

向AI转型的程序员都关注公众号 机器学习AI算法工程
工业质检领域长期面临一个核心问题:缺陷数据稀缺。划痕、裂纹等缺陷属于小概率事件,产线往往需要积累数月的真实数据才能满足模型训练需求,且专业标注成本较高。
2026年4月发布的论文SynSur(https://arxiv.org/abs/2604.26633)提出了一种端到端的工业表面缺陷生成与检测管线,通过合成数据与真实数据结合,辅助提升缺陷检测效果。
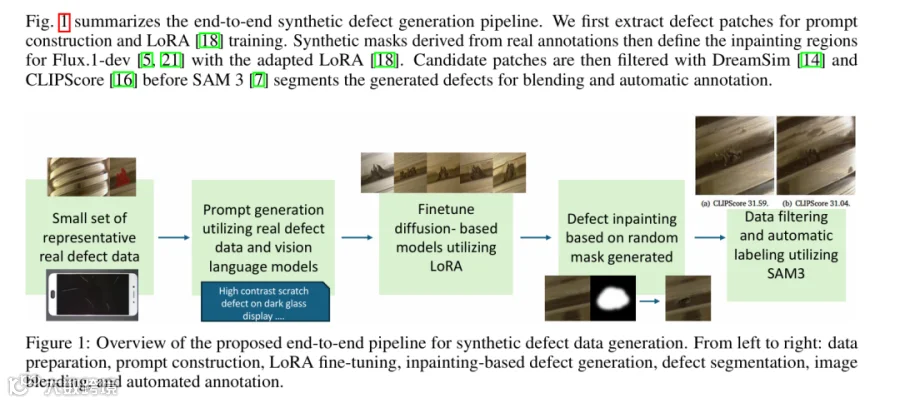
该研究的核心思路:利用视觉语言模型提示、LoRA适配的扩散模型、掩码引导修复等技术,自动生成带标注的缺陷样本,降低对大规模真实标注数据的依赖。
一、SynSur管线:生成与检测的一体化流程
传统工业缺陷检测流程为:采集真实缺陷图像→人工标注→训练检测模型。当真实数据不足时,模型性能往往受限。
SynSur提出的管线流程为:生成缺陷图像→自动标注→训练检测模型,且生成与检测环节采用端到端评估,可快速定位管线中的问题节点。
整个管线包含4个核心步骤:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
二、核心创新:解决缺陷数据稀缺的三项技术
1. LoRA适配扩散模型:轻量微调降低训练成本
传统方法需要全量微调大模型以生成特定缺陷,计算成本较高。SynSur采用LoRA(低秩适配)技术,仅训练不到1%的模型参数,即可将通用扩散模型适配为专用工业缺陷生成器,训练耗时显著缩短。
类比说明:如同让一位通用画家通过少量缺陷样本,快速掌握特定缺陷的绘制方法,无需重新学习全部绘画技能。
2. 掩码引导修复:精准控制缺陷生成区域
通用生成模型可能改变图像整体内容,导致生成样本与真实场景差异较大。SynSur通过掩码(Mask)指定缺陷位置,仅在目标区域生成缺陷内容,保持背景区域与原始图像一致,提升生成样本的真实感。
3. 自动过滤与标注:降低人工介入程度
生成样本存在质量差异,SynSur采用两项指标进行自动筛选:
- DreamSim
:计算生成图像与真实图像的相似度,过滤低相似度样本 - CLIPScore
:计算生成图像与缺陷提示的匹配度,过滤语义不匹配样本
过滤后自动标注缺陷位置信息,减少人工标注工作量。

技术要点:
SynSur实现了从缺陷生成、质量过滤到标注的全流程自动化,人工介入程度较低。
三、技术原理:生成与检测的协同优化
SynSur的管线设计类似“生成+质检”的一体化流程:

管线的核心特点是端到端评估:生成样本的质量直接通过检测模型的性能进行验证,无需单独评估生成环节,实现两个环节的协同优化。

四、实验结果与发现
论文在滚珠丝杠点蚀缺陷数据集和手机屏幕缺陷数据集(MSD)上进行了实验,主要发现如下:
1. 纯合成数据训练效果有限
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
实验表明:合成数据不能完全替代真实数据,但可作为有效补充。
2. 合成数据与真实数据结合的效果
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
在真实数据较少的场景下,加入合成数据可带来一定提升。例如仅使用10张真实缺陷图像时,加入合成数据可使mAP提升3-5个百分点。
3. 跨域适用性验证
将SynSur管线应用于MSD手机屏幕缺陷数据集,无需大幅调整结构即可适配,证明该管线可推广至不同工业检测场景。

五、实战代码:基于扩散模型的缺陷生成示例
虽然论文官方代码尚未开源,但可使用Hugging Face的扩散模型实现类似的缺陷生成功能:

如需训练专用缺陷生成器,可采用LoRA微调方案:

六、应用价值与适用场景
SynSur管线可应用于以下工业场景:
- 工业零件质检
:滚珠丝杠、轴承、手机屏幕等产品的缺陷检测 - 小样本缺陷检测
:罕见缺陷或新产品的早期质检环节 - 跨产线数据适配
:同一类型缺陷在不同产线场景下的模型适配
需注意:合成数据的作用是补充真实数据,而非完全替代。在真实数据充足的场景下,增益相对有限。
阅读过本文的人还看了以下文章:
整理开源的中文大语言模型,以规模较小、可私有化部署、训练成本较低的模型为主
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx
