

在数字图像创作与编辑领域,我们长期面临着一个痛点:不同的编辑任务需要不同的工具。想要移除背景用A模型,更换风格用B模型,修复瑕疵用C模型……这种"碎片化"的工作流不仅效率低下,还难以保证输出质量的一致性。
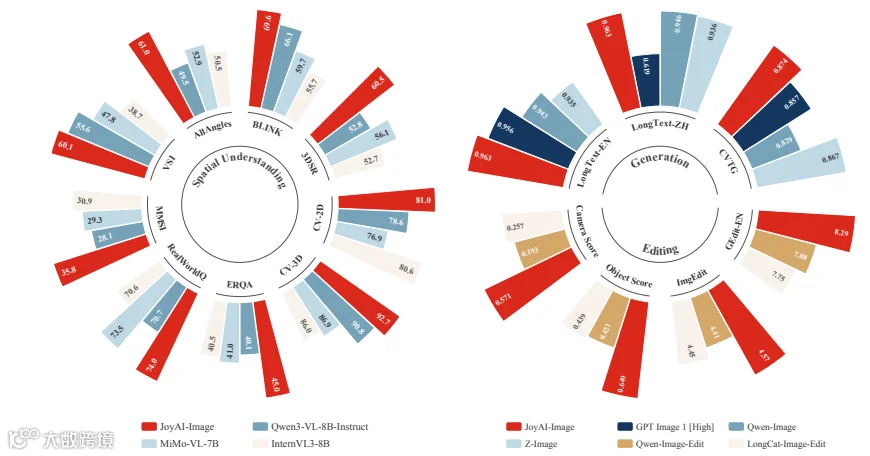
京东探索研究院推出的JoyAI-Image,是业内首个以空间智能为核心的统一多模态基础模型,一体化支持图像理解、文生图、指令编辑三大能力。模型基于8B MLLM+16B MMDiT架构,通过理解 - 生成 - 编辑闭环协同,在空间推理、长文本渲染、多视角生成、可控空间编辑上达到 SOTA,多项指标追平 Gemini 2.5 Pro,现已全面开源。

效果展示



核心亮点速览:
-
空间智能觉醒:支持物体移动、旋转、相机视角控制三类精细空间操作,保持几何一致性和遮挡关系 -
统一架构:理解、生成、编辑形成闭环,空间意图从指令解析贯穿到图像生成 -
顶尖性能:在公开Benchmark中,空间理解和编辑能力超过现有开源模型,比肩顶尖闭源模型 -
全面开源:模型权重、推理代码、SpatialEdit数据集均已发布,支持ComfyUI和Diffusers
相关链接
-
论文:https://joyai-image.s3.cn-north-1.jdcloud-oss.com/JoyAI-Image.pdf -
主页:https://github.com/jd-opensource/JoyAI-Image -
模型:https://huggingface.co/jdopensource/JoyAI-Image-Edit
论文介绍

