

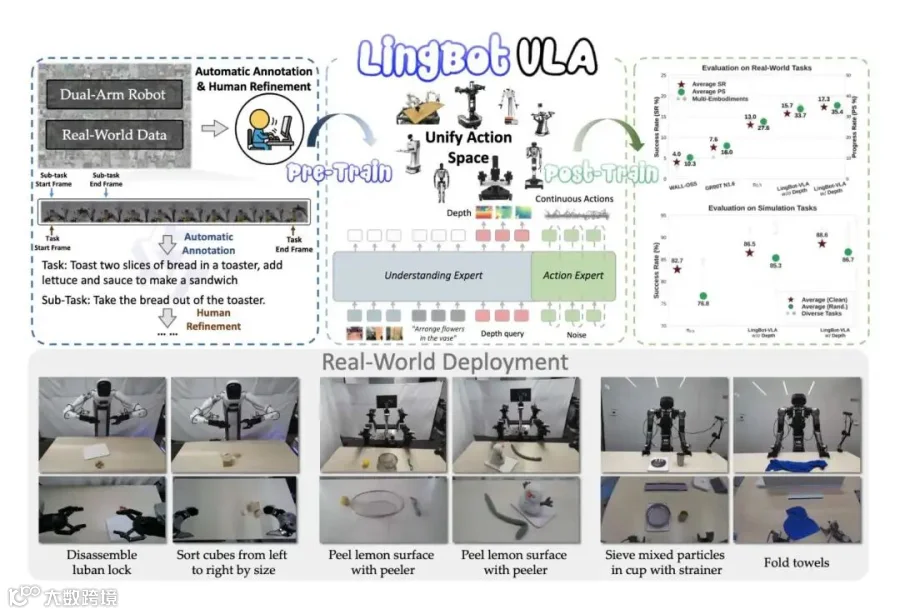
在具身智能领域,如何让机器人真正走进复杂现实世界并跨平台执行精细操作,一直是学术界与工业界的痛点。蚂蚁灵波科技发布的 LingBot-VLA 基础模型,整合 9 类机器人 2 万小时真实操作数据,采用 MoT 架构,具备超强跨平台泛化力与空间感知力,训练效率较主流框架提升 1.5 - 2.8 倍,在真实世界与仿真测试中表现卓越,为具身智能落地提供了高性价比底座。
相关链接
-
论文:https://arxiv.org/pdf/2601.18692 -
网页: https://technology.robbyant.com/lingbot-vla -
源码:https://github.com/robbyant/lingbot-vla -
权重: https://huggingface.co/collections/robbyant/lingbot-vla
论文介绍
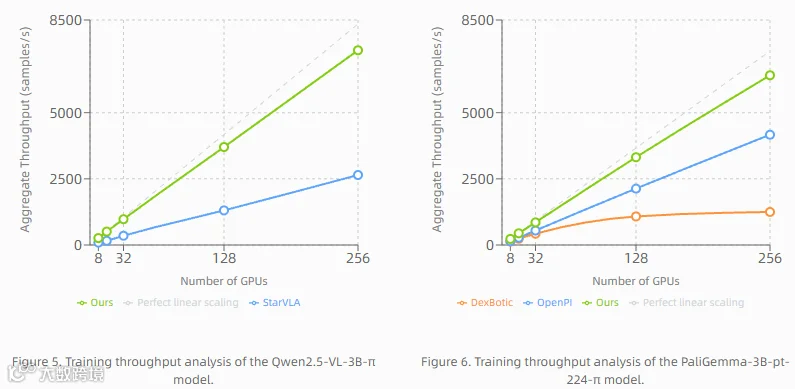
 LingBot-VLA是一个基于约 20,000 小时真实世界操作数据的具身人工智能基础模型,涵盖 9 种主流双臂机器人配置。我们在 3 个机器人平台上进行了系统评估,每个配置包含 100 个任务,每个任务使用 130 个训练回合进行后训练自适应。实验结果表明,LingBot-VLA 的性能显著优于现有解决方案,验证了其卓越的性能和强大的泛化能力。此外,论文开发了一个高效的后训练工具链,在 8 GPU 配置下实现了每秒 261 个样本的吞吐量,相比现有的 VLA 代码库(取决于底层 VLM),速度提升了 1.5 到 2.8 倍。这些特性确保该模型非常适合物理机器人部署。为了推动机器人学习领域的发展,我们发布了完整的代码、基础模型和基准测试数据,旨在支持对更具挑战性任务的研究,并促进评估协议的标准化。
