

让大模型学会边指边想
作者 | 陈骏达
编辑 | 心缘
智东西4月30日报道,DeepSeek发布多模态技术报告《用视觉原语思考(Thinking with Visual Primitives)》,详解其灰度上线的识图模式核心技术。

284B参数多模态推理模型
DeepSeek识图模式基于一个284B参数、13B激活的多模态推理模型,基座为DeepSeek-V4-Flash。该模型权重将整合进DeepSeek基础模型,并在未来正式发布。
语言逻辑+空间坐标双轨思维
传统思维链局限于语言领域,而视觉推理需更强的空间感知能力。DeepSeek将纯语言推理升级为“语言逻辑+空间坐标”双轨机制:模型在分析图像时,可直接输出边界框或点坐标,在图中精准“指出”当前推理对象。
DeepSeek多模态团队负责人陈小康展示的动图显示,模型可在思维链中持续使用框选区域作为视觉锚点,并基于空间坐标推进后续判断,显著提升视觉推理准确性。

▲DeepSeek多模态模型推理过程
在多项高难度视觉问答任务中,该模型性能超越GPT-5.4、Claude-Sonnet-4.6、Gemini-3-Flash、Qwen3-VL等主流模型。
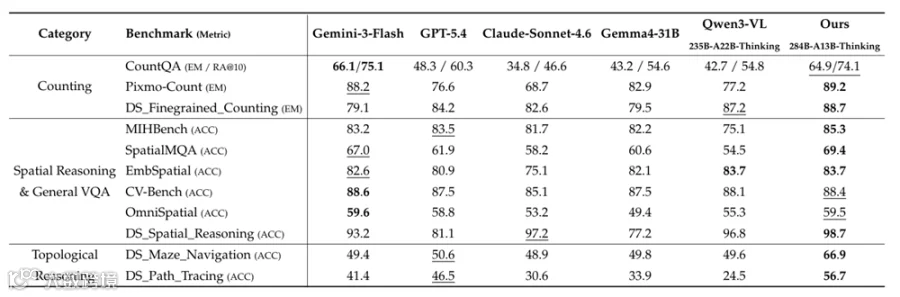
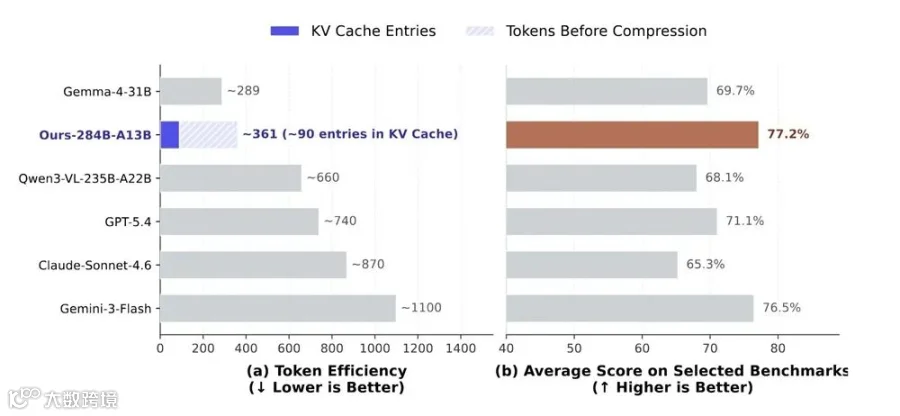
超7000倍视觉token压缩
该模型采用高效视觉编码架构:通过ViT特征提取、3×3空间压缩及稀疏注意力机制三级处理,将高分辨率图像压缩至极低维度。以756×756图像为例,原始2916个patch token最终仅保留81个视觉KV条目,压缩比达7056倍。
这一设计大幅降低计算开销,使模型在复杂空间推理中无需遍历海量像素,每一步思考更轻量、更聚焦。
自然语言存在“指代鸿沟”,视觉标记介入有望破解
当前多模态模型普遍聚焦于“感知鸿沟”——即提升图像识别精度。但DeepSeek指出,即便图像解析再精细,模型仍易在复杂视觉推理中失效。
根本症结在于自然语言固有的“指代鸿沟”:如“左边那个东西”,在密集场景中难以精确定位。由此导致思维链每步都存在偏差风险,尤其在密集计数、多步空间推理、拓扑导航等任务中逻辑易崩塌。
为此,DeepSeek提出“边想边指”范式,将点坐标与边界框作为模型思维链的基本认知单元,使视觉原语深度融入推理过程。
模型架构由DeepSeek-ViT提取图像特征,文本分词器处理指令,二者输入基座模型DeepSeek-V4-Flash融合推理,再经去分词器输出含自然语言与视觉原语(如坐标、区域标记)的联合响应,兼顾语义理解与原生定位能力。
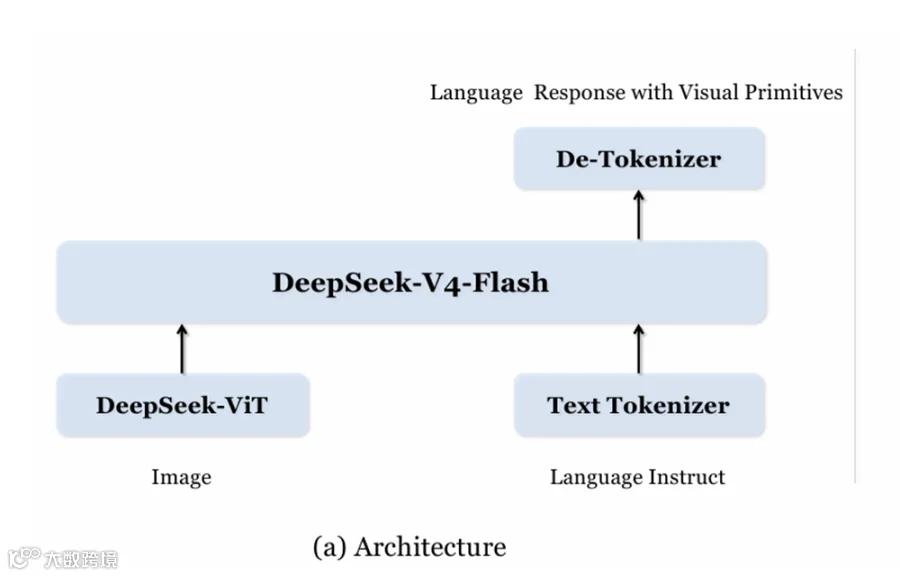
筛选超4000万个高质量样本,对四类任务针对性优化
为让模型真正掌握“指”的能力,DeepSeek构建覆盖预训练、冷启动与强化学习的完整训练流水线。
预训练阶段,团队从互联网爬取9.8万个目标检测数据源,经自动化语义与几何质量审查,剔除乱码标签、私人实体、严重截断框及覆盖全图90%的“巨型框”,最终筛选出3.17万个高质量数据源,形成超4000万精准样本,夯实基础定位能力。
冷启动阶段,团队针对计数、空间推理、迷宫导航、路径追踪四类典型任务,合成带精确思考轨迹监督的数据集。
例如计数任务中,模型被明确要求先批量框选所有候选对象,再逐一校验累加;迷宫任务则强制每步输出点坐标标记当前位置,撞墙即触发因果失效,倒逼模型建立回溯机制。