方法概述
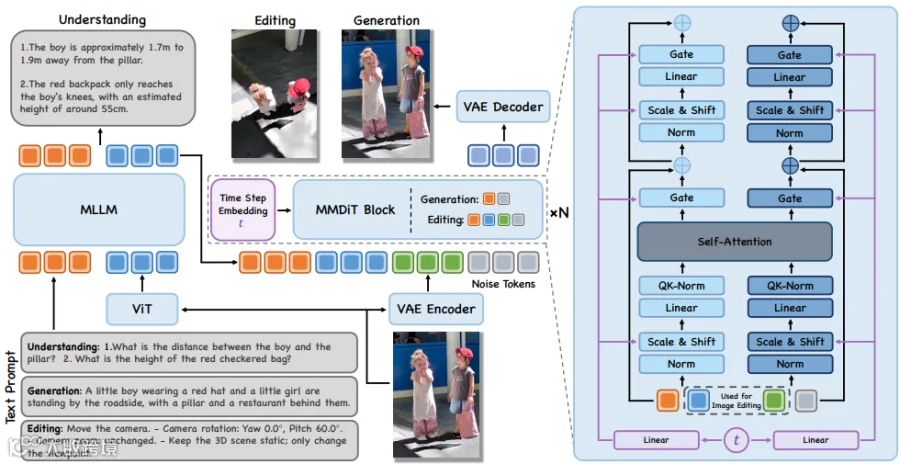
统一架构设计
-
MLLM(8B):负责图像与文本的语义理解,输出场景解析结果(如物体关系、空间布局); -
MMDiT(16B):基于理解结果生成或编辑图像,支持长文本排版、多视图生成、可控编辑; -
闭环协作:生成结果反馈至MLLM进行空间推理验证,形成“理解→生成→验证→优化”的双向增强。
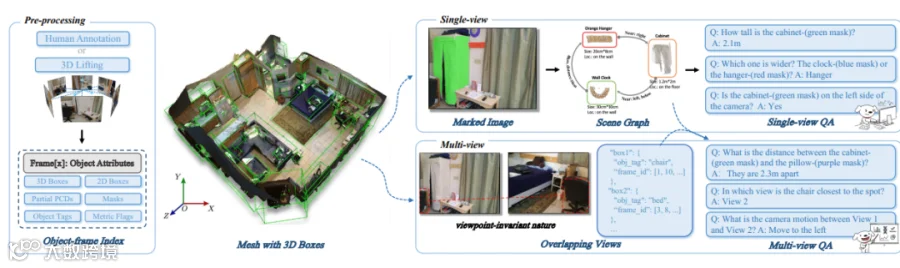
关键技术创新
-
空间理解数据(OpenSpatial):标注物体几何关系、视角信息,强化模型的空间感知能力; -
长文本渲染优化:通过多阶段训练(如先生成文本掩码再填充细节),解决密集文本布局的失真问题; -
指令分解编辑:将复杂编辑指令拆解为对象移动、旋转、相机控制等子任务,提升编辑精准度。
训练策略
-
预训练:在大规模图文数据上学习基础多模态表示; -
空间理解微调:在OpenSpatial数据上强化场景解析能力; -
编辑能力微调:在SpatialEdit数据上学习指令-编辑的映射关系。

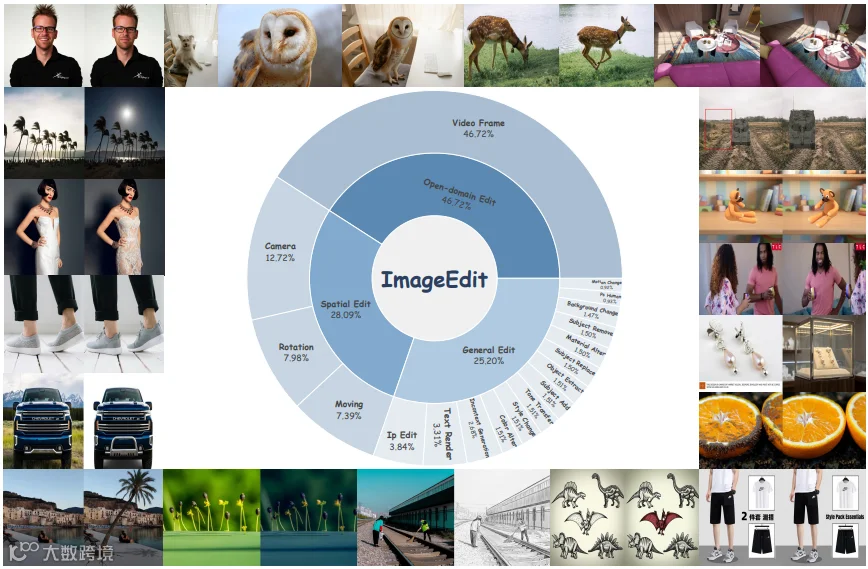
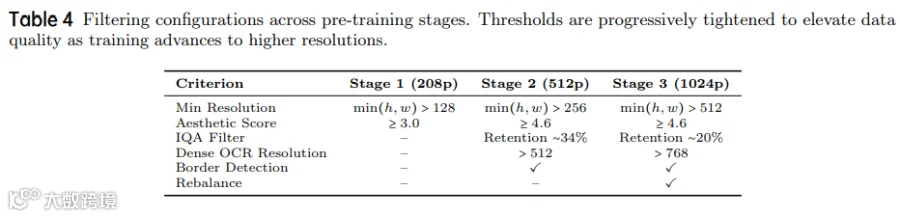
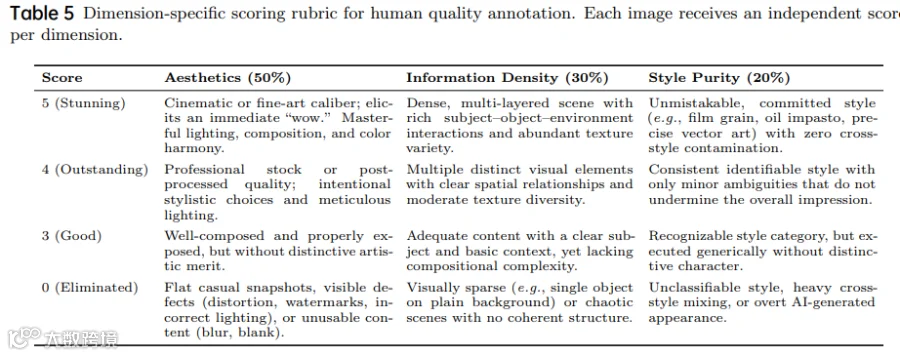
训练数据分布
实验
定性效果