LingBot-VLA是一个基于约 20,000 小时真实世界操作数据的具身人工智能基础模型,涵盖 9 种主流双臂机器人配置。我们在 3 个机器人平台上进行了系统评估,每个配置包含 100 个任务,每个任务使用 130 个训练回合进行后训练自适应。实验结果表明,LingBot-VLA 的性能显著优于现有解决方案,验证了其卓越的性能和强大的泛化能力。此外,论文开发了一个高效的后训练工具链,在 8 GPU 配置下实现了每秒 261 个样本的吞吐量,相比现有的 VLA 代码库(取决于底层 VLM),速度提升了 1.5 到 2.8 倍。这些特性确保该模型非常适合物理机器人部署。为了推动机器人学习领域的发展,我们发布了完整的代码、基础模型和基准测试数据,旨在支持对更具挑战性任务的研究,并促进评估协议的标准化。
模型概要
LingBot-VLA 具身智能基座模型,其训练数据涵盖 9 种主流双臂机器人配置、总计约 20,000 小时的真实世界操作数据。我们在 3 种机器人构型上进行了系统性评估,每种构型设置 100 项任务,每项任务使用 130 条后训练数据进行适配。实验结果表明,LingBot-VLA 相较于现有方案具有显著优势,充分验证了其卓越的性能表现与广泛的泛化能力。与此同时,我们构建了一套高效的后训练工具链,在 8 卡 GPU 配置下实现了每秒 261 个样本的吞吐量,较现有 VLA 代码库提升了 1.5 至 2.8 倍(具体取决于所依赖的 VLM 基座模型)。上述特性使该模型能够充分满足实机部署需求。为推动机器人学习领域的持续发展,我们开源了全部代码、基座模型及评测基准数据,旨在为更具挑战性的任务研究提供支撑,并促进领域内评估标准的规范化建设。
真机 Scaling Law
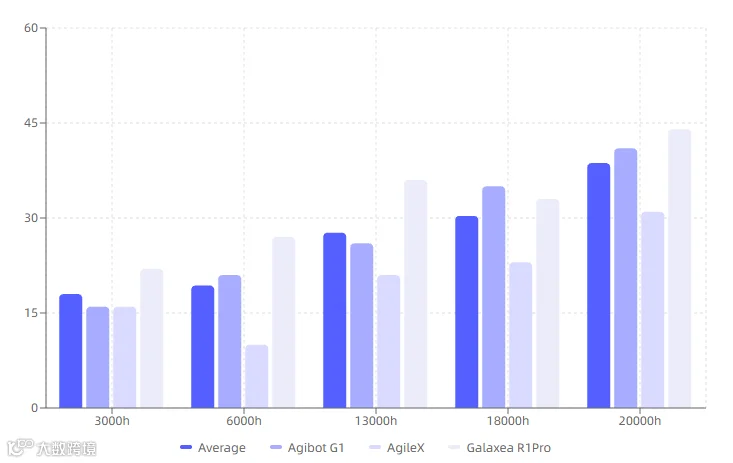 基于在海量的真实世界数据上的预训练,第一次系统研究了 VLA 模型在真实机器人任务性能上随着数据规模增长时的 scaling law。该项目发现随着预训练数据规模从 3,000 小时扩展到 6,000、13,000、18,000,最终至20,000 小时,模型在下游任务的成功率获得持续且显著的提升。值得注意的是,预训练数据量达到 20,000 小时时,模型性能仍呈现上升趋势,表明 VLA 的性能仍然能够随着数据量的增加而提升。这些实验结果证明了 VLA 模型在用真实数据预训练时呈现了良好的可扩展性,为未来的 VLA 开发和大规模数据挖掘提供了重要启示。
