

这是我的第427篇Ai笔记,本篇1794、累计笔记7320261
彩蛋:结尾扫描二维码,领取《DeepSeek V4 识图场景提示词地图》。

在 DeepSeek V4 正式发布仅仅 5 天后,那个一直霸占大模型热搜的蓝色小鲸鱼,悄悄睁开了眼睛。
不少用户的界面里,已经灰度上线了一个叫识图模式的新按钮。
在此之前,DeepSeek 一直以一种极度偏科的形象存在:它强于代码、精于数学、在逻辑推理和长文本里几乎无敌,但它却一直看不见世界。这次多模态能力的补齐,意味着这台强大的推理引擎,终于补上了最后一块关键拼图。

很多人觉得,AI 能看图不是什么稀罕事。毕竟早几年的 OCR 就能识字,甚至连手机相册都能自动分类照片。
但 DeepSeek 开启识图模式,这件事的深层价值不在于识图,而在于视觉推理。
过去大部分 AI 处理视觉,本质上是把图片丢给一个翻译官(OCR 模块),把图变成字,再塞给模型。这种方式下,AI 只是在读说明书,而不是在看世界。

而现在的跨越在于,视觉能力开始真正进入 AI 的推理链条。
当 AI 能理解画面中的空间关系、情绪表达和逻辑冲突时,视觉就从一个单一的功能点,变成了 AI 触碰物理世界的入口。
这不再是简单的查户口式识别,而是 AI 正在尝试用它的逻辑大脑,去理解我们所处的真实时空。这件事最值钱的地方,是它让 AI 从一个单纯的文本推理机,变成了一个能处理复杂现实问题的视觉助手。

既然有了视觉入口,肯定不能只拿它来提取文字。为了探底这只小鲸鱼的眼力边界,我们准备了 4 组带有视觉逻辑陷阱的极限测试,看看它到底只是认图,还是真的会看图。
第一组:数手指,最经典的视觉陷阱
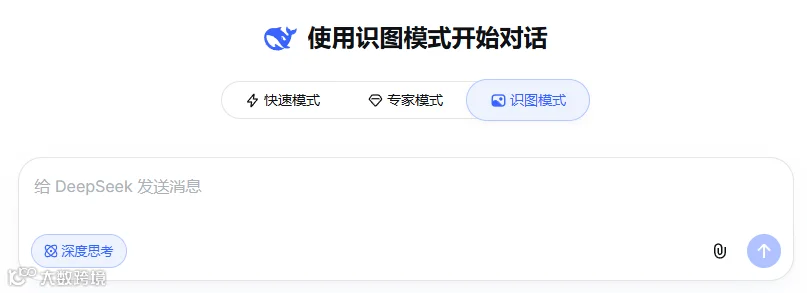
我们上传了一张非常规的手部图片,直接问它:图中有几根手指? 这类图片一直是所有大模型视觉能力的死穴。
因为 AI 往往是靠局部特征来瞎猜,而不是像人一样建立全局的空间认知。
实测结果:翻车了。图里明明有 8 根手指,它只数出来了 6 根。 这其实一直是所有视觉大模型的集体死穴。
因为 AI 往往是靠局部特征(比如看到了几个指甲盖)去瞎猜,很难像人一样迅速建立全局的空间认知。在极限的视觉逻辑上,它依然有盲区。
第二组:视错觉比大小(基础版)
我给它传了一张经典的视错觉图,问它:图中哪个橙色的小球更大? 这考的是它会不会被画面里的辅助元素骗过去。它是会像人类一样产生视觉误差,还是能剥离背景,进行纯粹的像素级像素对比?
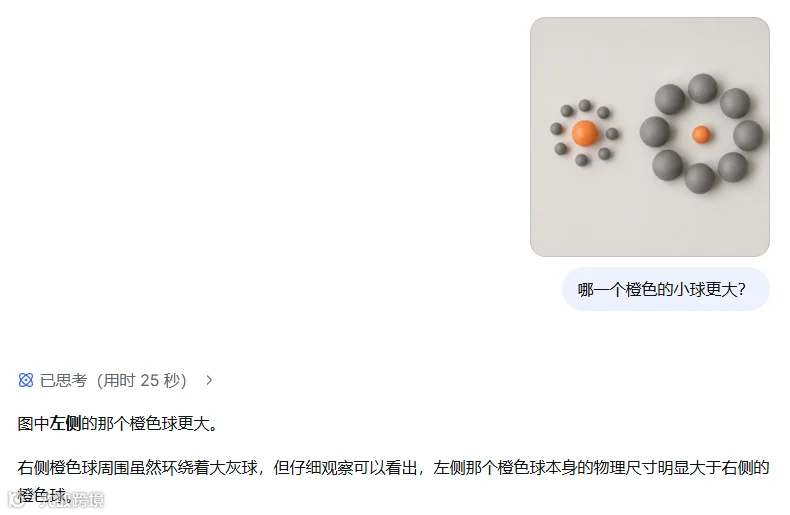
实测结果:表现非常惊艳。它不仅思考速度极快,而且精准地识别出了左边大、右边小的客观事实,完全没有被周围多余的背景元素干扰。
第三组:视错觉比大小(进阶连环套)
紧接着上一题,我们又上传了一张跟刚才高度相似、但实际比例有微调的图片,再次问它哪个橙色小球更大。
这是为了测试它的视觉鲁棒性。很多模型第一道题碰巧蒙对后,只要图片稍作变动,就会顺着上一次的逻辑产生幻觉。我们就看 DeepSeek 能不能在这个连环套里保持清醒。

实测结果:这次失败了。它似乎犯了懒,拒绝了深度思考,只用了两秒钟,就直接把上一轮的答案(左边更大)甩给了我。
这种视觉鲁棒性的缺陷挺有意思,它很容易被上下文的惯性锚定。如果新开一个对话框重新问,结果或许会完全不同,但顺着往下聊,它确实容易偷懒。
第四组:看手相,视觉与玄学的碰撞
最后一组,我们传了一张真实的手部照片,让它来看个手相。 这道题不仅考识图,更考它如何把客观的视觉特征和人类特有的玄学语境结合起来输出。

↓↓↓上下滑动查看全部↓↓↓

实测结果:有点惊喜。它不仅能针对提示词给出非常详细的内容输出,还能煞有介事地对掌纹走向进行一通解析。这种把客观视觉特征和特定文化语境结合起来的输出,对国内用户来说确实很讨喜,可玩性极高。

1. DeepSeek V4 发布 5 天就火速补齐了识图短板,迭代速度极其生猛。
2. 它的基础视觉解析很到位,连看手相、看掌纹这种细活都能接得住,作为日常图文助手完全合格。
3. 但在连环视错觉和数手指这种极限视觉逻辑上,它依然会偷懒和翻车,还没到无脑神化的地步。

我顺手整理了一份:《DeepSeek V4 识图场景提示词地图》里面不是测试题,而是我按真实行业场景拆好的使用方法。
包括零售、餐饮、电商、直播、短视频、教育培训、制造业、物业、装修、美业、HR、农业、会展、合同单据、老板巡店等 15 个方向。
每个方向都配了:适合上传什么图、应该让 DeepSeek 看什么、以及可以直接复制的提示词。

想拿去直接套用的,可以私信回复【识图地图】,即可领取。