
DeepSeek发布“以视觉原语思考”多模态推理模型
DeepSeek近日在GitHub发布多模态推理模型及技术报告《以视觉原语思考》。该模型基于DeepSeek V4-Flash构建(总参数2840亿,推理时激活130亿参数的混合专家架构),提出全新多模态推理范式。

论文指出当前模型存在“指代鸿沟”根本瓶颈:模型虽能识别图像内容,但用自然语言构建思维链时,类似“左边红色物体”的模糊描述难以精确定位对象,导致注意力漂移和错误结论。此前学界主攻提升感知分辨率,但论文强调“看见”与“精准指代”实为两回事。

核心创新:视觉原语融入推理链
模型将点坐标和边界框嵌入推理过程,作为思维链基本单元。推理时每提及视觉对象同步输出坐标,例如“找到一只熊[452,23,804,411],正在爬树;排除后左下[50,447,647,771],立岩石边缘”。坐标成为空间锚点而非事后标注,有效消除歧义。
高效视觉压缩架构
模型实现7056倍视觉压缩:756×756图像经ViT处理生成2916个图像块token,通过3×3空间压缩合并为324个,再经压缩稀疏注意力机制进一步压缩4倍,最终仅需81个视觉KV条目。相较而言,同等尺寸图片Claude Sonnet 4.6需870个、Gemini-3-Flash需1100个。
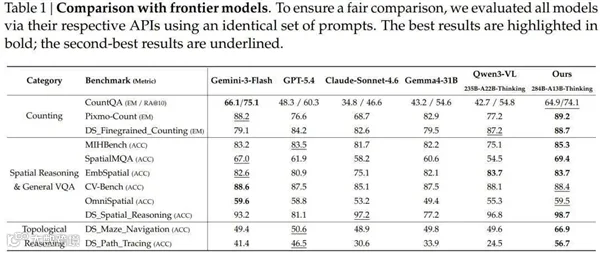
训练数据整合近10万个目标检测集,精选3.17万高质量源生成4000万样本,覆盖计数、空间推理、迷宫导航和路径追踪任务。后训练采用先专家化、后统一策略:分别优化边界框和点坐标模型,经强化学习后通过在线策略蒸馏合并。
基准测试表现优异
在11项基准测试中全面领先:计数任务精确匹配达89.2%,超过Gemini-3-Flash的88.2%及GPT-5.4的76.6%;迷宫导航得分66.9%,较GPT-5.4(50.6%)提升17个百分点;路径追踪56.7%,显著优于GPT-5.4的46.5%。
论文同时指出当前局限性:模型需明确触发词启动视觉原语机制,极细粒度场景下坐标精度不足,跨场景泛化能力仍需加强。