基于在海量的真实世界数据上的预训练,第一次系统研究了 VLA 模型在真实机器人任务性能上随着数据规模增长时的 scaling law。该项目发现随着预训练数据规模从 3,000 小时扩展到 6,000、13,000、18,000,最终至20,000 小时,模型在下游任务的成功率获得持续且显著的提升。值得注意的是,预训练数据量达到 20,000 小时时,模型性能仍呈现上升趋势,表明 VLA 的性能仍然能够随着数据量的增加而提升。这些实验结果证明了 VLA 模型在用真实数据预训练时呈现了良好的可扩展性,为未来的 VLA 开发和大规模数据挖掘提供了重要启示。
大规模数据管理和高效训练代码库

论文精心收集了 20,000 小时的真实机器人训练数据,涵盖九种主流双臂机器人。为了确保标注的精确性,我们手动将视频分割成原子动作,并使用 VLM 工具标注全局和子任务描述。我们的代码库集成了多项高级优化技术,包括全分片数据并行 (FSDP)、混合精度训练和算子融合。海量高质量数据与高效训练基础设施的结合,是 LingBot-VLA 卓越性能的基石。
实验
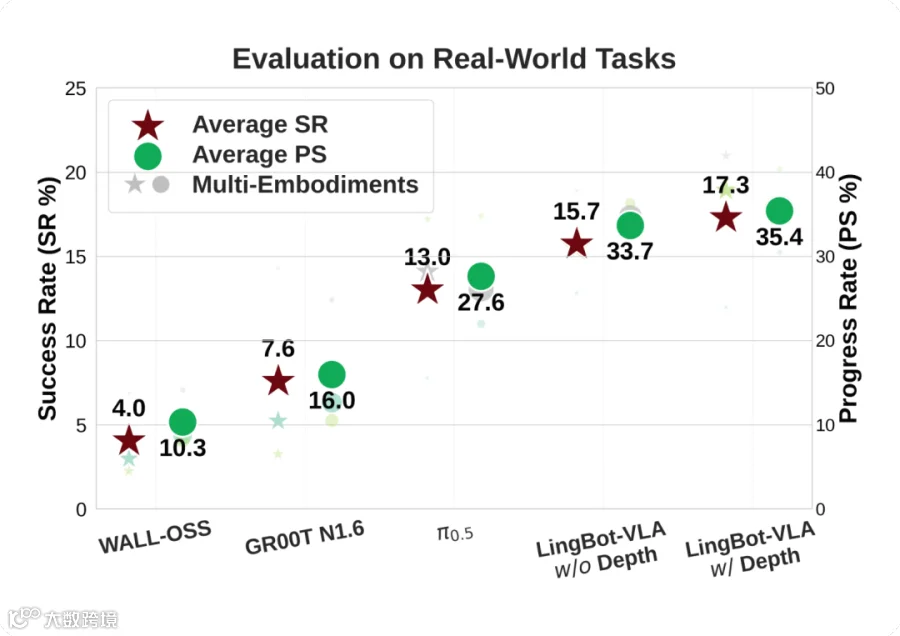 对多种机器人模型进行了广泛的实际应用验证,包括 Agibot G1、AgileX 和 Galaxea R1Pro:每个模型在每种机器人模型上均进行了 100 项任务的评估,每项任务收集了 130 条轨迹用于模型训练。实验结果表明,LingBot-VLA 的性能显著优于现有的 VLA 基线模型,展现出更高的准确率和更强的泛化能力。
对多种机器人模型进行了广泛的实际应用验证,包括 Agibot G1、AgileX 和 Galaxea R1Pro:每个模型在每种机器人模型上均进行了 100 项任务的评估,每项任务收集了 130 条轨迹用于模型训练。实验结果表明,LingBot-VLA 的性能显著优于现有的 VLA 基线模型,展现出更高的准确率和更强的泛化能力。
