
鹭羽 发自 凹非寺
量子位 | 公众号 QbitAI
Scaling即一切?智谱团队坦言在技术扩展中面临严峻挑战。
团队透露,其推理基础设施正承受前所未有的高负载压力。

智谱最新技术博客一改往日硬核风格,聚焦自GLM-5系列模型上线以来的系统性瓶颈,官方定义为「Scaling Pain」。
我们的推理基础设施持续服务数亿次Coding Agent调用,每日均面临高强度负载。
近期用户反馈,在GLM-5模型执行复杂Coding Agent任务时,出现乱码、内容复读及异常字符生成等问题。
值得注意的是,这些故障在标准测试环境下无法复现。

经数周深度排查,团队锁定问题根源,揭示了Scaling进程中的关键系统缺陷。
报告不仅系统总结了实践经验,更提出可落地的优化方案。
对于计划部署高并发Agent系统的开发者而言,此案例具有重要参考价值。

核心故障定位
自GLM-5发布后,团队监测到三类典型异常:
- 乱码输出:内容逻辑混乱无意义;
- 重复生成:模型持续输出相同内容;
- 生僻字符:生成非预期特殊符号。
通过数百次本地请求回放,团队确认问题非模型本身导致。在模拟高负载环境并调整PD分离参数后,异常复现率约为万分之三至五,指向推理状态管理机制存在隐患。
为提升检测精度,团队创新性引入投机采样(Speculative Decoding)指标:
乱码及生僻字符现象对应低spec_accept_length,反映KV缓存状态与草稿模型失配;复读问题则表现为高spec_accept_length,表明缓存损坏引注意力机制退化。
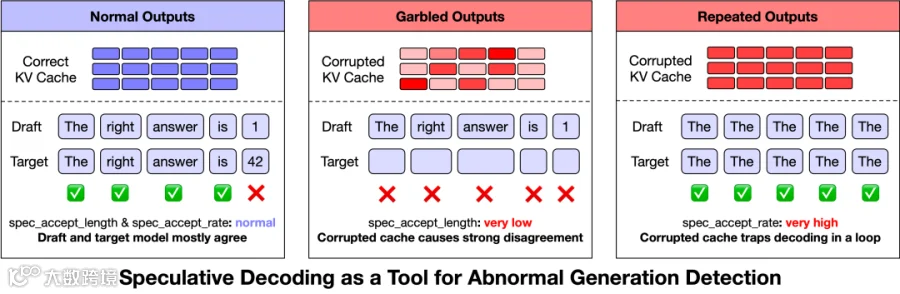
基于此,团队制定在线监控策略:当spec_accept_length持续低于1.4且生成长度超128 token,或spec_accept_rate超过0.96时,系统将中止当前任务并触发负载均衡调度。
深度分析揭示两大根本原因:
PD分离架构下的KV Cache竞态
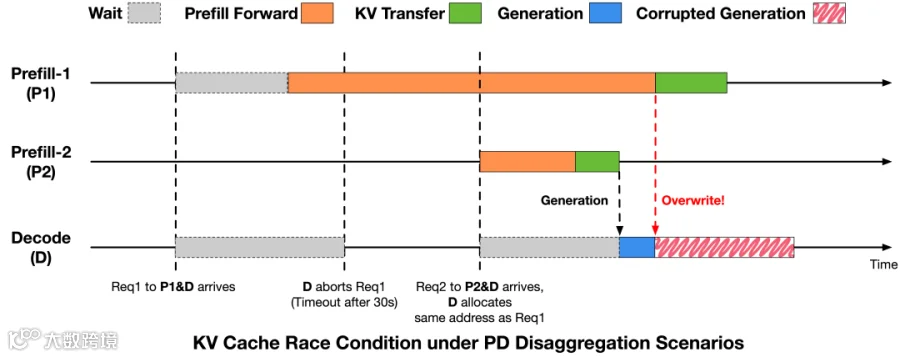
问题源于请求生命周期与KV Cache回收时序不一致,导致跨请求缓存冲突。