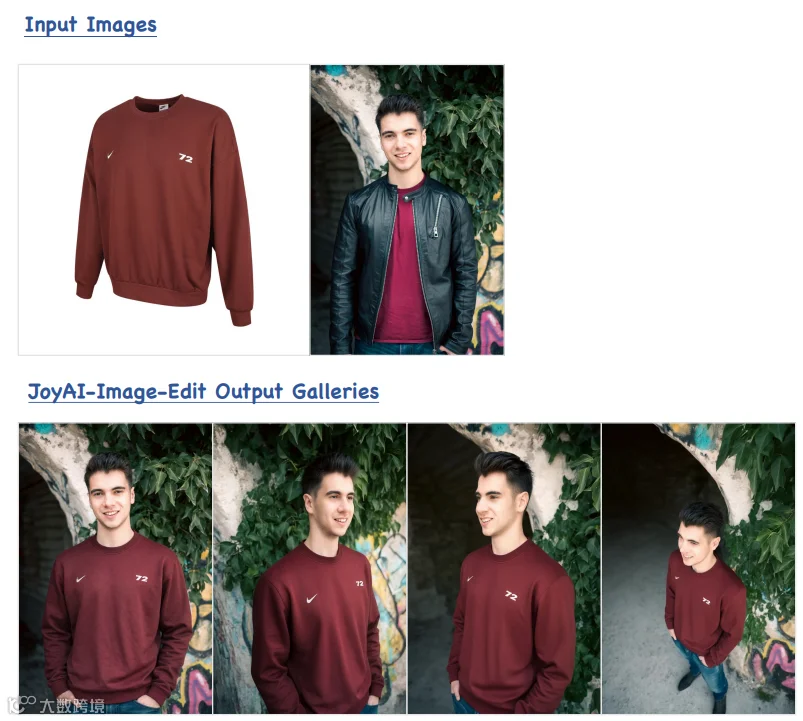
-
空间编辑:精准执行“将沙发从客厅左侧移动到右侧”等复杂指令,保持场景结构完整; -
长文本排版:生成多栏漫画、密集技术文档等场景,文本清晰可读; -
多视图生成:支持同一物体的360°旋转渲染,视角过渡自然。
定量对比
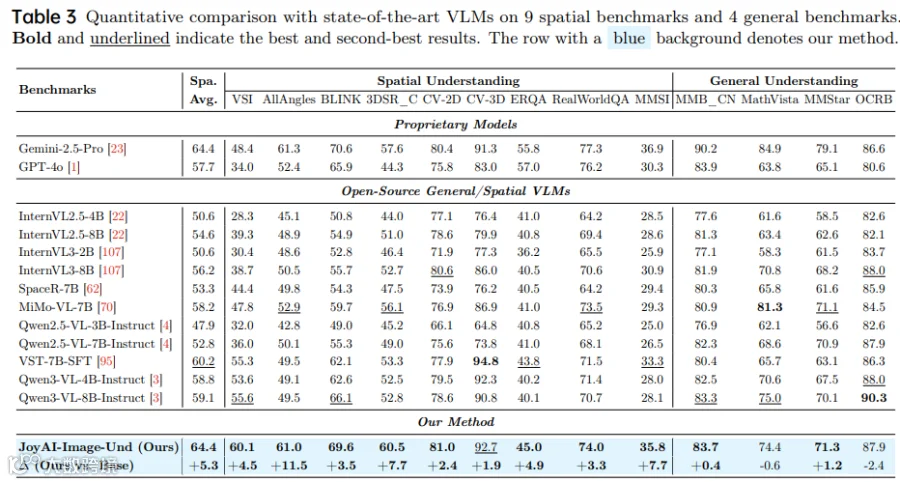

