




几个月前他突然说,自己作为程序员从未感到如此落后。
他特别强调了一点:很多人对 AI 编程的印象还停在 2024 年的体验,但 12 月之后必须重新看一次,因为 agentic 的连贯工作流开始真正成立了。

顺着这个体验,Stephanie 问到了他那套经典的软件版本划分。
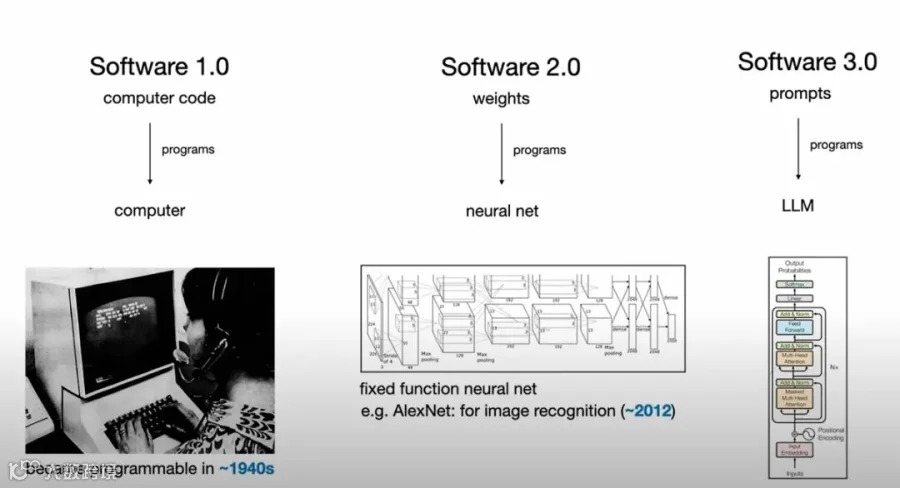
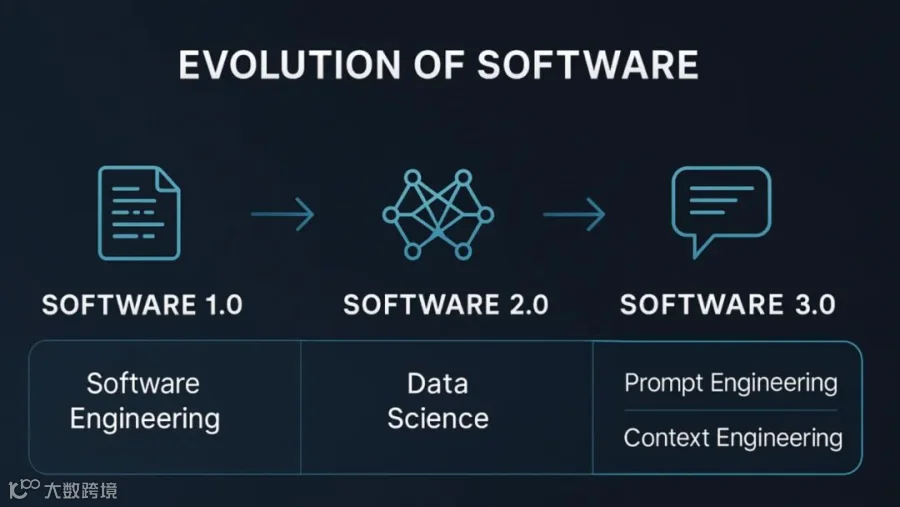
他用 OpenClaw 的安装方式来说明这不止是概念。正常你会写复杂的 shell 脚本来适配不同平台,但 OpenClaw 的安装现在就是一段让你复制粘贴给 agent 的文本。