解决方案是在推理引擎中建立显式同步机制:预填充阶段仅在未启动RDMA写入或所有写入完成时,才向解码阶段返回安全信号;解码阶段收到确认后方可复用缓存槽位。该机制确保缓存写入边界明确,避免状态污染,使异常发生率从万分之十几降至万分之三以下。
HiCache加载时序缺失
缓存换入与计算重叠时,存在未就绪数据被访问风险。
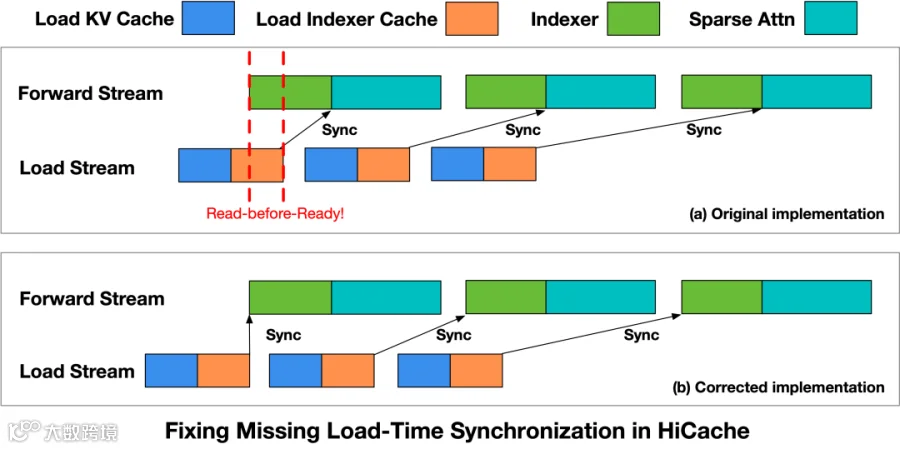
团队重构了HiCache读取流程,关键是在Indexer算子启动前插入Load Stream同步点。Forward Stream仅在缓存数据准备完毕后执行计算,彻底解决read-before-ready问题。修复后,时序相关异常完全消除,系统稳定性显著提升。
Prefill阶段优化方案
上述问题凸显Prefill阶段已成为高并发Coding Agent场景的核心瓶颈。为缓解内存与带宽压力,团队提出分层缓存存储方案——LayerSplit。
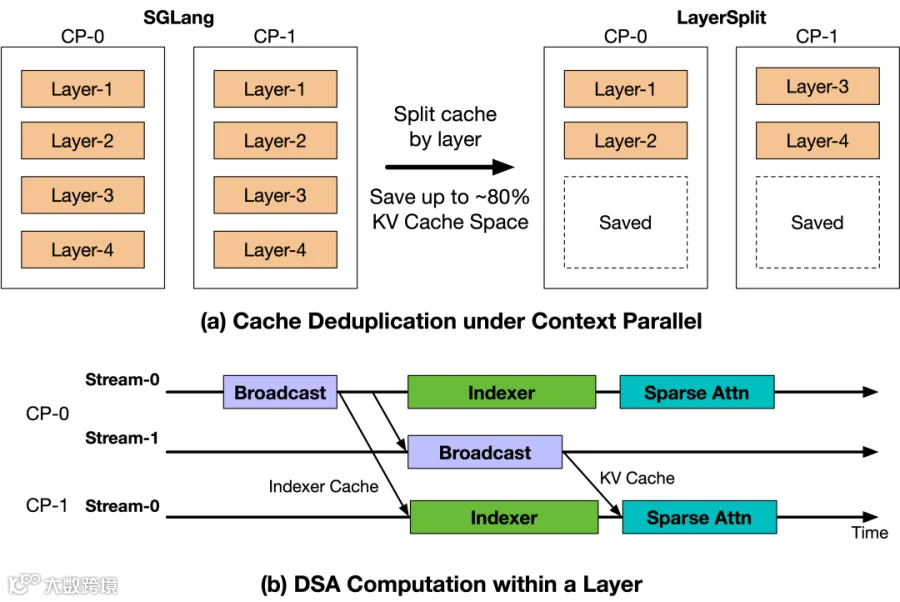
该方案要求每GPU仅存储部分层的KV Cache,大幅降低单设备内存占用。Attention计算前,通过跨rank广播机制获取对应层缓存,并采用通信-计算重叠设计将传输延迟隐藏于计算流程中。Indexer Cache广播开销仅占KV Cache八分之一,整体影响可忽略。
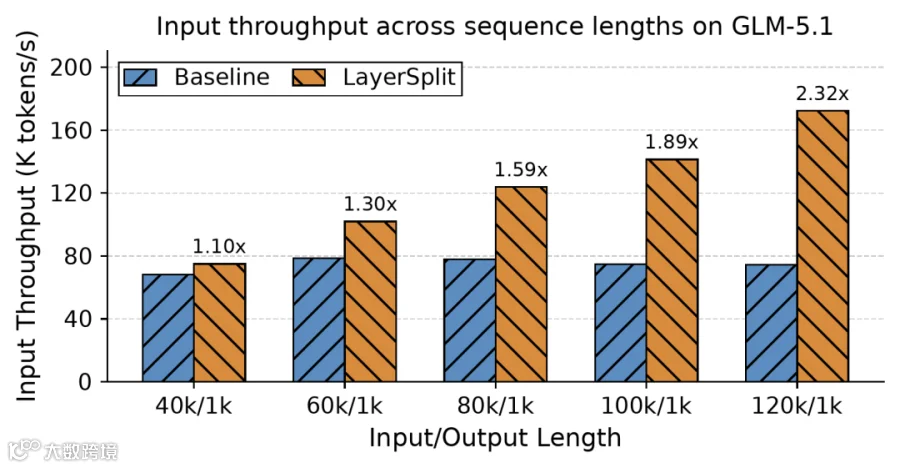
LayerSplit与GLM-5.1结合测试表明:当缓存命中率达90%且请求长度介于40k-120k时,系统吞吐量提升10%-132%,且上下文越长增益越显著。该优化有效强化了Coding Agent场景的实时处理能力。
智谱强调,随着AI进入高并发、长上下文应用场景,系统工程支撑与Scaling Law能力增长同等重要。未来大规模AI部署必须兼顾理论提升与基础设施健壮性。
参考链接:
https://z.ai/blog/scaling-pain
[2]https://www.zhipuai.cn/zh/research/159