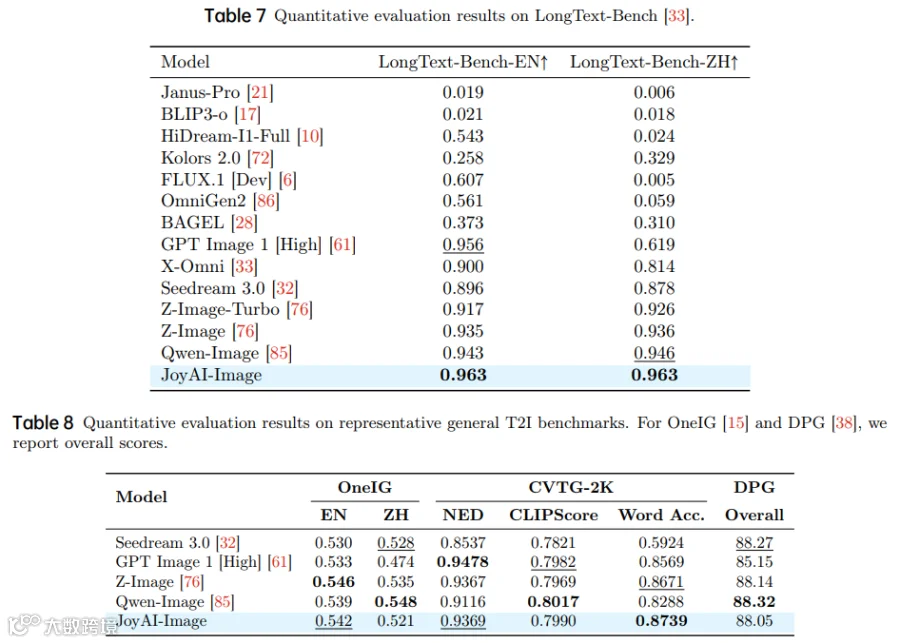
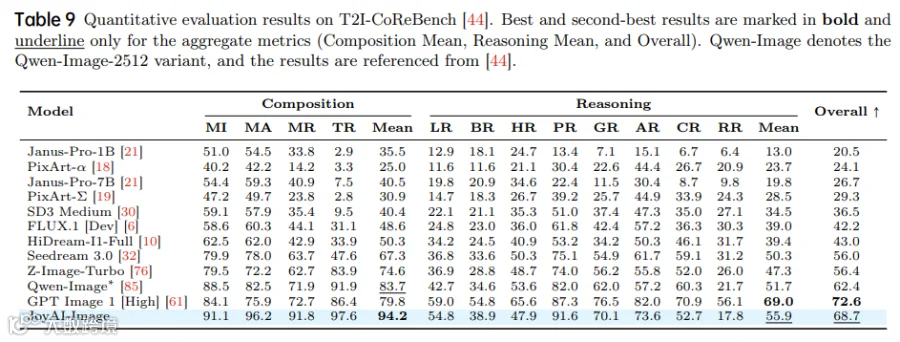
-
空间推理任务:在RefCoco/RefCoco+数据集上,JoyAI-Image的定位准确率超越Qwen-Image-Edit与Nano Banana Pro; -
长文本生成:在DenseText数据集上,FID分数降低32%,布局一致性显著提升; -
多视图生成:在MultiView数据集上,视角变换误差率下降41%。
结论
-
技术上:给出统一多模态模型可复现训练方案,OpenSpatial 数据与多阶段优化可直接复用; -
能力上:空间理解、长文本、多视角、可控编辑全面 SOTA; -
应用上:支撑视觉 - 语言 - 动作系统、3D 重建、具身智能、世界模型等下一代 AI 场景。
该模型已开源,支持 ComfyUI、Diffusers,可快速落地电商创意、设计、智能图像处理、机器人感知等场景。
感谢你看到这里,添加小助手 AIGC_Tech 加入官方 AIGC读者交流群,下方扫码加入 AIGC Studio 星球,获取前沿AI应用、AIGC实践教程、大厂面试经验、AI学习路线以及IT类入门到精通学习资料等,欢迎一起交流学习💗~