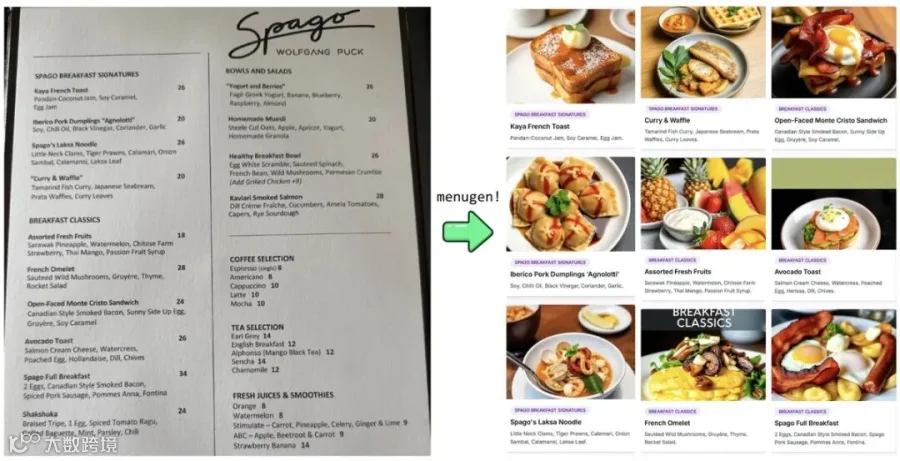
他当场评价自己写的 MenuGen 根本就不该存在,那是旧范式的产物。

当被问到这个问题时,Karpathy 的推测非常极端。


Stephanie 之所以问到可验证性,是因为 Karpathy 之前专门写过这个话题。他在对谈里把前因后果讲得比文章里更细。
他的逻辑起点是这样一组对比:传统计算机能自动化的事情,是你能用代码精确描述的事。
为什么是可验证性?
这就导致了一个他反复提到的现象——锯齿状智能。他在对谈里举了两个例子来说明这种锯齿有多离谱。
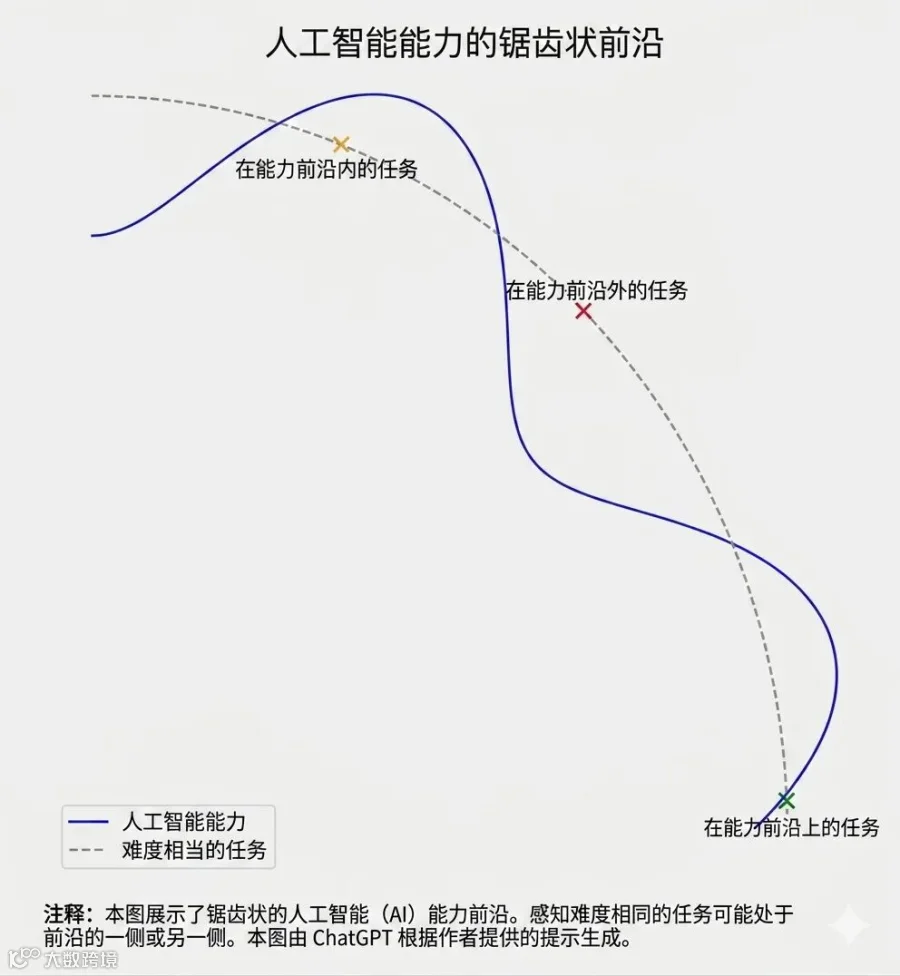
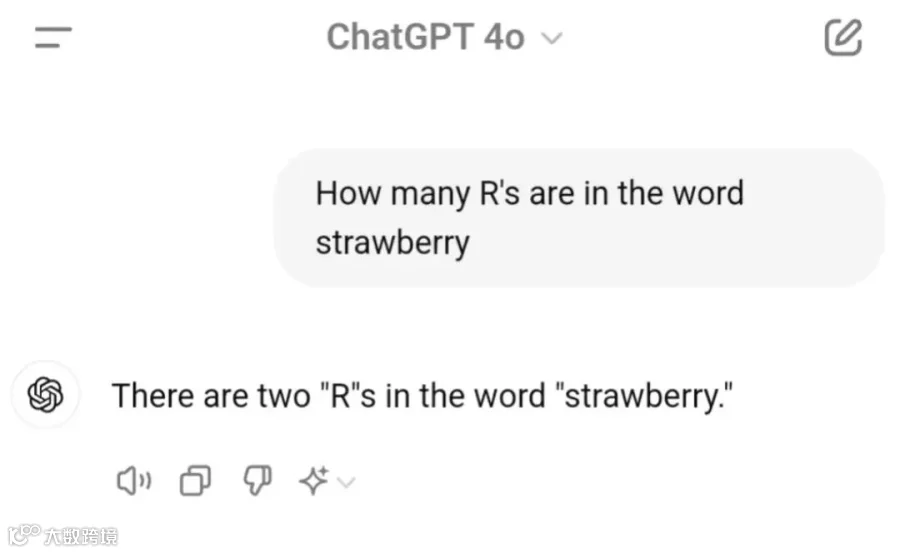
第一个例子他笑称为经典款:
他的第二个例子更贴近日常生活:五十米外有个洗车店,你应该开车去还是走路去?

Karpathy 对这个现象的解释并不仅仅是理论推演。
这个细节非常关键,因为它直接指向了他对在场创业者和工程师的核心提醒:一个模型在某个领域强,不代表它在你的领域也强。
他还补充了一点对创始人有实操意义的观察:可验证性这件事不止对实验室有用。

接着话题转到了 vibe coding 和 agentic engineering 的区别。
在招聘上他的建议也直接。

关于人的价值还剩下什么,Karpathy 用一条他反复回味的推文做了总结:你可以外包思考,但外包不了理解。
在 MenuGen 的用户系统里,agent 曾经拿 Stripe 邮箱和 Google 登录邮箱去交叉匹配账户资金,任何有经验的工程师都知道这两个邮箱可以完全不同,不能当用户 ID 用。

整场对话最核心的比喻在最后。
本文整理自红杉资本 AI Ascent 2026 上 Andrej Karpathy 与 Stephanie Zhan 的对谈,内容有删节和重组。