▲计数任务的一条冷启动数据
该策略将视觉原语操作直接嵌入思维链,实现“指向-推理”强耦合。
采用稠密奖励机制,视觉编码压缩比超7000倍
后训练阶段,DeepSeek采用“训练专家再融合”策略。以迷宫任务为例,奖励细分为探索进度、撞墙惩罚、路径有效性、探索完整性等多个维度——每正确移动一格得正向信号,撞墙即严格扣分,杜绝“猜答案”式投机。
为统一支持框定位与点指向两类视觉原语,团队分别训练两个专家模型,再通过在线策略蒸馏融合为单一大模型,避免异构原语训练干扰。
底层视觉编码延续前述三级压缩架构,最终实现高达7056倍的token压缩比。这种高效率编码使模型获得一份“提炼后的视觉索引”,大幅削弱无关像素对推理链路的干扰。
结语:多模态智能的“系统二”进化
报告同时指出当前局限:模型在跨场景复杂拓扑推理中的泛化能力有待提升;视觉原语激活仍依赖显式提示词,尚未实现自发调用。
但该框架为多模态智能发展提供了新路径——不盲目堆砌图像分辨率,而是构建更精准的空间参照体系。用坐标锚定抽象思维,让模型像人类一样“边指边想”,是通往系统二级别多模态智能的关键一步。




项目地址:
https://github.com/deepseek-ai/Thinking-with-Visual-Primitives
技术报告:
https://github.com/deepseek-ai/Thinking-with-Visual-Primitives/blob/main/Thinking_with_Visual_Primitives.pdf