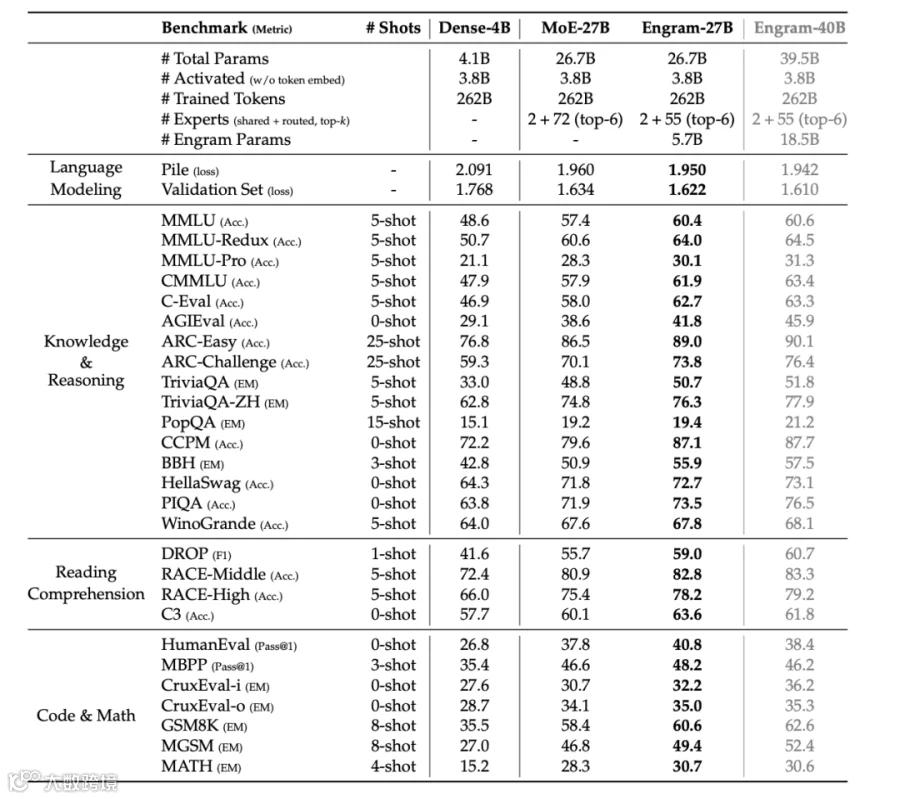
27B参数规模验证显示:在知识密集任务中表现优异(MMLU +3.4, CMMLU +4.0),通用推理与代码能力提升更显著(BBH +5.0, ARC-Challenge +3.7)。长上下文场景提升尤为突出,Multi-Query NIAH准确率从84.2%跃升至97.0%。
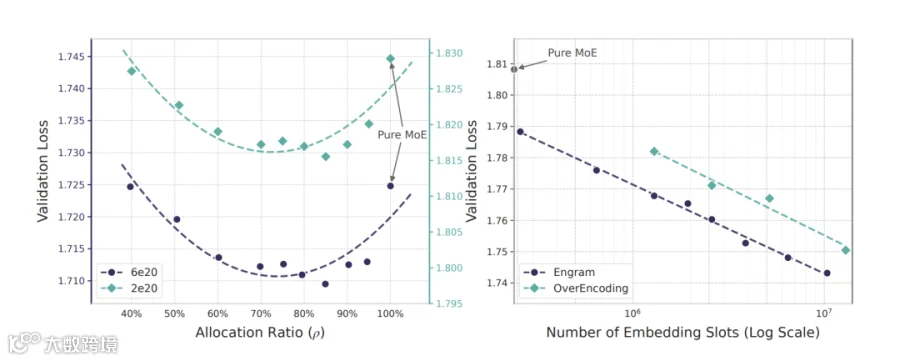
Engram不仅新增记忆功能,更通过释放早期层算力变相加深网络深度。LogitLens分析表明,Engram-27B第5层表征即媲美MoE基线第12层效果。
工程实现上,论文将千亿级嵌入表卸载至host DRAM,在H800推理中仅造成2.8%吞吐损失。依赖确定性索引实现CPU预取与GPU计算重叠,显著降低对HBM的依赖。
Engram的后续进展
研发团队未在V4中集成该技术,但学界持续推动实践落地。
CXL内存池化应用
3月10日,北大、阿里云等团队发布论文,验证CXL内存池对Engram的适配性。采用GPU HBM存储计算权重、本地DRAM作二级缓存、CXL池作三级存储,通过XConn交换芯片构建4TB共享内存池。集成至SGLang框架后,端到端吞吐损失低于5%,证实其为Engram的理想存储方案。

无冲突热层实验验证
1月23日,研究者TaoLin通过《A Collision-Free Hot-Tier Extension for Engram-Style Conditional Memory》实证检验多头哈希优化。设计Engram-Nine将记忆分层处理后,实验显示:消除高频N-gram冲突的"优化"方案并未稳定提升验证效果,反而在训练后期导致冷路径表现反超。

视觉模态拓展
开源团队AutoArk复现文本Engram后,将其迁移到Stable Diffusion视觉框架。针对视觉patch实施分层编码与哈希查表,在同等效果下所需参数仅为LoRA的15%-30%,且能避免概念注入退化问题,验证了多模态应用可行性。

当前,Engram的技术路径正通过内存架构优化、实验验证与跨模态拓展稳步发展。
未来展望
Engram论文摘要指出:"条件记忆将成为下一代稀疏模型不可或缺的建模原语。"
条件记忆将是下一代稀疏模型不可或缺的建模原语。

业界推测该技术或将在V5甚至V4.1版本正式集成。