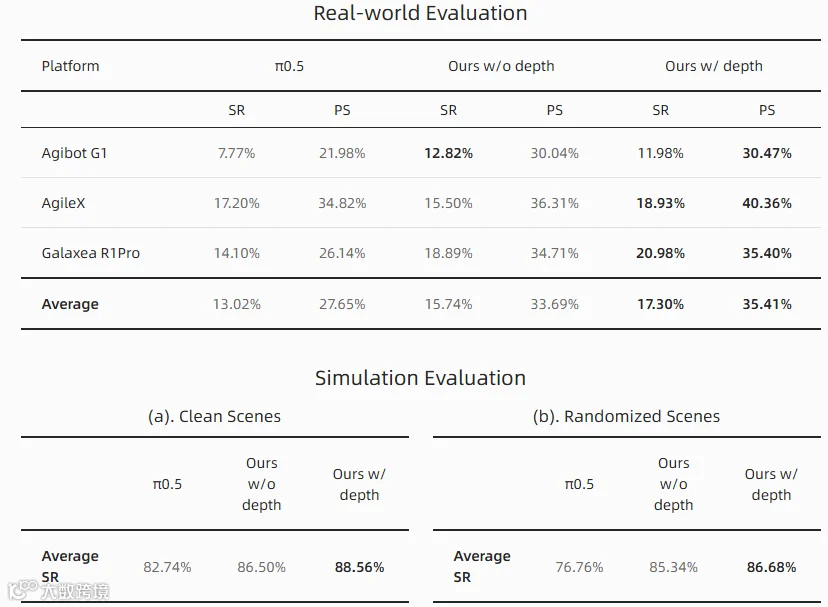 为了显式捕捉操控环境中的空间感知能力,并进一步提升机器人执行的鲁棒性,我们采用了一种基于查询向量(query)的深度蒸馏方法。具体而言,我们引入了与三视角操作图像相对应的可学习 queries,这些 queries 经 VLM 处理后,与 LingBot-Depth 输出的 depth embeddings 进行对齐。这种对齐机制在维持模型训练与推理的效率的同时,有效将深度信息集成到 LingBot-VLA 中。在真实机器人平台和仿真环境下进行的广泛实验证明,深度信息的融入提升了 LingBot-VLA 的操控性能。
为了显式捕捉操控环境中的空间感知能力,并进一步提升机器人执行的鲁棒性,我们采用了一种基于查询向量(query)的深度蒸馏方法。具体而言,我们引入了与三视角操作图像相对应的可学习 queries,这些 queries 经 VLM 处理后,与 LingBot-Depth 输出的 depth embeddings 进行对齐。这种对齐机制在维持模型训练与推理的效率的同时,有效将深度信息集成到 LingBot-VLA 中。在真实机器人平台和仿真环境下进行的广泛实验证明,深度信息的融入提升了 LingBot-VLA 的操控性能。
结论
LingBot-VLA 的研究为具身智能领域带来重要启示,其“大规模真实数据”“解耦与融合”“极致的工程效率”三大特点,证明了具身领域存在强大的 Scaling Law 且上限极高,通过 MoT 架构平衡语义理解与动作控制,解决了跨模态干扰难题,同时提升了训练效率。该模型开源代码、模型和基准数据,为全球开发者提供了高性能且易于上手的“务实”起点,推动具身智能竞争从“比 Demo”转向“比底座”。
感谢你看到这里,添加小助手 AIGC_Tech 加入官方 AIGC读者交流群,下方扫码加入 AIGC Studio 星球,获取前沿AI应用、AIGC实践教程、大厂面试经验、AI学习路线以及IT类入门到精通学习资料等,欢迎一起交流学习💗~
